

DeepSeek-V4-Pro: 1Mコンテキスト、LiveCodeBenchで#1、オープンソースの最前線
あなたはプロダクションのコーディングエージェント向けにオープンソースモデルを評価しています。単一ファイルだけでなく、リポジトリ全体を扱える大規模コードベースを処理し、ツール呼び出しを幻覚することなく実際のGitHub Issueを解決できるモデルが必要です。これまで試したモデルは、128Kトークンを超えると性能が低下するか、実際のエンジニアリングタスクで重要なベンチマークでGPT-4oに遅れをとっていました。
DeepSeek-V4-Proはこの状況を変えます。1.6兆パラメータのMoEモデルで、真の1Mトークンコンテキストウィンドウ、LiveCodeBenchで最高スコア(93.5 Pass@1)、Codeforcesレーティング3206を達成。これらはすべて評価対象モデル(クローズドフロンティアAPIを含む)の中で#1です。要するに、競技コーディングと大規模コンテキストエージェントタスクにおいて、現在利用可能な最良のオープンソースモデルであり、MITライセンスでリリースされています。本日より、Novita AIから利用可能です。
DeepSeek-V4-Proとは?
DeepSeek-V4-Proは、2026年4月24日にリリースされたDeepSeekのV4シリーズのフラッグシップモデルです。軽量版のDeepSeek-V4-Flash(総パラメータ284B / アクティブ13B)の上位に位置し、DeepSeekの現在のフロンティア能力のプレビューとして位置づけられています。同社は知識とコーディングにおいて「現在利用可能な最良のオープンソースモデル」と説明しています。このモデルは32兆トークン以上でトレーニングされ、2段階のパイプライン(ドメインエキスパートSFT + GRPO強化学習、続いてオンポリシー蒸留)でファインチューニングされています。技術詳細はDeepSeekの論文 DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence に記載されています。
主な仕様は以下の通りです。
- アーキテクチャ: Mixture-of-Experts (MoE) with Hybrid Attention — Compressed Sparse Attention (CSA) + Heavily Compressed Attention (HCA)
- パラメータ: 総数1.6T / フォワードパスあたりアクティブ49B
- コンテキストウィンドウ: 1,048,576トークン (1M)
- 精度: FP4 (MoEエキスパート) + FP8混合
- 推論モード: Non-think (高速), Think (標準CoT), Max (最大推論予算)
- 機能: 関数呼び出し、構造化出力、推論、1Mコンテキスト検索
- ライセンス: MIT
主な機能
効率的な1MトークンコンテキストのためのHybrid Attention
「長いコンテキスト」を謳うほとんどのモデルは、静かに切り詰めるか、128Kトークンを超えると急激に性能が低下します。DeepSeek-V4-ProのHybrid Attention Architectureは、Compressed Sparse Attention (CSA) と Heavily Compressed Attention (HCA) に加え、Manifold-Constrained Hyper-Connections (mHC) を組み合わせ、効率的な百万トークン処理のためにゼロから設計されています。実際の性能: MRCR 1Mで83.5(1Mコンテキスト全体でのメモリ想起)、CorpusQA 1Mで62.0を達成し、フルウィンドウ全体で一貫した推論を維持します。コードベース全体、1日分のログ、または書籍一冊分のドキュメントを1回の呼び出しで取り込む必要があるエージェントにとって、このアーキテクチャは特別なインフラなしでそれを実現可能にします。
