

DeepSeek-V4-Pro:1M 上下文、LiveCodeBench 排名第一、開源前沿
您正在評估用於生產級編碼代理的開源模型。您需要一個能夠處理大型程式碼庫(不只是單一檔案,而是整個儲存庫)的模型,而且要能夠實際解決 GitHub 問題,而不會在工具呼叫時產生幻覺。您嘗試過的每個模型,不是超過 128K Token 就表現失常,就是在真實工程任務相關的基準測試上落後 GPT-4o。
DeepSeek-V4-Pro 改變了這個局面。它是一個 1.6 兆參數的 MoE 模型,擁有真正的 100 萬 Token 上下文視窗、LiveCodeBench 上最高的公開評分(93.5 Pass@1),以及 Codeforces 評級 3206——這兩項在所有受評估的模型(包括封閉前沿 API)中均排名第一。簡而言之:它是目前可用於競賽性編程和大上下文代理任務的最佳開源模型,採用 MIT 許可證發布。從今天起,可經由 Novita AI 取得。
什麼是 DeepSeek-V4-Pro?
DeepSeek-V4-Pro 是 DeepSeek V4 系列中的旗艦模型,於 2026 年 4 月 24 日發布。它位於輕量級 DeepSeek-V4-Flash(284B 總計 / 13B 活躍)之上,定位為 DeepSeek 當前前沿能力的預覽——他們稱之為「目前知識與編程領域中最好的開源模型」。該模型在超過 32 兆個 token 上進行訓練,並通過兩階段流程進行微調:領域專家 SFT + GRPO 強化學習,接著是基於策略的蒸餾。完整的技術細節請參閱 DeepSeek 的論文 DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence。
重點規格一覽:
- 架構: 混合專家模型(MoE)搭配混合注意力——壓縮稀疏注意力(Compressed Sparse Attention, CSA)+ 高度壓縮注意力(Heavily Compressed Attention, HCA)
- 參數: 1.6T 總計 / 每次前向傳播激活 49B
- 上下文視窗: 1,048,576 個 token(1M)
- 精度: FP4(MoE 專家)+ FP8 混合
- 推理模式: 非思考(Non-think,快速)、思考(Think,標準 CoT)、最大(Max,最大推理預算)
- 能力: 函數呼叫、結構化輸出、推理、1M 上下文檢索
- 許可證: MIT
主要特點
針對高效 1M Token 上下文的混合注意力
多數號稱「長上下文」的模型,不是默默截斷,就是在超過 128K token 後效能急遽下降。DeepSeek-V4-Pro 的混合注意力架構——結合壓縮稀疏注意力(CSA)和高度壓縮注意力(HCA),以及流形約束超連接(Manifold-Constrained Hyper-Connections, mHC)——從根本上是為了高效處理百萬級 token 而設計。在實際表現上:MRCR 1M 得分 83.5(在 1M 上下文中記憶回憶),CorpusQA 1M 達到 62.0,同時在整個視窗中保持連貫的推理。對於需要一次性讀取整個程式碼庫、一整天的日誌或一本書長度文件的代理來說,這個架構讓它在無需專門基礎設施的情況下變得可行。
LiveCodeBench 與 Codeforces 排名第一——真正能參與競賽的編碼模型
