

- Что такое DeepSeek-V4-Flash?
- Ключевые особенности: почему DeepSeek-V4-Flash выделяется
- Производительность на бенчмарках
- Как использовать DeepSeek-V4-Flash через Novita AI
- Цены
- Рекомендуемые сценарии использования
- Часто задаваемые вопросы
- Начните использовать DeepSeek-V4-Flash уже сегодня
- Рекомендуемые статьи
DeepSeek-V4-Flash от Novita AI: контекст на 1M токенов за $0.14 за миллион
Большинство открытых моделей с возможностями рассуждений вынуждают идти на компромисс: маленькие окна контекста, низкая пропускная способность или цены, которые взлетают выше $1 за миллион токенов, как только вы включаете расширенное мышление. DeepSeek-V4-Flash полностью обходит это — 284B параметров, только 13B активируется при каждом выводе, нативное окно контекста на 1 048 576 токенов и три выбираемых режима рассуждений. При цене $0.14 за миллион входных токенов он попадает в категорию, в которой модели с возможностями рассуждений редко могут конкурировать.
Коротко: DeepSeek-V4-Flash — это модель MoE от DeepSeek AI, которая предоставляет разработчикам контекст на 1M токенов и регулируемую глубину рассуждений без переплаты за закрытые модели. С сегодняшнего дня она доступна через API Novita AI.
Что такое DeepSeek-V4-Flash?
DeepSeek-V4-Flash — это языковая модель смеси экспертов (MoE) от DeepSeek AI, выпущенная как часть серии DeepSeek-V4 вместе с более крупной моделью DeepSeek-V4-Pro. У модели 284B общих параметров, из которых 13B активируется при выводе — это позволяет сохранять низкую стоимость вычислений на токен, сохраняя при этом емкость параметров гораздо более крупной модели.
Ключевые возможности на glance:
- 284B общих / 13B активируемых параметров — архитектура MoE, низкая стоимость вывода
- Окно контекста на 1 048 576 токенов (1M токенов) — реализовано за счет гибридной архитектуры внимания
- Три режима рассуждений: Без рассуждений (быстрый), Рассуждения (пошаговые), Максимальные рассуждения (максимальный бюджет на рассуждения)
- Поддержка вызова функций — использование инструментов, структурированные выводы, режим JSON
- Обучена на 32T+ токенов с многоэтапным пост-обучением (SFT, RL с GRPO, on-policy дистилляция)
- Лицензия MIT — веса модели доступны для скачивания на HuggingFace; разрешено коммерческое использование
- Смешанная точность FP4 + FP8 — веса экспертов MoE в формате FP4, остальные слои в формате FP8
Ключевые особенности: почему DeepSeek-V4-Flash выделяется
Регулируемая глубина рассуждений без переключения моделей
Большинство моделей фиксируют вас в одном режиме вывода: либо с включенными рассуждениями, либо без. DeepSeek-V4-Flash предоставляет три отдельных режима работы на одном и том же конечной точке API:
| Режим | Характеристики | Лучше всего подходит для |
|---|---|---|
| Без рассуждений | Быстрый, без цепочки рассуждений | Задачи с большим объемом, чат, суммаризация |
| Рассуждения | Пошаговые рассуждения, сбалансированный | Сложные вопросы и ответы, генерация кода, анализ |
| Максимальные рассуждения | Максимальный бюджет на рассуждения | Математические соревнования, сложные задачи по программированию, бенчмарки |
Разница между режимами значительна: на бенчмарке GPQA Diamond модель V4-Flash в режиме без рассуждений набирает 71.2 балла, в режиме рассуждений — 87.4, в режиме максимальных рассуждений — 88.1. На LiveCodeBench режим максимальных рассуждений достигает 91.6 против 55.2 в режиме без рассуждений. Вы выбираете соотношение стоимости и качества для каждого запроса — без необходимости изменения инфраструктуры.