LiveCodeBenchとCodeforcesで#1 — 実際に競争力のあるコーディングモデル
DeepSeek-V4-ProはLiveCodeBenchで93.5(Pass@1)、Codeforcesレーティングで3206を記録。どちらも比較表の中で最高スコアであり、Claude Opus 4.6 Max(88.8 / レーティングなし)、Gemini 3.1 Pro High(91.7 / 3052)、GPT-5.4 xHigh(LCBスコアなし / 3168)を上回っています。SWE-Verified(実際のGitHub Issue解決)では80.6を達成し、Claude Opus 4.6 Max(80.8)やGemini 3.1 Pro(80.6)と同等です。「実際にバグを修正できるか」が理論的なMMLUスコアよりも重要なコーディングエージェントを構築するチームにとって、V4-ProはクローズドフロンティアAPIと直接競合するオープンソースの選択肢です。
3つの推論モード — タスクに応じて計算リソースを調整
DeepSeek-V4-Proは同じAPIエンドポイントを通じて3つの推論モードを提供します。
- Non-think: チェーン・オブ・ソートなし。高速、低レイテンシ。分類、抽出、構造化出力タスクなど、推論のオーバーヘッドが無駄になる場合に適しています。
- Think: 標準的なCoT推論。コーディング、数学、マルチステップタスクのデフォルト。
- Max (V4-Pro Max): 拡張推論予算。速度よりも精度が重要な場合に使用 — 複雑な証明、難しい競技プログラミング問題、深いデバッグセッション。
3つのモードはすべて、Novita AIがバックエンドのdeepseek/deepseek-v4-proモデルIDでアクセス可能です。モードの切り替えはプロンプトレベルの指示であり、異なるエンドポイントではありません。つまり、アプリケーションでAPI設定を変更することなく、適応的なモード選択を実装できます。
エージェントおよびツール使用のパフォーマンス
コーディングベンチマーク以外でも、V4-Proはエージェント評価で健闘しています。BrowseComp: 83.4(Claude Opus 83.7、Gemini 85.9 — フロンティアとの差2.5ポイント以内)。MCPAtlas Public: 73.6、Claude Opus 4.6(73.8)に次ぐ2位。Toolathlon: 51.8、全体3位。これらは「全モデルをリード」する結果ではありませんが、V4-Proがベンチマーク最適化されたコーディング専門家ではなく、有能な汎用エージェントモデルであることを確認しています。ネイティブの関数呼び出しサポートと組み合わせることで、ブラウジング、ツール呼び出し、推論を1セッションで行うエージェントに実用的な選択肢となります。
ベンチマークパフォーマンス
以下の表は、DeepSeekの公式比較からのベンチマークです。「V4-Pro」はDeepSeek-V4-Pro Max(拡張推論)モードを指します。これはNovitaのdeepseek/deepseek-v4-pro API IDでアクセス可能な同じモデルです。
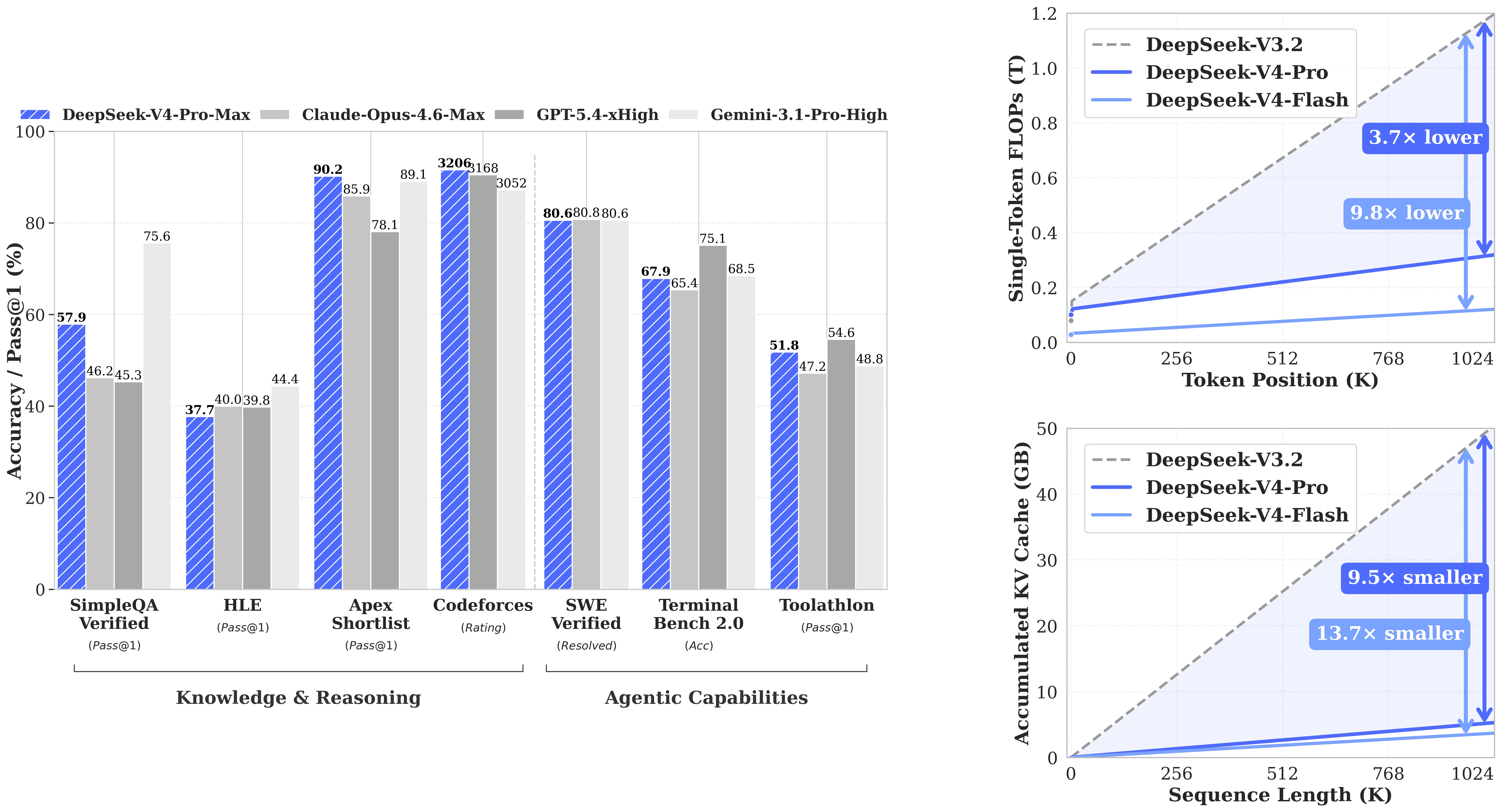
DeepSeek-V4-Proのコーディング、推論、エージェントベンチマークにおけるパフォーマンス。[出典: DeepSeek HuggingFace]
| ベンチマーク | DeepSeek-V4-Pro | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 93.5 ✓ | 88.8 | 91.7 | — |
| Codeforces Rating | 3206 ✓ | — | 3052 | 3168 |
| SWE-Verified | 80.6 | 80.8 | 80.6 | — |
