

DeepSeek-V4-Pro: 1M de contexto, #1 en LiveCodeBench, la frontera del código abierto
Estás evaluando modelos de código abierto para un agente de codificación en producción. Necesitas algo que maneje bases de código grandes (repositorios completos, no solo archivos individuales) y que realmente resuelva problemas de GitHub sin alucinar llamadas a herramientas. Todos los modelos que pruebas o fallan más allá de 128K tokens o se quedan atrás de GPT-4o en los benchmarks que importan para tareas reales de ingeniería.
DeepSeek-V4-Pro cambia este cálculo. Es un modelo MoE de 1.6 billones de parámetros con una ventana de contexto real de 1M de tokens, la puntuación publicada más alta en LiveCodeBench (93.5 Pass@1) y un rating de Codeforces de 3206, ambos #1 entre todos los modelos evaluados, incluyendo APIs fronterizas cerradas. En resumen: es el mejor modelo de código abierto disponible hoy para codificación competitiva y tareas agénticas de gran contexto, publicado bajo licencia MIT. A partir de hoy, está disponible a través de Novita AI.
Prueba DeepSeek-V4-Pro ahora →
¿Qué es DeepSeek-V4-Pro?
DeepSeek-V4-Pro es el modelo insignia de la serie V4 de DeepSeek, lanzado el 24 de abril de 2026. Se sitúa por encima del ligero DeepSeek-V4-Flash (284B total / 13B activos) y se posiciona como una vista previa de las capacidades fronterizas actuales de DeepSeek, lo que describen como el “mejor modelo de código abierto disponible hoy” para conocimiento y codificación. El modelo está entrenado con más de 32 billones de tokens y ajustado mediante un pipeline de dos etapas: SFT experto en dominio + aprendizaje por refuerzo GRPO, seguido de destilación on-policy. Los detalles técnicos completos están en el artículo de DeepSeek DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence.
Especificaciones clave de un vistazo:
- Arquitectura: Mixture-of-Experts (MoE) con Atención Híbrida: Atención Dispersa Comprimida (CSA) + Atención Altamente Comprimida (HCA)
- Parámetros: 1.6T total / 49B activados por paso forward
- Ventana de contexto: 1,048,576 tokens (1M)
- Precisión: FP4 (expertos MoE) + mixto FP8
- Modos de razonamiento: No pensar (rápido), Pensar (CoT estándar), Máximo (presupuesto de razonamiento máximo)
- Capacidades: Llamada a funciones, salidas estructuradas, razonamiento, recuperación en contexto de 1M
- Licencia: MIT
Características clave
Atención híbrida para un contexto eficiente de 1M de tokens
La mayoría de los modelos que afirman tener “contexto largo” o truncan silenciosamente o se degradan bruscamente más allá de 128K tokens. La Arquitectura de Atención Híbrida de DeepSeek-V4-Pro, que combina Atención Dispersa Comprimida (CSA) y Atención Altamente Comprimida (HCA) junto con Conexiones Hiper Restringidas por Variedad (mHC), está diseñada desde cero para el procesamiento eficiente de un millón de tokens. En la práctica: MRCR 1M obtiene 83.5 (recuperación de memoria en 1M de contexto) y CorpusQA 1M alcanza 62.0, manteniendo un razonamiento coherente en toda la ventana. Para agentes que necesitan ingerir una base de código completa, un día de registros o un documento del tamaño de un libro en una sola llamada, esta es la arquitectura que lo hace viable sin infraestructura especializada.
#1 en LiveCodeBench y Codeforces: el modelo de codificación que realmente compite
DeepSeek-V4-Pro obtiene 93.5 en LiveCodeBench (Pass@1) y 3206 en rating de Codeforces, ambas las puntuaciones publicadas más altas en la tabla de comparación, superando a Claude Opus 4.6 Max (88.8 / sin rating), Gemini 3.1 Pro High (91.7 / 3052) y GPT-5.4 xHigh (sin puntuación LCB / 3168). En SWE-Verified (resolución de problemas reales de GitHub), alcanza 80.6, a la par con Claude Opus 4.6 Max (80.8) y Gemini 3.1 Pro (80.6). Para equipos que construyen agentes de codificación donde lo que importa es si realmente puede arreglar el error, más que las puntuaciones teóricas de MMLU, V4-Pro es la opción de código abierto que compite directamente con las APIs fronterizas cerradas.