Гибридная архитектура внимания для контекста на 1M токенов
Нативное окно контекста на миллион токенов сложнее, чем кажется. DeepSeek-V4-Flash достигает этого за счет специально разработанной гибридной архитектуры внимания, которая сочетает два механизма:
- Сжатое разреженное внимание (CSA) — значительно снижает бюджет вычислений внимания для длинных последовательностей
- Сильно сжатое внимание (HCA) — сжимает объем кэша KV для вывода с контекстом на 1M токенов
Результат: вывод для входных данных объемом 1M токенов с управляемой стоимостью операций с плавающей запятой (FLOP) и памятью. Для рабочих нагрузок таких как анализ кодовой базы, проверка юридических документов или агенты с длинными сессиями эта архитектура определяет разницу между выполнимой и запретительно дорогой задачей.
Эффективность MoE: 13B активируемых параметров при масштабе 284B
Соотношение 284B общих / 13B активируемых параметров — это источник экономической эффективности. Только 13B параметров активны при каждом прямом проходе, что сохраняет задержку и стоимость на токен на уровне плотной модели на 13B параметров — при этом полный пул параметров на 284B обеспечивает емкость знаний, сравнимую с гораздо более крупной плотной сетью. Смешанная точность FP4 + FP8 дополнительно снижает нагрузку на пропускную способность памяти для весов экспертов.
Мощный конвейер пост-обучения
DeepSeek-V4-Flash использует двухэтапный процесс пост-обучения: сначала выращивание доменных экспертов с помощью SFT и обучения с подкреплением с GRPO; затем унифицированная консолидация модели с помощью on-policy дистилляции. Это дает единую модель с дифференцированными профилями возможностей в областях программирования, рассуждений и общих знаний — а не универсальную модель, следующую инструкциям.
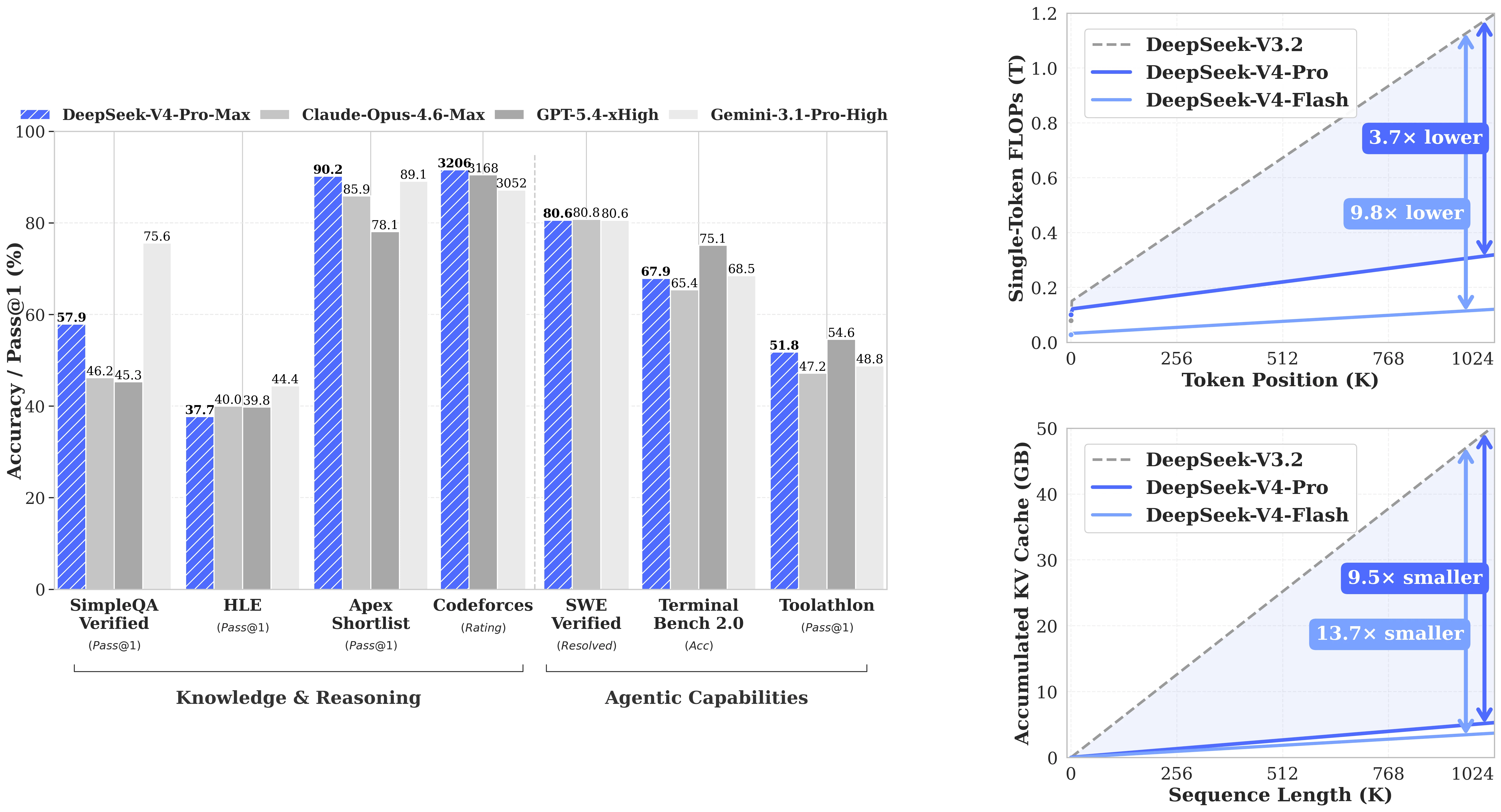
Производительность на бенчмарках
История производительности DeepSeek-V4-Flash на бенчмарках связана с выбором режима рассуждений. В режиме без рассуждений она ведет себя как эффективная модель с 13B активируемых параметров. При переключении на режим максимальных рассуждений она достигает совершенно другого уровня.