| SWE Pro | 55.4 | 57.3 | 54.2 | 57.7 |
| BrowseComp | 83.4 | 83.7 | 85.9 | 82.7 |
| MCPAtlas Public | 73.6 | 73.8 | 69.2 | 67.2 |
| GPQA Diamond | 90.1 | 91.3 | 94.3 | 93.0 |
| HLE (Pass@1) | 37.7 | 40.0 | 44.4 | 39.8 |
| IMOAnswerBench | 89.8 | 75.3 | 81.0 | 91.4 |
| HMMT 2026 Feb | 95.2 | 96.2 | 94.7 | 97.7 |
| MRCR 1M (MMR) | 83.5 | 92.9 | 76.3 | — |
| CorpusQA 1M | 62.0 | 71.7 | 53.8 | — |
| Terminal Bench 2.0 | 67.9 | 65.4 | 68.5 | 75.1 |
✓ = この比較における最高公表スコア。最終確認: 2026-04-25。スコアは該当する場合「Max」/拡張推論モードを反映。出典: DeepSeek HuggingFace model card。
正直な評価: 知識ベンチマーク(GPQA Diamond、HLE)では、Gemini 3.1 ProとGPT-5.4が明らかにリードしています。V4-Proの強みはコーディング(LiveCodeBenchとCodeforcesで明確な#1スコア)と、他のオープンソースモデルに対する長文脈検索にあります。数学的推論では、差はまちまちです。V4-ProはIMOAnswerBenchでGPT-5.4を上回りますが(89.8 vs 91.4、僅差)、HMMT 2026では劣ります(95.2 vs 97.7)。
Novita AIがバックエンドのDeepSeek-V4-Proの使い方
オプション1: プレイグラウンド(コード不要)
novita.ai/models/model-detail/deepseek-deepseek-v4-pro で直接テストできます。探索にAPIキーは不要です。システムプロンプトを設定してThinkモードまたはNon-thinkモードを有効にします。
オプション2: API(Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
# 標準(Thinkモード)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-pro",
messages=[
{"role": "user", "content": "Rustの非同期ランタイムをゼロから実装してください。"}
],
)
print(response.choices[0].message.content)
APIキーは novita.ai/settings で取得してください。同じモデルIDが3つの推論モードすべてで機能します。モードの指示はシステムプロンプトに渡すか、DeepSeekのドキュメントに記載されたモード切り替え構文を使用します。
オプション3: サードパーティツール
Novita AIはOpenAI API互換であるため、Cursor(カスタムOpenAIプロバイダー)、Claude Code互換セットアップ、LangChain、LlamaIndex、またはOpenAI SDKベースのフレームワークで、モデルIDとしてdeepseek/deepseek-v4-proを指定するだけです。base_urlをhttps://api.novita.ai/v3/openaiに設定してください。
curl https://api.novita.ai/v3/openai/chat/completions \\