Tres modos de razonamiento: adecúa el cómputo a la tarea
DeepSeek-V4-Pro expone tres modos de inferencia a través del mismo endpoint de API:
- No pensar: Sin cadena de pensamiento. Rápido, baja latencia. Adecuado para clasificación, extracción, tareas de salida estructurada donde la sobrecarga de razonamiento es innecesaria.
- Pensar: Razonamiento CoT estándar. El predeterminado para codificación, matemáticas y tareas de múltiples pasos.
- Máximo (V4-Pro Max): Presupuesto de razonamiento extendido. Úsalo cuando la precisión importe más que la velocidad: demostraciones complejas, problemas difíciles de programación competitiva, sesiones de depuración profundas.
Los tres modos son accesibles a través del ID de modelo deepseek/deepseek-v4-pro respaldado por Novita AI. Cambiar entre ellos es una instrucción a nivel de prompt, no un endpoint diferente, lo que significa que puedes implementar la selección adaptativa de modos en tu aplicación sin cambiar la configuración de la API.
Rendimiento agéntico y de uso de herramientas
Más allá de los benchmarks de codificación, V4-Pro se defiende en evaluaciones agénticas. BrowseComp: 83.4 (vs Claude Opus 83.7, Gemini 85.9: dentro de 2.5 puntos de la frontera). MCPAtlas Public: 73.6, solo superado por Claude Opus 4.6 (73.8). Toolathlon: 51.8, tercero en general. Estos no son resultados de “líder en todos los modelos”, pero confirman que V4-Pro es un modelo agéntico de propósito general capaz, no solo un especialista en codificación optimizado para benchmarks. Combinado con soporte nativo para llamadas a funciones, es una opción práctica para agentes que necesitan navegar, llamar herramientas y razonar en una sola sesión.
Rendimiento en benchmarks
La tabla a continuación cubre los benchmarks de la comparación oficial de DeepSeek. “V4-Pro” se refiere al modo DeepSeek-V4-Pro Max (razonamiento extendido), el mismo modelo accesible a través del ID de API deepseek/deepseek-v4-pro en Novita.