DeepSeek-V4-Pro 在 LiveCodeBench 上獲得 93.5(Pass@1),Codeforces 評級為 3206——這兩項都是比較表中公佈的最高分數,超越了 Claude Opus 4.6 Max(88.8 / 無評級)、Gemini 3.1 Pro High(91.7 / 3052)和 GPT-5.4 xHigh(無 LCB 分數 / 3168)。在 SWE-Verified(真實世界的 GitHub 問題解決)上,它達到 80.6,與 Claude Opus 4.6 Max(80.8)和 Gemini 3.1 Pro(80.6)相當。對於開發編碼代理的團隊來說,「它真的能修復 bug 嗎」比理論上的 MMLU 分數更重要,而 V4-Pro 正是能直接與封閉前沿 API 競爭的開源選項。
三種推理模式——為任務匹配計算資源
DeepSeek-V4-Pro 透過相同的 API 端點提供三種推理模式:
- Non-think(非思考): 無思維鏈。快速、低延遲——適用於分類、提取、結構化輸出等推理開銷浪費的任務。
- Think(思考): 標準 CoT 推理。編碼、數學和多步驟任務的預設模式。
- Max(V4-Pro Max): 擴展推理預算。在準確性比速度更重要時使用——複雜證明、困難的競賽程式設計問題、深度除錯。
這三種模式都可透過由 Novita AI 支援的 deepseek/deepseek-v4-pro 模型 ID 存取。模式之間的切換是提示層級的指令,而不是不同的端點——這意味著您可以在應用程式中實現自適應模式選擇,而無需更改 API 配置。
代理與工具使用表現
除了編碼基準測驗之外,V4-Pro 在代理評估方面也表現不俗。BrowseComp:83.4(對比 Claude Opus 83.7、Gemini 85.9——與前沿差距在 2.5 分以內)。MCPAtlas Public:73.6,僅次於 Claude Opus 4.6(73.8)。Toolathlon:51.8,總排名第三。這些結果並非「領先所有模型」,但它們證明了 V4-Pro 是一個能力全面的通用代理模型,而不僅僅是針對基準測試優化的編碼專家。結合原生函數呼叫支援,它是需要瀏覽、呼叫工具並在單一會話中進行推理的代理的實用選擇。
基準測試表現
下表涵蓋了 DeepSeek 官方比較中的基準測試。「V4-Pro」指的是 DeepSeek-V4-Pro Max(擴展推理)模式——也就是透過 Novita 上 deepseek/deepseek-v4-pro API ID 存取的相同模型。
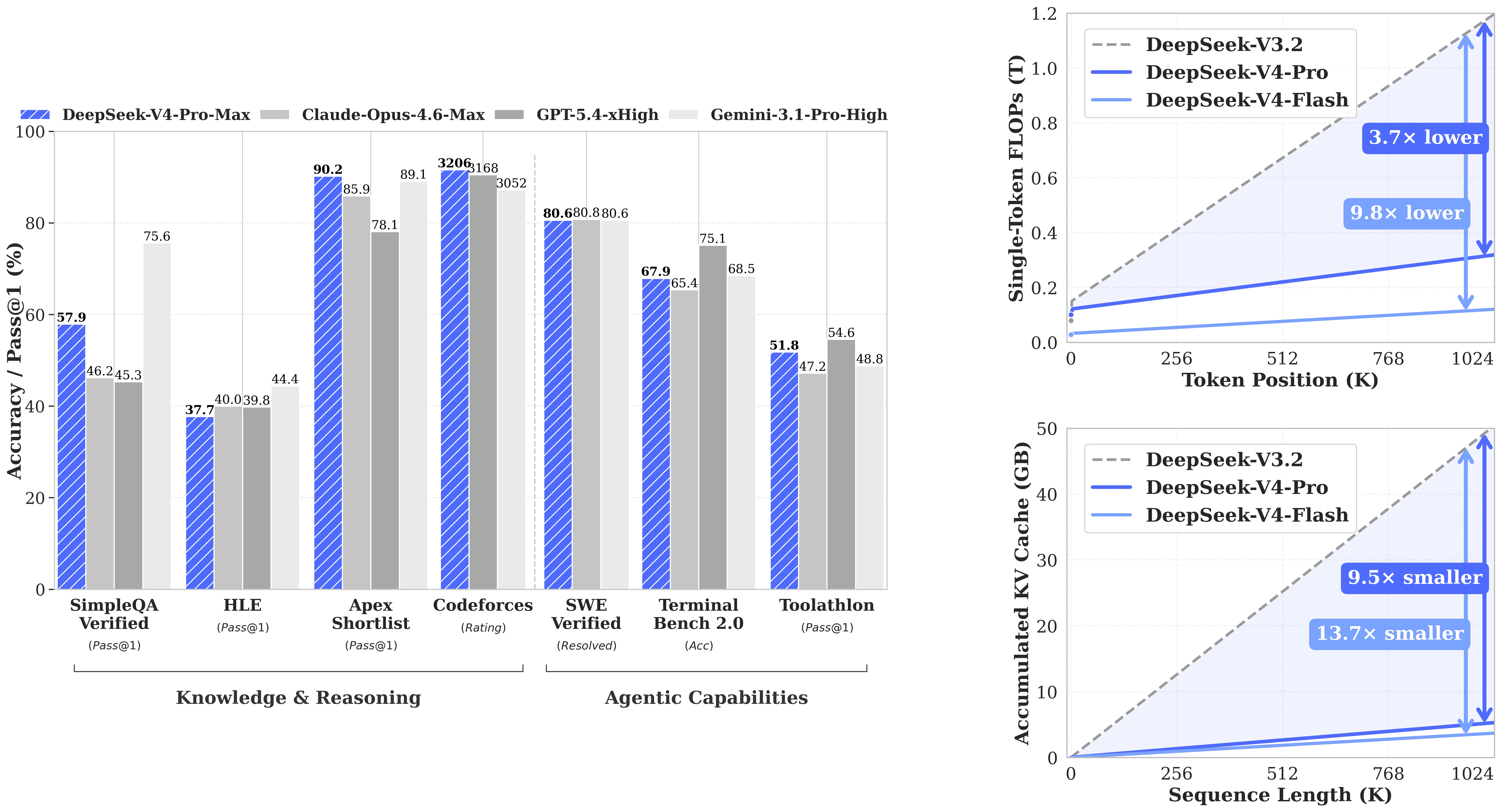
DeepSeek-V4-Pro 在編碼、推理和代理基準測試中的表現。[來源:DeepSeek HuggingFace]
| 基準 | DeepSeek-V4-Pro | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 93.5 ✓ | 88.8 | 91.7 | — |
| Codeforces 評級 | 3206 ✓ | — | 3052 | 3168 |
| SWE-Verified | 80.6 | 80.8 | 80.6 | — |
| SWE Pro | 55.4 | 57.3 | 54.2 | 57.7 |
| BrowseComp | 83.4 | 83.7 | 85.9 | 82.7 |
| MCPAtlas Public | 73.6 | 73.8 | 69.2 | 67.2 |