-H "Authorization: Bearer YOUR_NOVITA_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{"model":"deepseek/deepseek-v4-pro","messages":[{"role":"user","content":"Rustの非同期ランタイムを実装してください。"}]}'
ユースケース
コードベース全体の分析とリファクタリング: 1Mトークンのコンテキストがあれば、中規模のリポジトリ全体を1回の呼び出しで渡せます。V4-Proにアーキテクチャ上の問題の発見、移行ガイドの生成、50以上のファイルにわたるパターンのリファクタリングを依頼できます。チャンク化や検索のハックは不要です。
競技プログラミングと難しいアルゴリズム問題: Codeforcesレーティング3206は、V4-Proをアルゴリズム問題解決のトップ層に位置づけます。競技プログラミングの課題の解決策生成、複雑性の証明の検証、プロダクションアルゴリズムのエッジケースのストレステストに使用できます。
GitHub Issue解決エージェント: SWE-Verified 80.6は、V4-Proが実際のバグ修正においてClaude Opus 4.6と同等であることを示しています。関数呼び出しと長いコンテキストを組み合わせることで、Issueの説明を読み、コード履歴を参照し、大規模リポジトリでも見失うことなくパッチを生成できます。
長文書の推論: 法的契約書、研究論文、技術仕様書、監査ログなど。V4-Proの1Mコンテキストにより、分析前に要約やチャンク化を強制されることはありません。CorpusQA 1M(62.0)とMRCR 1M(83.5)は、フルコンテキスト長でも検索精度が維持されることを確認しています。
数学・科学のチュータリング / 問題生成: IMOAnswerBench 89.8(GPT-5.4の91.4を除くすべてのクローズドモデルを上回る)は、V4-Proを競技レベルの数学問題の生成、証明の検証、数学的推論がボトルネックとなるSTEM教育ツールの構築に強力な選択肢としています。
料金
| モデル | 入力 ($/Mトークン) | キャッシュ読み取り ($/Mトークン) | 出力 ($/Mトークン) |
|---|---|---|---|
| DeepSeek-V4-Pro (Novita) | $1.74 | $0.145 | $3.48 |
| DeepSeek-V4-Flash (Novita) | $0.10 | — | $0.50 |
| Claude Opus 4.6 (Anthropic) | $15.00 | $1.50 | $75.00 |
| Gemini 3.1 Pro (Google) | $1.25 | $0.31 | $10.00 |
| GPT-5.4 (OpenAI) | $10.00 | $2.50 | $40.00 |
最終確認: 2026-04-25。Novitaの料金は novita.ai/pricing から。競合他社の料金: Claudeはanthropic.com(未確認)、Geminiはai.google.dev(未確認)、GPT-5.4はplatform.openai.com(未確認)。
Novita AI経由の場合、V4-Proは入力トークンでClaude Opus 4.6の約8分の1、出力トークンで約21分の1のコストです。Gemini 3.1 Proと比較すると、入力価格は同程度ですが、出力は2.9倍安価です。長いコンテキストとマルチターンセッション(出力トークンがコストを支配する)のコーディングエージェントでは、その差は急速に拡大します。
DeepSeek-V3またはDeepSeek-R1からの移行