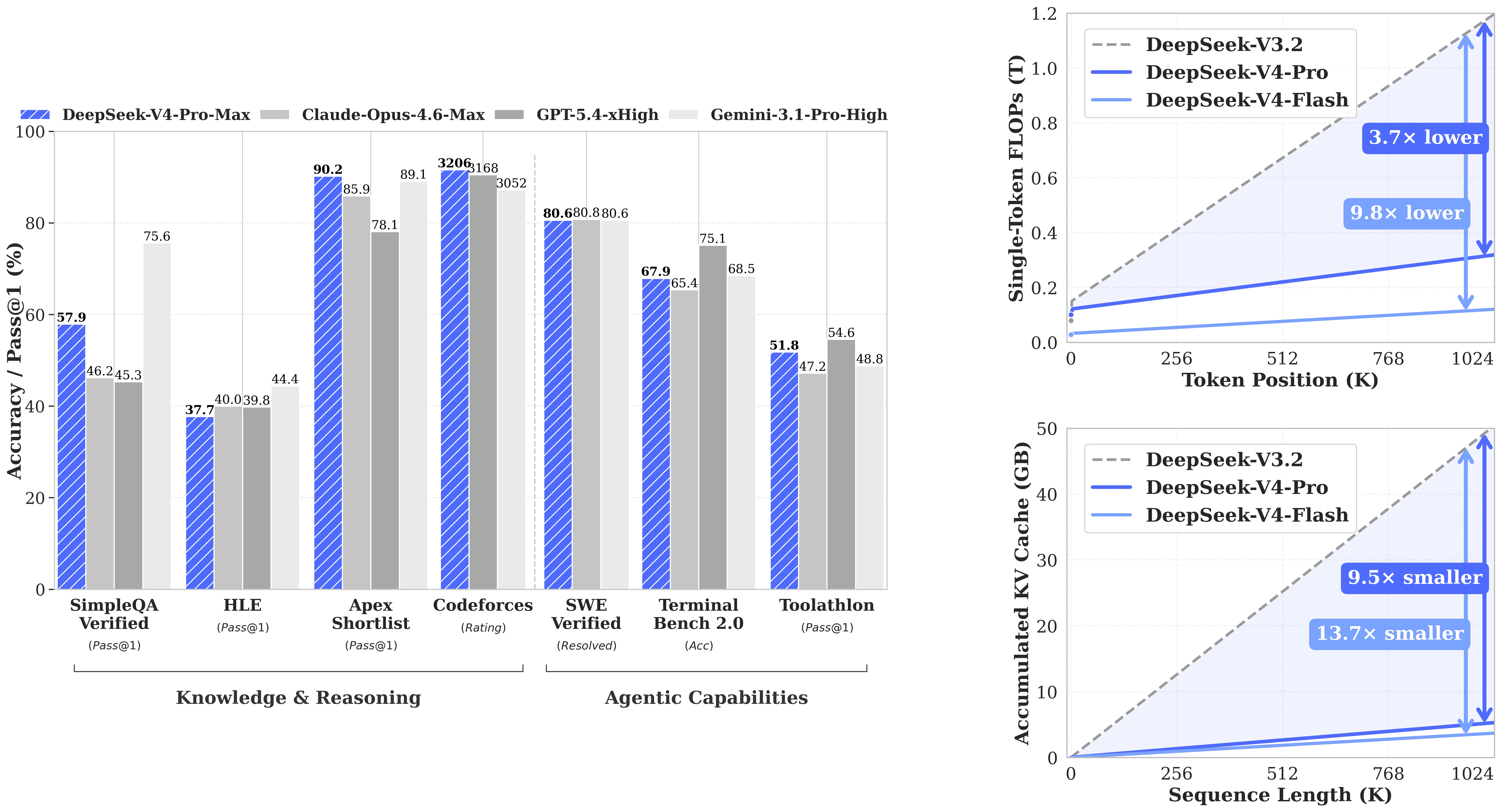
Rendimiento de DeepSeek-V4-Pro en benchmarks de codificación, razonamiento y agénticos. [Fuente: DeepSeek HuggingFace]
| Benchmark | DeepSeek-V4-Pro | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 93.5 ✓ | 88.8 | 91.7 | — |
| Codeforces Rating | 3206 ✓ | — | 3052 | 3168 |
| SWE-Verified | 80.6 | 80.8 | 80.6 | — |
| SWE Pro | 55.4 | 57.3 | 54.2 | 57.7 |
| BrowseComp | 83.4 | 83.7 | 85.9 | 82.7 |
| MCPAtlas Public | 73.6 | 73.8 | 69.2 | 67.2 |
| GPQA Diamond | 90.1 | 91.3 | 94.3 | 93.0 |
| HLE (Pass@1) | 37.7 | 40.0 | 44.4 | 39.8 |
| IMOAnswerBench | 89.8 | 75.3 | 81.0 | 91.4 |
| HMMT 2026 Feb | 95.2 | 96.2 | 94.7 | 97.7 |
| MRCR 1M (MMR) | 83.5 | 92.9 | 76.3 | — |
| CorpusQA 1M | 62.0 | 71.7 | 53.8 | — |
| Terminal Bench 2.0 | 67.9 | 65.4 | 68.5 | 75.1 |
✓ = puntuación publicada más alta en esta comparación. Última verificación: 2026-04-25. Las puntuaciones reflejan el modo “Max” / razonamiento extendido cuando corresponde. Fuente: Ficha del modelo en HuggingFace de DeepSeek.
Lectura honesta: En benchmarks de conocimiento (GPQA Diamond, HLE), Gemini 3.1 Pro y GPT-5.4 están claramente por delante. La ventaja de V4-Pro está en la codificación: LiveCodeBench y Codeforces son puntuaciones #1 sin ambigüedad, y en la recuperación de contexto largo frente a otros modelos de código abierto. Para el razonamiento matemático, la brecha es mixta: V4-Pro supera a GPT-5.4 en IMOAnswerBench (89.8 vs 91.4, cercano), pero se queda atrás en HMMT 2026 (95.2 vs 97.7).
Cómo usar DeepSeek-V4-Pro respaldado por Novita AI
Opción 1: Playground (sin código)
Pruébalo directamente en novita.ai/models/model-detail/deepseek-deepseek-v4-pro. No se necesita clave API para explorar. Configura el prompt del sistema para activar el modo Pensar o No pensar.
