

DeepSeek-V4-Pro: 1M Kontext, #1 bei LiveCodeBench, Open-Source-Spitzenmodell
Sie bewerten Open-Source-Modelle für einen produktiven Code-Agenten. Sie brauchen etwas, das große Codebasen verarbeiten kann – ganze Repositories, nicht nur einzelne Dateien – und GitHub-Issues tatsächlich löst, ohne Tool-Calls zu halluzinieren. Jedes Modell, das Sie ausprobieren, bricht entweder jenseits von 128K Tokens ein oder bleibt hinter GPT-4o bei den Benchmarks zurück, die für echte Engineering-Aufgaben relevant sind.
DeepSeek-V4-Pro ändert diese Rechnung. Es ist ein 1,6-Billionen-Parameter-MoE-Modell mit einem echten 1M-Token-Kontextfenster, dem höchsten veröffentlichten Score bei LiveCodeBench (93,5 Pass@1) und einer Codeforces-Bewertung von 3206 – beides Platz #1 unter allen evaluierten Modellen, einschließlich geschlossener Frontier-APIs. Kurz gesagt: Es ist das beste heute verfügbare Open-Source-Modell für kompetitives Programmieren und agentische Aufgaben mit großem Kontext, veröffentlicht unter MIT-Lizenz. Ab sofort verfügbar über Novita AI.
DeepSeek-V4-Pro jetzt testen →
Was ist DeepSeek-V4-Pro?
DeepSeek-V4-Pro ist das Flaggschiff-Modell der DeepSeek-V4-Serie, veröffentlicht am 24. April 2026. Es steht über dem leichteren DeepSeek-V4-Flash (284B total / 13B aktiv) und wird als Vorschau auf DeepSeeks aktuelle Frontier-Fähigkeiten positioniert – das, was sie als „bestes derzeit verfügbares Open-Source-Modell“ für Wissen und Programmierung beschreiben. Das Modell wurde mit über 32 Billionen Tokens trainiert und in einer zweistufigen Pipeline verfeinert: Domain-Expert-SFT + GRPO-Verstärkungslernen, gefolgt von On-Policy-Destillation. Die vollständigen technischen Details finden sich in DeepSeeks Paper DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence.
Wichtige Spezifikationen auf einen Blick:
- Architektur: Mixture-of-Experts (MoE) mit Hybrid Attention – Compressed Sparse Attention (CSA) + Heavily Compressed Attention (HCA)
- Parameter: 1,6B total / 49B aktiviert pro Vorwärtspass
- Kontextfenster: 1.048.576 Tokens (1M)
- Präzision: FP4 (MoE-Experten) + FP8 gemischt
- Reasoning-Modi: Non-think (schnell), Think (Standard CoT), Max (maximales Reasoning-Budget)
- Funktionen: Function Calling, strukturierte Ausgaben, Reasoning, 1M-Kontextabruf
- Lizenz: MIT
Wichtige Funktionen
Hybrid Attention für effizienten 1M-Token-Kontext
Die meisten Modelle, die einen „langen Kontext“ beanspruchen, kürzen entweder stillschweigend oder lassen jenseits von 128K Tokens stark nach. DeepSeek-V4-Pros Hybrid-Attention-Architektur – die Compressed Sparse Attention (CSA) und Heavily Compressed Attention (HCA) zusammen mit Manifold-Constrained Hyper-Connections (mHC) kombiniert – ist von Grund auf für eine effiziente Verarbeitung von Millionen von Tokens ausgelegt. In der Praxis: MRCR 1M erreicht 83,5 (Speicherabruf über 1M Kontext) und CorpusQA 1M erzielt 62,0, wobei die kohärente Argumentation über das gesamte Fenster erhalten bleibt. Für Agenten, die eine gesamte Codebasis, einen Tagesprotokoll oder ein buchlanges Dokument in einem einzigen Aufruf erfassen müssen, ist dies die Architektur, die dies ohne spezialisierte Infrastruktur möglich macht.