現在NovitaでDeepSeek-V3またはR1を実行している場合、V4-ProへのアップグレードはモデルIDを1行変更するだけです。APIはOpenAI互換で、同じエンドポイント、同じリクエスト形式です。V4-Proの3つの推論モードにより、V3(Non-thinkモード)とR1スタイルの深い推論(Maxモード)の両方を単一のモデルで再現でき、個別のデプロイメントを維持する必要はありません。別のプロバイダーのモデル(GPT-4o、Claude 3.5など)から移行する場合は、既存のOpenAI SDKクライアントのbase_urlをhttps://api.novita.ai/v3/openaiに設定し、モデルIDを変更するだけです。
結論
結論: DeepSeek-V4-Proは、コーディングタスクにおいて現在利用可能な最強のオープンソースモデルであり、LiveCodeBenchとCodeforcesで明確な#1スコアを記録し、その階層で真の1Mトークンコンテキストウィンドウを処理できる唯一のモデルです。すべてのベンチマークでリードしているわけではありません(知識想起ではGemini 3.1 Proが優位、長文脈検索ではClaude Opusがリード)が、コーディングエージェントを構築するチーム、大規模なGitHub Issueを修正するチーム、または巨大なドキュメントを処理するチームにとって、V4-ProはクローズドモデルのAPIコストの数分の一でフロンティアクラスのパフォーマンスを提供します。Novita AIがバックエンドとなり、200以上のモデルAPIとOpenAI互換インフラを提供します。
Novita AI経由でDeepSeek-V4-Proを試す →
FAQ
DeepSeek-V4-Proとは何ですか?
DeepSeek-V4-Proは、DeepSeek AIが2026年4月にリリースした1.6兆パラメータのMixture-of-Experts言語モデルです。フォワードパスあたり49Bパラメータを活性化し、1,048,576トークンのコンテキストをサポートし、現在公開評価されているすべてのモデルの中でLiveCodeBench(93.5)とCodeforcesレーティング(3206)でトップです。MITライセンスで利用可能で、Novita AIからも提供されています。
API経由でDeepSeek-V4-Proにアクセスするには?
モデルID deepseek/deepseek-v4-pro を base_url="https://api.novita.ai/v3/openai" とNovita APIキー(novita.ai/settings から取得)とともに使用します。エンドポイントはOpenAI SDK互換であり、カスタムSDKは不要です。
DeepSeek-V4-ProはClaude Opus 4.6やGemini 3.1 Proと比較してどうですか?
V4-Proはコーディングでリードしています。LiveCodeBench 93.5(Opus 4.6 88.8、Gemini 91.7)、Codeforces 3206(Gemini 3052)。知識ベンチマーク(GPQA Diamond、HLE)ではGemini 3.1 Proがリードしています。長文脈検索(MRCR 1M)ではClaude Opusがリードしています。V4-Proはコーディング重視およびエージェントワークロードに最適なオープンソースの選択肢であり、クローズドモデルは生の事実想起で優位性を維持しています。
DeepSeek-V4-Proのコンテキストウィンドウは?
1,048,576トークン(1M)です。このモデルはHybrid Attention(CSA + HCA)を使用して長文脈効率のために特別に設計されています。MRCR 1Mで83.5、CorpusQA 1Mで62.0を記録し、フルコンテキスト長でも使用可能な検索精度を確認しています。
Novita AIがバックエンドのDeepSeek-V4-Proの料金は?
入力$1.74/Mトークン、出力$3.48/Mトークン、キャッシュ読み取り$0.145/Mトークンです。これにより、Claude Opus 4.6と比較して入力で約8分の1、出力で約21分の1のコストになります。最終確認: 2026-04-25。