Производительность DeepSeek-V4-Flash в разных режимах в сравнении с передовыми моделями [Источник: DeepSeek AI / HuggingFace]
Производительность в разных режимах рассуждений
Ниже приведены результаты V4-Flash на ключевых бенчмарках в сравнении всех трех режимов работы:
| Бенчмарк | V4-Flash без рассуждений | V4-Flash с рассуждениями | V4-Flash с максимальными рассуждениями |
|---|---|---|---|
| LiveCodeBench (Pass@1) | 55.2 | 88.4 | 91.6 |
| GPQA Diamond (Pass@1) | 71.2 | 87.4 | 88.1 |
| HMMT 2026 Feb (Pass@1) | 40.8 | 91.9 | 94.8 |
| IMOAnswerBench (Pass@1) | 41.9 | 85.1 | 88.4 |
| Рейтинг Codeforces | — | 2816 | 3052 |
| SWE Verified (Решено) | 73.7 | 78.6 | 79.0 |
| MRCR 1M (MMR) | 37.5 | 76.9 | 78.7 |
| MCPAtlas (Pass@1) | 64.0 | 67.4 | 69.0 |
| MMLU-Pro (EM) | 83.0 | 86.4 | 86.2 |
Последняя проверка: 2026-04-27. Источник: технический отчет DeepSeek-V4 и карточка модели на HuggingFace.
Сравнение V4-Flash с конкурентами
V4-Flash в режиме максимальных рассуждений (79.0 SWE Verified, 91.6 LiveCodeBench) конкурирует с моделями, имеющими значительно более высокую стоимость на токен. Она не занимает первое место во всех рейтингах — V4-Pro Max лидирует на большинстве передовых бенчмарков — но для разработчиков, которые смотрят на стоимость на задачу, а не на сырую пиковую производительность, это компромисс выгоден:
| Бенчмарк | V4-Flash Max | V4-Pro Max | Claude Opus 4.6 Max | Gemini 3.1 Pro High |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 91.6 | 93.5 | 88.8 | 91.7 |
| GPQA Diamond (Pass@1) | 88.1 | 90.1 | 91.3 | 94.3 |
| SWE Verified (Решено) | 79.0 | 80.6 | 80.8 | 80.6 |
| HMMT 2026 Feb (Pass@1) | 94.8 | 95.2 | 96.2 | 94.7 |
| MRCR 1M (MMR) | 78.7 | 83.5 | 92.9 | 76.3 |
Последняя проверка: 2026-04-27. Показатели Claude Opus 4.6 Max и Gemini 3.1 Pro High взяты из технического отчета DeepSeek-V4 (таблица сравнения передовых моделей V4-Pro). Эти показатели не измерялись в прямом сравнении с V4-Flash в этом отчете.