#1 bei LiveCodeBench und Codeforces – Das Programmiermodell, das wirklich konkurriert
DeepSeek-V4-Pro erzielt 93,5 bei LiveCodeBench (Pass@1) und 3206 bei Codeforces – beides die höchsten veröffentlichten Werte in der Vergleichstabelle und schlägt damit Claude Opus 4.6 Max (88,8 / keine Bewertung), Gemini 3.1 Pro High (91,7 / 3052) sowie GPT-5.4 xHigh (kein LCB-Score / 3168). Bei SWE-Verified (reale GitHub-Issue-Lösung) erreicht es 80,6, gleichauf mit Claude Opus 4.6 Max (80,8) und Gemini 3.1 Pro (80,6). Für Teams, die Code-Agenten entwickeln, bei denen „Kann es den Fehler wirklich beheben?“ wichtiger ist als theoretische MMLU-Werte, ist V4-Pro die Open-Source-Option, die direkt mit geschlossenen Frontier-APIs konkurriert.
Drei Reasoning-Modi – Rechenleistung an die Aufgabe anpassen
DeepSeek-V4-Pro stellt drei Inferenzmodi über denselben API-Endpunkt zur Verfügung:
- Non-think: Keine Chain-of-Thought. Schnell, niedrige Latenz – geeignet für Klassifikation, Extraktion, strukturierte Ausgaben, bei denen Reasoning-Overhead verschwenderisch ist.
- Think: Standard CoT-Reasoning. Die Voreinstellung für Programmierung, Mathematik und mehrstufige Aufgaben.
- Max (V4-Pro Max): Erweitertes Reasoning-Budget. Verwenden Sie dies, wenn Genauigkeit wichtiger ist als Geschwindigkeit – komplexe Beweise, schwierige kompetitive Programmierprobleme, tiefgehende Debugging-Sitzungen.
Alle drei Modi sind über die Modell-ID deepseek/deepseek-v4-pro zugänglich, die von Novita AI bereitgestellt wird. Der Wechsel zwischen ihnen erfolgt durch eine Anweisung auf Prompt-Ebene, nicht über einen anderen Endpunkt – das bedeutet, Sie können eine adaptive Modusauswahl in Ihrer Anwendung implementieren, ohne die API-Konfiguration zu ändern.
Agentische Leistung und Tool-Nutzung
Neben den Programmier-Benchmarks behauptet sich V4-Pro auch bei agentischen Evaluierungen. BrowseComp: 83,4 (vs. Claude Opus 83,7, Gemini 85,9 – innerhalb von 2,5 Punkten der Spitze). MCPAtlas Public: 73,6, nur hinter Claude Opus 4.6 (73,8). Toolathlon: 51,8, insgesamt Dritter. Dies sind keine „führt alle Modelle an“-Ergebnisse, aber sie bestätigen, dass V4-Pro ein leistungsfähiges, universell einsetzbares agentisches Modell ist, nicht nur ein auf Benchmarks optimierter Programmier-Spezialist. In Kombination mit nativem Function Calling ist es eine praktische Wahl für Agenten, die in einer einzigen Sitzung browsen, Tools aufrufen und argumentieren müssen.
Benchmark-Leistung
Die folgende Tabelle zeigt die Benchmarks aus DeepSeeks offiziellem Vergleich. „V4-Pro“ bezieht sich auf den DeepSeek-V4-Pro Max-Modus (erweitertes Reasoning) – dasselbe Modell, das über die API-ID deepseek/deepseek-v4-pro bei Novita zugänglich ist.