| GPQA Diamond | 90.1 | 91.3 | 94.3 | 93.0 |
| HLE (Pass@1) | 37.7 | 40.0 | 44.4 | 39.8 |
| IMOAnswerBench | 89.8 | 75.3 | 81.0 | 91.4 |
| HMMT 2026 Feb | 95.2 | 96.2 | 94.7 | 97.7 |
| MRCR 1M (MMR) | 83.5 | 92.9 | 76.3 | — |
| CorpusQA 1M | 62.0 | 71.7 | 53.8 | — |
| Terminal Bench 2.0 | 67.9 | 65.4 | 68.5 | 75.1 |
✓ = 在此比較中公佈的最高分數。最後驗證:2026-04-25。分數反映「Max」/ 擴展推理模式(如適用)。來源:DeepSeek HuggingFace 模型卡。
誠實點評: 在知識基準測試(GPQA Diamond、HLE)上,Gemini 3.1 Pro 和 GPT-5.4 明顯領先。V4-Pro 的優勢在於編碼——LiveCodeBench 和 Codeforces 是明確的第一名——以及在長上下文檢索上優於其他開源模型。在數學推理方面,差距並不一致:V4-Pro 在 IMOAnswerBench 上擊敗了 GPT-5.4(89.8 vs 91.4,接近),但在 HMMT 2026 上落後(95.2 vs 97.7)。
如何使用由 Novita AI 支援的 DeepSeek-V4-Pro
選項 1:Playground(無需程式碼)
直接在 novita.ai/models/model-detail/deepseek-deepseek-v4-pro 測試。無需 API 金鑰即可探索。設定系統提示以啟用 Think 或 Non-think 模式。
選項 2:API(Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
# 標準(Think 模式)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-pro",
messages=[
{"role": "user", "content": "從頭實作一個 Rust 非同步執行環境。"}
],
)
print(response.choices[0].message.content)
在 novita.ai/settings 取得您的 API 金鑰。相同的模型 ID 適用於所有三種推理模式——在系統提示中傳遞模式指令,或使用 DeepSeek 記錄的模式切換語法。
選項 3:第三方工具
由於 Novita AI 與 OpenAI API 相容,您可以將 deepseek/deepseek-v4-pro 作為模型 ID 用於 Cursor(自訂 OpenAI 提供商)、Claude Code 相容設定、LangChain、LlamaIndex 或任何基於 OpenAI SDK 的框架。只需將 base_url 指向 https://api.novita.ai/v3/openai。
curl https://api.novita.ai/v3/openai/chat/completions \
-H "Authorization: Bearer YOUR_NOVITA_API_KEY" \
-H "Content-Type: application/json" \