Opción 2: API (Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="TU_CLAVE_API_NOVITA",
)
# Modo estándar (Pensar)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-pro",
messages=[
{"role": "user", "content": "Implementa un runtime asíncrono de Rust desde cero."}
],
)
print(response.choices[0].message.content)
Obtén tu clave API en novita.ai/settings. El mismo ID de modelo funciona para los tres modos de razonamiento: pasa las instrucciones del modo en el prompt del sistema o usa la sintaxis documentada de cambio de modo de DeepSeek.
Opción 3: Herramientas de terceros
Dado que Novita AI es compatible con la API de OpenAI, puedes usar deepseek/deepseek-v4-pro como ID de modelo en Cursor (proveedor personalizado de OpenAI), configuraciones compatibles con Claude Code, LangChain, LlamaIndex o cualquier framework basado en el SDK de OpenAI. Solo apunta base_url a https://api.novita.ai/v3/openai.
curl https://api.novita.ai/v3/openai/chat/completions \\
-H "Authorization: Bearer TU_CLAVE_API_NOVITA" \\
-H "Content-Type: application/json" \\
-d '{"model":"deepseek/deepseek-v4-pro","messages":[{"role":"user","content":"Implementa un runtime asíncrono de Rust."}]}'
Casos de uso
Análisis y refactorización de bases de código completas: Con 1M de tokens de contexto, puedes pasar un repositorio mediano completo en una sola llamada. Pídele a V4-Pro que encuentre problemas arquitectónicos, genere guías de migración o refactorice patrones en más de 50 archivos simultáneamente, sin necesidad de dividir ni usar trucos de recuperación.
Programación competitiva y problemas de algoritmos difíciles: El rating de Codeforces 3206 sitúa a V4-Pro en la cima para la resolución de problemas algorítmicos. Úsalo para generar soluciones a desafíos de programación competitiva, verificar demostraciones de complejidad o probar casos límite en algoritmos de producción.
Agentes de resolución de problemas de GitHub: SWE-Verified 80.6 coloca a V4-Pro a la par con Claude Opus 4.6 en la corrección de errores del mundo real. Combinado con llamadas a funciones y contexto largo, puede leer descripciones de problemas, explorar el historial del código y generar parches sin perder el hilo en repositorios grandes.
Razonamiento en documentos largos: Contratos legales, artículos de investigación, especificaciones técnicas, registros de auditoría: el contexto de 1M de V4-Pro significa que no te ves forzado a resumir o fragmentar antes del análisis. CorpusQA 1M (62.0) y MRCR 1M (83.5) confirman que la precisión de recuperación se mantiene con la longitud completa del contexto.
Tutoría y generación de problemas de matemáticas y ciencias: IMOAnswerBench 89.8 (supera a todos los modelos cerrados excepto GPT-5.4 con 91.4) convierte a V4-Pro en una opción sólida para generar problemas de matemáticas de nivel competitivo, verificar demostraciones o construir herramientas educativas STEM donde el razonamiento matemático es el cuello de botella.
Precios
| Modelo | Entrada ($/M tokens) | Lectura de caché ($/M tokens) | Salida ($/M tokens) |
|---|---|---|---|
| DeepSeek-V4-Pro (Novita) | $1.74 | $0.145 | $3.48 |
| DeepSeek-V4-Flash (Novita) | $0.10 | — | $0.50 |
| Claude Opus 4.6 (Anthropic) | $15.00 | $1.50 | $75.00 |
| Gemini 3.1 Pro (Google) | $1.25 | $0.31 | $10.00 |
| GPT-5.4 (OpenAI) | $10.00 | $2.50 | $40.00 |
Última verificación: 2026-04-25. Precios de Novita desde novita.ai/pricing. Precios de la competencia: Claude de anthropic.com (no verificado), Gemini de ai.google.dev (no verificado), GPT-5.4 de platform.openai.com (no verificado).
A través de Novita AI, V4-Pro es aproximadamente 8× más barato que Claude Opus 4.6 para tokens de entrada y 21× más barato para tokens de salida. Comparado con Gemini 3.1 Pro, el precio de entrada es similar, pero la salida es 2.9× más barata. Para agentes de codificación con contexto largo y sesiones de múltiples turnos, donde los tokens de salida dominan los costos, la brecha se acumula rápidamente.