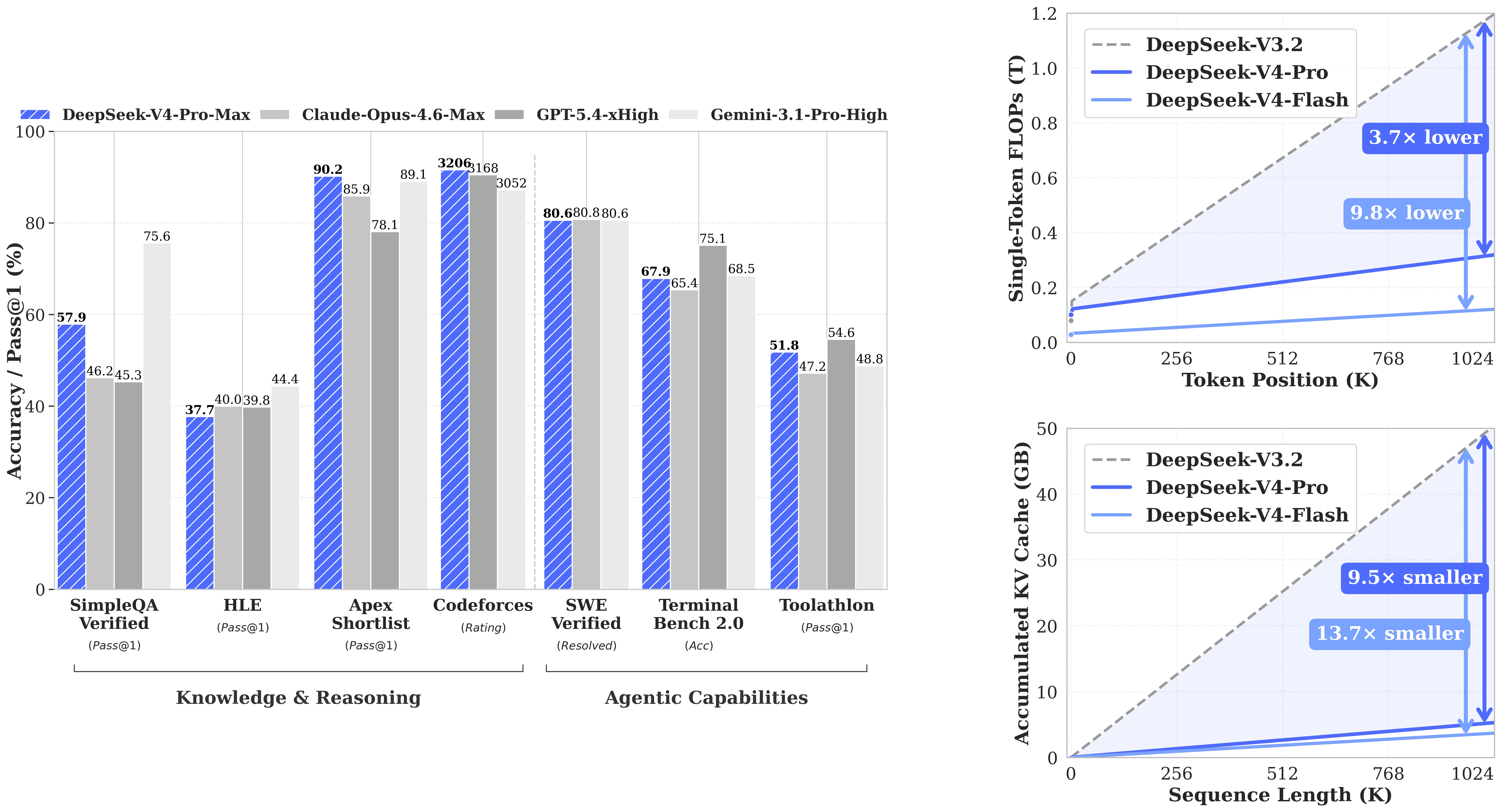
Leistung von DeepSeek-V4-Pro bei Programmier-, Reasoning- und agentischen Benchmarks. [Quelle: DeepSeek HuggingFace]
| Benchmark | DeepSeek-V4-Pro | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 93,5 ✓ | 88,8 | 91,7 | — |
| Codeforces Rating | 3206 ✓ | — | 3052 | 3168 |
| SWE-Verified | 80,6 | 80,8 | 80,6 | — |
| SWE Pro | 55,4 | 57,3 | 54,2 | 57,7 |
| BrowseComp | 83,4 | 83,7 | 85,9 | 82,7 |
| MCPAtlas Public | 73,6 | 73,8 | 69,2 | 67,2 |
| GPQA Diamond | 90,1 | 91,3 | 94,3 | 93,0 |
| HLE (Pass@1) | 37,7 | 40,0 | 44,4 | 39,8 |
| IMOAnswerBench | 89,8 | 75,3 | 81,0 | 91,4 |
| HMMT 2026 Feb | 95,2 | 96,2 | 94,7 | 97,7 |
| MRCR 1M (MMR) | 83,5 | 92,9 | 76,3 | — |
| CorpusQA 1M | 62,0 | 71,7 | 53,8 | — |
| Terminal Bench 2.0 | 67,9 | 65,4 | 68,5 | 75,1 |
✓ = höchster veröffentlichter Wert in diesem Vergleich. Zuletzt überprüft: 25.04.2026. Werte beziehen sich auf den „Max“-/erweiterten Reasoning-Modus, sofern zutreffend. Quelle: DeepSeek HuggingFace Model Card.
Ehrliche Einschätzung: Bei Wissens-Benchmarks (GPQA Diamond, HLE) liegen Gemini 3.1 Pro und GPT-5.4 klar vorn. Die Stärke von V4-Pro liegt in der Programmierung – LiveCodeBench und Codeforces sind eindeutig #1-Werte – und im Langkontextabruf im Vergleich zu anderen Open-Source-Modellen. Bei Mathematik-Reasoning ist die Lücke gemischt: V4-Pro schlägt GPT-5.4 bei IMOAnswerBench (89,8 vs. 91,4, knapp) liegt aber bei HMMT 2026 zurück (95,2 vs. 97,7).
So verwenden Sie DeepSeek-V4-Pro mit Novita AI
Option 1: Playground (Ohne Code)