-d '{"model":"deepseek/deepseek-v4-pro","messages":[{"role":"user","content":"實作一個 Rust 非同步執行環境。"}]}'
使用案例
完整程式碼庫分析與重構: 憑藉 1M token 的上下文,您可以一次傳入整個中型儲存庫。要求 V4-Pro 找出架構問題、產生遷移指南,或同時重構 50 多個檔案的模式——無需分塊或檢索技巧。
競賽程式設計與困難演算法問題: Codeforces 評級 3206 使 V4-Pro 處於演算法問題解決的頂尖行列。用它來產生競賽程式設計挑戰問題的解決方案、驗證複雜性證明,或對生產演算法中的邊界案例進行壓力測試。
GitHub 問題解決代理: SWE-Verified 80.6 使 V4-Pro 在實際錯誤修復上與 Claude Opus 4.6 相當。結合函數呼叫和長上下文,它可以閱讀問題描述、瀏覽程式碼歷史,並在大型儲存庫中生成補丁而不會失去追蹤。
長文件推理: 法律合約、研究論文、技術規格、稽核日誌——V4-Pro 的 1M 上下文意味著您不必在分析前強制總結或分塊。CorpusQA 1M (62.0) 和 MRCR 1M (83.5) 證實在完整上下文長度下檢索準確性仍然有效。
數學與科學輔導/問題生成: IMOAnswerBench 89.8(擊敗除了 GPT-5.4 的 91.4 之外的所有封閉模型)使 V4-Pro 成為生成競賽級別數學問題、驗證證明或建立以數學推理為瓶頸的 STEM 教育工具的強大選擇。
定價
| 模型 | 輸入 ($/M tokens) | 快取讀取 ($/M tokens) | 輸出 ($/M tokens) |
|---|---|---|---|
| DeepSeek-V4-Pro (Novita) | $1.74 | $0.145 | $3.48 |
| DeepSeek-V4-Flash (Novita) | $0.10 | — | $0.50 |
| Claude Opus 4.6 (Anthropic) | $15.00 | $1.50 | $75.00 |
| Gemini 3.1 Pro (Google) | $1.25 | $0.31 | $10.00 |
| GPT-5.4 (OpenAI) | $10.00 | $2.50 | $40.00 |
最後驗證:2026-04-25。Novita 定價來自 novita.ai/pricing。競爭對手定價:Claude 來自 anthropic.com(未驗證),Gemini 來自 ai.google.dev(未驗證),GPT-5.4 來自 platform.openai.com(未驗證)。
透過 Novita AI,V4-Pro 在輸入 token 上大約比 Claude Opus 4.6 便宜 8 倍,在輸出上便宜 21 倍。與 Gemini 3.1 Pro 相比,輸入定價相似,但輸出便宜 2.9 倍。對於具有長上下文和多輪會話的編碼代理——輸出 token 佔據成本主導——差距會迅速放大。
從 DeepSeek-V3 或 DeepSeek-R1 遷移