Примечательно, что V4-Flash в режиме максимальных рассуждений на MRCR 1M (78.7) превосходит Gemini 3.1 Pro High (76.3) на задаче поиска по длинному контексту — это бенчмарк, который наиболее прямо соответствует сценариям использования с контекстом на 1M токенов. На SWE Verified все четыре модели находятся в диапазоне 79–81, что делает V4-Flash конкурентоспособной в категории реальных агентов для программирования при доле цены закрытых моделей.
Как использовать DeepSeek-V4-Flash через Novita AI
Вариант 1: Песочница (без написания кода)
Протестируйте модель прямо в браузере в консоли моделей Novita AI. Для начала не требуется API-ключ — переключайтесь между режимами без рассуждений, с рассуждениями и с максимальными рассуждениями через интерфейс чата.
Вариант 2: API (Python)
DeepSeek-V4-Flash использует API, совместимый с OpenAI. Используйте идентификатор модели deepseek/deepseek-v4-flash с базовым URL Novita:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Your prompt here"}]
)
print(response.choices[0].message.content)
Чтобы включить режим с рассуждениями или максимальными рассуждениями, передайте параметр reasoning в теле запроса:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
# Think Max mode — maximum reasoning budget
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Solve: x^4 - 5x^2 + 4 = 0"}],
extra_body={"reasoning": {"effort": "high"}} # "low" = Think, "high" = Think Max
)
print(response.choices[0].message.content)
Получите ваш API-ключ на novita.ai/settings.
Вариант 3: Сторонние инструменты
Поскольку Novita AI предоставляет конечную точку, совместимую с OpenAI, DeepSeek-V4-Flash работает сразу с:
- LangChain / LlamaIndex — используйте
ChatOpenAIс параметромbase_url="https://api.novita.ai/v3/openai" - OpenWebUI — добавьте как пользовательскую конечную точку, совместимую с OpenAI
- Continue.dev / Cursor — настройте как пользовательскую модель с базовым URL Novita
Цены
Цены на DeepSeek-V4-Flash одинаковы у всех крупных провайдеров. Все показатели указаны за миллион токенов, актуальны на 2026-04-27:
| Провайдер | Вход ($/M) | Выход ($/M) | Чтение из кэша ($/M) | Максимальный контекст |
|---|---|---|---|---|
| Novita AI | $0.14 | $0.28 | $0.028 | 1 048 576 токенов |
| Официальный DeepSeek | $0.14 | $0.28 | $0.028 | 131 072 токенов |
| SiliconFlow | $0.14 | $0.28 | $0.028 | 65 536 токенов |
| DeepInfra | $0.14 | $0.28 | — | 16 384 токенов |
Стоимость на токен везде одинакова — но максимальный контекст значительно отличается. Novita AI предоставляет полное окно контекста на 1M токенов. У DeepInfra лимит составляет 16 384 токенов. Если ваша рабочая нагрузка связана с длинными документами, кодовыми базами или многоходовыми агентами, Novita является практическим выбором.
Рекомендуемые сценарии использования
Автономные агенты для программирования
Окно контекста V4-Flash на 1M токенов означает, что агент может загрузить всю кодовую базу в контекст без разбиения на части. В сочетании с результатом 79.0 SWE Verified в режиме максимальных рассуждений он справляется с рефакторингом нескольких файлов и отладкой без потери состояния между ходами.
Вопросы и ответы по длинным документам и RAG
MRCR 1M (многоходовый поиск по контексту) на 78.7% в режиме максимальных рассуждений — этот бенчмарк измеряет точность поиска в реальном окне контекста на 1M токенов. Для индексации юридических документов, научных работ или длинных технических спецификаций V4-Flash обеспечивает точный поиск там, где большинство моделей деградируют после 32K токенов.