Testen Sie direkt unter novita.ai/models/model-detail/deepseek-deepseek-v4-pro. Kein API-Schlüssel erforderlich, um es auszuprobieren. Setzen Sie den System-Prompt, um den Think- oder Non-think-Modus zu aktivieren.
Option 2: API (Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="IHR_NOVITA_API_SCHLÜSSEL",
)
# Standard (Think-Modus)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-pro",
messages=[
{"role": "user", "content": "Implementiere eine Rust async runtime von Grund auf."}
],
)
print(response.choices[0].message.content)
Holen Sie sich Ihren API-Schlüssel unter novita.ai/settings. Dieselbe Modell-ID funktioniert für alle drei Reasoning-Modi – übergeben Sie Modusanweisungen im System-Prompt oder verwenden Sie DeepSeeks dokumentierte Syntax zum Moduswechsel.
Option 3: Drittanbieter-Tools
Da Novita AI mit der OpenAI-API kompatibel ist, können Sie deepseek/deepseek-v4-pro als Modell-ID in Cursor (benutzerdefinierter OpenAI-Anbieter), Claude Code-kompatiblen Setups, LangChain, LlamaIndex oder jedem auf dem OpenAI SDK basierenden Framework verwenden. Setzen Sie einfach base_url auf https://api.novita.ai/v3/openai.
curl https://api.novita.ai/v3/openai/chat/completions \\
-H "Authorization: Bearer IHR_NOVITA_API_SCHLÜSSEL" \\
-H "Content-Type: application/json" \\
-d '{"model":"deepseek/deepseek-v4-pro","messages":[{"role":"user","content":"Implementiere eine Rust async runtime."}]}'
Anwendungsfälle
Analyse und Refactoring der gesamten Codebasis: Mit einem 1M-Token-Kontext können Sie ein mittelgroßes Repository in einem einzigen Aufruf übergeben. Bitten Sie V4-Pro, architektonische Probleme zu finden, Migrationsleitfäden zu erstellen oder Muster über 50+ Dateien gleichzeitig zu refaktorieren – ohne Chunking oder Retrieval-Hacks.