Migración desde DeepSeek-V3 o DeepSeek-R1
Si actualmente estás usando DeepSeek-V3 o R1 en Novita, actualizar a V4-Pro es un cambio de ID de modelo de una línea. La API es compatible con OpenAI, el mismo endpoint, el mismo formato de solicitud. Los tres modos de razonamiento de V4-Pro te dan la flexibilidad de replicar tanto V3 (modo No pensar) como el razonamiento profundo al estilo R1 (modo Máximo) desde un solo modelo, sin necesidad de mantener implementaciones separadas. Si estás migrando desde el modelo de otro proveedor (GPT-4o, Claude 3.5, etc.), apunta tu cliente del SDK de OpenAI existente a base_url="https://api.novita.ai/v3/openai" y cambia el ID del modelo.
Conclusión
En resumen: DeepSeek-V4-Pro es el modelo de código abierto más potente disponible para tareas de codificación, con puntuaciones #1 definitivas en LiveCodeBench y Codeforces, y es el único modelo en su categoría que maneja una ventana de contexto genuina de 1M de tokens. No lidera todos los benchmarks (Gemini 3.1 Pro tiene ventaja en recuperación de conocimiento, y Claude Opus lidera en recuperación de contexto largo), pero para equipos que construyen agentes de codificación, corrigen problemas de GitHub a escala o procesan documentos masivos, V4-Pro ofrece rendimiento de clase fronteriza a una fracción del costo de las APIs de modelos cerrados. Ya disponible respaldado por Novita AI: más de 200 APIs de modelos e infraestructura compatible con OpenAI.
Para los equipos que no necesitan Pro en cada solicitud, la comparación entre DeepSeek V4 Pro y Flash explica cómo usar Flash para tráfico base de menor costo y reservar Pro para trabajos de codificación o contexto largo con mayor costo de fallo.
Prueba DeepSeek-V4-Pro a través de Novita AI →
Preguntas frecuentes
¿Qué es DeepSeek-V4-Pro?
DeepSeek-V4-Pro es un modelo de lenguaje Mixture-of-Experts de 1.6 billones de parámetros de DeepSeek AI, lanzado en abril de 2026. Activa 49B de parámetros por paso forward, admite 1,048,576 tokens de contexto y actualmente lidera todos los modelos evaluados públicamente en LiveCodeBench (93.5) y Codeforces Rating (3206). Está disponible bajo la licencia MIT y a través de Novita AI.
¿Cómo accedo a DeepSeek-V4-Pro a través de la API?
Usa el ID de modelo deepseek/deepseek-v4-pro con base_url="https://api.novita.ai/v3/openai" y tu clave API de Novita desde novita.ai/settings. El endpoint es compatible con el SDK de OpenAI: no se requiere SDK personalizado.
¿Cómo se compara DeepSeek-V4-Pro con Claude Opus 4.6 y Gemini 3.1 Pro?
V4-Pro lidera en codificación: LiveCodeBench 93.5 (vs Opus 4.6 88.8, Gemini 91.7) y Codeforces 3206 (vs Gemini 3052). En benchmarks de conocimiento como GPQA Diamond y HLE, Gemini 3.1 Pro lidera. En recuperación de contexto largo (MRCR 1M), Claude Opus lidera. V4-Pro es la mejor opción de código abierto para cargas de trabajo centradas en codificación y agénticas; los modelos cerrados mantienen ventajas en recuperación de hechos puros.
¿Cuál es la ventana de contexto de DeepSeek-V4-Pro?
1,048,576 tokens (1M). El modelo está específicamente diseñado para eficiencia en contexto largo mediante Atención Híbrida (CSA + HCA). MRCR 1M obtiene 83.5 y CorpusQA 1M alcanza 62.0, lo que confirma una precisión de recuperación utilizable en toda la longitud del contexto.
¿Cuánto cuesta DeepSeek-V4-Pro respaldado por Novita AI?
$1.74/M tokens de entrada, $3.48/M tokens de salida, $0.145/M lectura de caché. Esto lo hace aproximadamente 8× más barato que Claude Opus 4.6 para entrada y 21× más barato para salida. Última verificación: 2026-04-25.