如果您目前正在 Novita 上執行 DeepSeek-V3 或 R1,升級到 V4-Pro 只需更改一行模型 ID。API 與 OpenAI 相容,相同的端點,相同的請求格式。V4-Pro 的三種推理模式讓您只需一個模型即可複製 V3(非思考模式)和 R1 風格的深度推理(Max 模式),而無需維護單獨的部署。如果您要從其他提供商的模型(GPT-4o、Claude 3.5 等)遷移,只需將現有的 OpenAI SDK 客戶端指向 base_url="https://api.novita.ai/v3/openai" 並交換模型 ID。
結論
總結: DeepSeek-V4-Pro 是目前可用於編碼任務的最強開源模型,在 LiveCodeBench 和 Codeforces 上擁有明確的第一名分數,並且是同級別中唯一能處理真正 1M token 上下文視窗的模型。它並非在所有基準測試中領先——Gemini 3.1 Pro 在知識回憶方面佔優,Claude Opus 在長上下文檢索方面領先——但對於開發編碼代理、大規模修復 GitHub 問題或處理大量文件的團隊,V4-Pro 以封閉模型 API 成本的一小部分提供了前沿級性能。現已由 Novita AI 支援推出——提供 200 多個模型 API 和 OpenAI 相容基礎設施。
立即透過 Novita AI 試用 DeepSeek-V4-Pro →
常見問題
什麼是 DeepSeek-V4-Pro?
DeepSeek-V4-Pro 是 DeepSeek AI 於 2026 年 4 月發布的一個 1.6 兆參數的混合專家語言模型。每次前向傳播激活 49B 參數,支援 1,048,576 個 token 的上下文,目前在 LiveCodeBench(93.5)和 Codeforces 評級(3206)方面領先所有公開評估的模型。它採用 MIT 許可證發布,並可透過 Novita AI 取得。
如何透過 API 存取 DeepSeek-V4-Pro?
使用模型 ID deepseek/deepseek-v4-pro,搭配 base_url="https://api.novita.ai/v3/openai" 以及來自 novita.ai/settings 的 Novita API 金鑰。端點與 OpenAI SDK 相容——無需自訂 SDK。
DeepSeek-V4-Pro 與 Claude Opus 4.6 和 Gemini 3.1 Pro 相比如何?
V4-Pro 在編碼方面領先:LiveCodeBench 93.5(對比 Opus 4.6 的 88.8 和 Gemini 的 91.7)以及 Codeforces 3206(對比 Gemini 的 3052)。在 GPQA Diamond 和 HLE 等知識基準測試方面,Gemini 3.1 Pro 領先。在長上下文檢索(MRCR 1M)方面,Claude Opus 領先。V4-Pro 是編碼密集型和工作負載密集型任務的最佳開源選擇——封閉模型在原始事實回憶方面仍保持優勢。
DeepSeek-V4-Pro 的上下文視窗是多少?
1,048,576 個 token(1M)。該模型專門使用混合注意力(CSA + HCA)架構以實現長上下文效率。MRCR 1M 得分 83.5,CorpusQA 1M 達到 62.0,證實在完整上下文長度下具有可用的檢索準確性。
由 Novita AI 支援的 DeepSeek-V4-Pro 成本是多少?
輸入 $1.74/M tokens,輸出 $3.48/M tokens,快取讀取 $0.145/M tokens。這使其在輸入上大約比 Claude Opus 4.6 便宜 8 倍,在輸出上便宜 21 倍。最後驗證:2026-04-25。