Kompetitives Programmieren und schwierige Algorithmenprobleme: Mit einer Codeforces-Bewertung von 3206 gehört V4-Pro zur Spitze bei algorithmischen Problemlösungen. Nutzen Sie es zum Generieren von Lösungen für Programmierwettbewerbe, zur Überprüfung von Komplexitätsbeweisen oder zum Stresstesten von Randfällen in Produktionsalgorithmen.
GitHub-Issue-Lösungsagenten: Mit SWE-Verified 80,6 ist V4-Pro bei der realen Fehlerbehebung gleichauf mit Claude Opus 4.6. Kombiniert mit Function Calling und langem Kontext kann es Issue-Beschreibungen lesen, Code-History durchsuchen und Patches generieren, ohne bei großen Repos den Überblick zu verlieren.
Reasoning über lange Dokumente: rechtliche Verträge, Forschungspapiere, technische Spezifikationen, Prüfprotokolle – der 1M-Kontext von V4-Pro bedeutet, dass Sie nicht gezwungen sind, vor der Analyse zusammenzufassen oder zu chunken. CorpusQA 1M (62,0) und MRCR 1M (83,5) bestätigen die Abrufgenauigkeit bei voller Kontextlänge.
Mathe- und Naturwissenschaftsnachhilfe / Aufgabengenerierung: Mit IMOAnswerBench 89,8 (schlägt alle geschlossenen Modelle außer GPT-5.4 mit 91,4) ist V4-Pro eine starke Wahl zum Generieren von Mathematikaufgaben auf Wettbewerbsniveau, zum Überprüfen von Beweisen oder zum Erstellen von MINT-Bildungstools, bei denen mathematisches Reasoning der Engpass ist.
Preise
| Modell | Eingabe ($/M Tokens) | Cache-Lesen ($/M Tokens) | Ausgabe ($/M Tokens) |
|---|---|---|---|
| DeepSeek-V4-Pro (Novita) | $1,74 | $0,145 | $3,48 |
| DeepSeek-V4-Flash (Novita) | $0,10 | — | $0,50 |
| Claude Opus 4.6 (Anthropic) | $15,00 | $1,50 | $75,00 |
| Gemini 3.1 Pro (Google) | $1,25 | $0,31 | $10,00 |
| GPT-5.4 (OpenAI) | $10,00 | $2,50 | $40,00 |
Zuletzt überprüft: 25.04.2026. Novita-Preise von novita.ai/pricing. Preise der Wettbewerber: Claude von anthropic.com (nicht verifiziert), Gemini von ai.google.dev (nicht verifiziert), GPT-5.4 von platform.openai.com (nicht verifiziert).
Über Novita AI ist V4-Pro bei den Eingabetokens etwa 8× günstiger als Claude Opus 4.6 und bei den Ausgaben 21× günstiger. Im Vergleich zu Gemini 3.1 Pro sind die Eingabepreise ähnlich, aber die Ausgaben sind 2,9× günstiger. Bei Code-Agenten mit langem Kontext und mehreren Iterationen – wo Ausgabetokens die Kosten dominieren – summiert sich der Unterschied schnell.