Рассуждения в области математики и естественных наук
94.8% на HMMT 2026 февраля (олимпиадная математика) в режиме максимальных рассуждений. Режим рассуждений с бюджетом позволяет регулировать соотношение стоимости и точности — используйте режим рассуждений для стандартных задач, режим максимальных рассуждений для сложных. Один запрос не сжигает фиксированный бюджет вычислений; выбор за вами.
Продакшн API с кэшированием
При цене $0.028 за миллион чтений из кэша повторяющиеся системные промпты и схемы инструментов фактически не стоят ничего при масштабировании. Продукты в виде чат-ботов и API-обертки, которые повторно внедряют один и тот же контекст при каждом вызове, выигрывают от цены на чтение из кэша по сравнению с ценой на сырые входные данные.
Часто задаваемые вопросы
Что такое DeepSeek-V4-Flash?
DeepSeek-V4-Flash — это языковая модель смеси экспертов на 284B параметров, разработанная DeepSeek AI, выпущенная 2026-04-23. Она активирует только 13B параметров при каждом прямом проходе, что делает ее значительно быстрее и дешевле плотных моделей сопоставимой производительности. Она поддерживает окно контекста на 1 048 576 токенов и три режима рассуждений: без рассуждений (быстрый), рассуждения с бюджетом и расширенные рассуждения (Think Max).
Чем DeepSeek-V4-Flash отличается от DeepSeek-V4-Pro?
V4-Flash — это более легкая, быстрая версия, оптимизированная для скорости и стоимости. V4-Pro — это флагманская модель с более высокими пиковыми показателями на бенчмарках (например, 93.5 против 91.6 на LiveCodeBench в режиме Think Max). V4-Flash «достигает сопоставимой производительности в рассуждениях с версией Pro при большем бюджете на рассуждения» — на практике V4-Flash в режиме Think Max закрывает большую часть разрыва с V4-Pro в режиме Think Max при более низкой стоимости на токен.
Что означает «Flash» в названии модели?
Flash указывает на оптимизированную по скорости версию, аналогично тому, как Google использует этот термин для Gemini Flash. DeepSeek-V4-Flash отдает приоритет более низкой задержке и стоимости перед сырой максимальной точностью, при этом режимы рассуждений доступны, когда вам нужно закрыть разрыв в производительности.
Поддерживает ли DeepSeek-V4-Flash окно контекста на 1M токенов через Novita AI?
Да. Novita AI предоставляет полное окно контекста на 1 048 576 токенов — самое большое среди всех текущих провайдеров для этой модели. Максимальное количество токенов в завершении на Novita составляет 393 216.
Как переключать режимы рассуждений через API?
Передайте параметр extra_body={"reasoning": {"effort": "low"}} для режима рассуждений с бюджетом, или "effort": "high" для режима максимальных рассуждений. Полностью опустите параметр для режима без рассуждений (быстрого). API совместим с OpenAI — изменения в SDK не требуются.
Каковы цены на DeepSeek-V4-Flash через Novita AI?
Актуально на 2026-04-27: $0.14 за миллион входных токенов, $0.28 за миллион выходных токенов, $0.028 за миллион токенов чтения из кэша. Это соответствует официальным ценам DeepSeek и одинаково у всех провайдеров — отличительная особенность Novita — это полное окно контекста на 1M токенов и надежная работа.
Является ли DeepSeek-V4-Flash открытым исходным кодом?
Да. Веса модели доступны на HuggingFace под лицензией MIT — это подтверждено в официальном репозитории DeepSeek-V4. Самостоятельный хостинг и коммерческое использование разрешены в соответствии с условиями MIT. Использование через API Novita AI не требует никакого самостоятельного хостинга.
Начните использовать DeepSeek-V4-Flash уже сегодня
DeepSeek-V4-Flash теперь доступен через Novita AI с полным окном контекста на 1M токенов, конкурентоспособными ценами и нулевыми затратами на инфраструктуру. Вы выбираете режим рассуждений; Novita берет на себя все остальное.
→ Попробуйте DeepSeek-V4-Flash от Novita AI
→ Документация по API LLM Novita AI