Migration von DeepSeek-V3 oder DeepSeek-R1
Wenn Sie derzeit DeepSeek-V3 oder R1 auf Novita betreiben, ist das Upgrade auf V4-Pro eine Änderung der Modell-ID in einer Zeile. Die API ist OpenAI-kompatibel, gleicher Endpunkt, gleiches Anfrageformat. Die drei Reasoning-Modi von V4-Pro geben Ihnen die Flexibilität, sowohl V3 (Non-think-Modus) als auch R1-artiges tiefes Reasoning (Max-Modus) aus einem einzigen Modell zu replizieren – ohne separate Bereitstellungen aufrechterhalten zu müssen. Wenn Sie von einem Modell eines anderen Anbieters (GPT-4o, Claude 3.5 usw.) migrieren, richten Sie Ihren vorhandenen OpenAI-SDK-Client auf base_url="https://api.novita.ai/v3/openai" aus und tauschen Sie die Modell-ID aus.
Fazit
Fazit: DeepSeek-V4-Pro ist das stärkste Open-Source-Modell für Programmieraufgaben, mit definitiven #1-Werten bei LiveCodeBench und Codeforces, und es ist das einzige Modell seiner Klasse, das ein echtes 1M-Token-Kontextfenster verarbeitet. Es führt nicht bei jedem Benchmark – Gemini 3.1 Pro liegt beim Wissensabruf vorn, und Claude Opus führt beim Langkontextabruf – aber für Teams, die Code-Agenten bauen, GitHub-Issues in großem Maßstab beheben oder riesige Dokumente verarbeiten, liefert V4-Pro Spitzenleistung zu einem Bruchteil der Kosten geschlossener Modell-APIs. Jetzt verfügbar über Novita AI – 200+ Modell-APIs und OpenAI-kompatible Infrastruktur.
DeepSeek-V4-Pro über Novita AI testen →
FAQ
Was ist DeepSeek-V4-Pro?
DeepSeek-V4-Pro ist ein 1,6-Billionen-Parameter-Mixture-of-Experts-Sprachmodell von DeepSeek AI, veröffentlicht im April 2026. Es aktiviert 49B Parameter pro Vorwärtspass, unterstützt 1.048.576 Tokens Kontext und führt derzeit alle öffentlich evaluierten Modelle bei LiveCodeBench (93,5) und Codeforces (3206) an. Es ist unter der MIT-Lizenz und über Novita AI verfügbar.
Wie greife ich über die API auf DeepSeek-V4-Pro zu?
Verwenden Sie die Modell-ID deepseek/deepseek-v4-pro mit base_url="https://api.novita.ai/v3/openai" und Ihrem Novita-API-Schlüssel von novita.ai/settings. Der Endpunkt ist mit dem OpenAI SDK kompatibel – kein benutzerdefiniertes SDK erforderlich.
Wie schneidet DeepSeek-V4-Pro im Vergleich zu Claude Opus 4.6 und Gemini 3.1 Pro ab?
V4-Pro führt beim Programmieren: LiveCodeBench 93,5 (vs. Opus 4.6 88,8, Gemini 91,7) und Codeforces 3206 (vs. Gemini 3052). Bei Wissens-Benchmarks wie GPQA Diamond und HLE führt Gemini 3.1 Pro. Beim Langkontextabruf (MRCR 1M) führt Claude Opus. V4-Pro ist die beste Open-Source-Wahl für programmierintensive und agentische Arbeitslasten – geschlossene Modelle behalten Vorteile beim reinen Faktenabruf.
Wie groß ist das Kontextfenster von DeepSeek-V4-Pro?
1.048.576 Tokens (1M). Das Modell ist speziell für Langkontexteffizienz mit Hybrid Attention (CSA + HCA) entwickelt. MRCR 1M erreicht 83,5 und CorpusQA 1M 62,0, was eine brauchbare Abrufgenauigkeit bei voller Kontextlänge bestätigt.
Wie viel kostet DeepSeek-V4-Pro bei Novita AI?
$1,74/M Eingabetokens, $3,48/M Ausgabetokens, $0,145/M Cache-Lesen. Damit ist es etwa 8× günstiger als Claude Opus 4.6 bei der Eingabe und 21× günstiger bei der Ausgabe. Zuletzt überprüft: 25.04.2026.



