

Novita AI 支持的 DeepSeek-V4-Flash:1M 上下文窗口,输入仅 $0.14/百万 token
大多数具备推理能力的开源模型都要求用户做取舍:要么上下文窗口小,要么吞吐量低,要么一开启扩展推理,价格就飙升至每百万 token 超过 1 美元。DeepSeek-V4-Flash 完全规避了这些痛点——总参数 284B,每次推理仅激活 13B 参数,原生支持 1,048,576 token 的上下文窗口,还提供三种可切换的推理模式。输入价格仅需 $0.14/百万 token,在推理类模型中几乎找不到同价位竞品。
简而言之:DeepSeek-V4-Flash 是 DeepSeek AI 推出的 MoE 模型,为需要高吞吐量、又不想支付闭源模型高额费用的开发者,带来了 1M token 上下文窗口和可调节的推理深度。从今天起,用户已可通过 Novita AI API 使用该模型。
什么是 DeepSeek-V4-Flash?
DeepSeek-V4-Flash 是 DeepSeek AI 推出的混合专家(MoE)语言模型,属于 DeepSeek-V4 系列,与更大的 DeepSeek-V4-Pro 同期发布。该模型总参数达 284B,推理时仅激活 13B 参数——在保持大模型参数容量的同时,将单 token 计算成本控制在极低水平。
核心能力一览:
- 总参数 284B / 推理激活 13B — MoE 架构,推理成本低
- 1,048,576 token 上下文窗口(1M token)— 由混合注意力架构实现
- 三种推理模式: 无思考(快速)、思考(分步推理)、思考最大化(最高推理预算)
- 支持函数调用 — 工具调用、结构化输出、JSON 模式
- 基于 32T+ token 训练,采用多阶段后训练流程(SFT、基于 GRPO 的强化学习、同策略蒸馏)
- MIT 许可证 — 权重可在 HuggingFace 下载,允许商用
- FP4 + FP8 混合精度 — MoE 专家权重采用 FP4,其余层采用 FP8
核心优势:DeepSeek-V4-Flash 为何脱颖而出
无需切换模型即可选择推理深度
大多数模型仅支持单一推理模式:要么开启推理,要么关闭。DeepSeek-V4-Flash 在同一个 API 端点下提供三种不同的运行模式:
| 模式 | 特性 | 适用场景 |
|---|---|---|
| 无思考模式 | 速度快,无思维链 | 高吞吐量任务、对话、摘要生成 |
| 思考模式 | 分步推理,平衡速度与质量 | 复杂问答、代码生成、分析任务 |
| 思考最大化模式 | 最高推理预算 | 数学竞赛、高难度编码任务、基准测试 |
不同模式的性能差距非常显著:在 GPQA Diamond 测试中,V4-Flash 无思考模式得分 71.2,思考模式为 87.4,思考最大化模式为 88.1。在 LiveCodeBench 测试中,思考最大化模式得分达 91.6,而无思考模式仅为 55.2。你可以根据每次请求的需求在成本和效果之间做选择,无需调整任何基础设施。
混合注意力架构实现 1M token 上下文窗口
原生支持百万 token 上下文比听起来难得多。DeepSeek-V4-Flash 通过专门设计的混合注意力架构实现了这一目标,该架构结合了两种机制:
- 压缩稀疏注意力(CSA) — 大幅降低长序列的注意力计算开销
- 高度压缩注意力(HCA) — 压缩 KV 缓存占用,支持 1M 上下文推理
最终效果是:处理 1M token 输入时,推理的浮点运算次数(FLOP)和内存成本都处于可控范围。对于代码库分析、法律文档审阅、长会话智能体等场景,该架构直接决定了任务是否可行。
MoE 效率:284B 参数规模下仅激活 13B
284B/13B 的激活比例正是其成本效率的来源。每次前向传播仅激活 13B 参数,使得延迟和单 token 成本接近 13B 参数的稠密模型——而完整的 284B 参数池提供了与更大规模稠密网络相当的知识容量。FP4 + FP8 混合精度进一步降低了专家权重的内存带宽压力。
强大的后训练流程
DeepSeek-V4-Flash 采用两阶段后训练流程:首先通过 SFT 和基于 GRPO 的强化学习进行领域专属专家培养;然后通过同策略蒸馏完成统一模型整合。最终产出的单一模型在编码、推理和通用知识领域具备差异化的能力表现,而非通用的指令跟随模型。
基准测试表现
DeepSeek-V4-Flash 的基准测试表现核心在于推理模式的选择。在无思考模式下,它的表现和高效的 13B 激活模型相当;切换到思考最大化模式后,则会完全跃升至另一个性能层级。
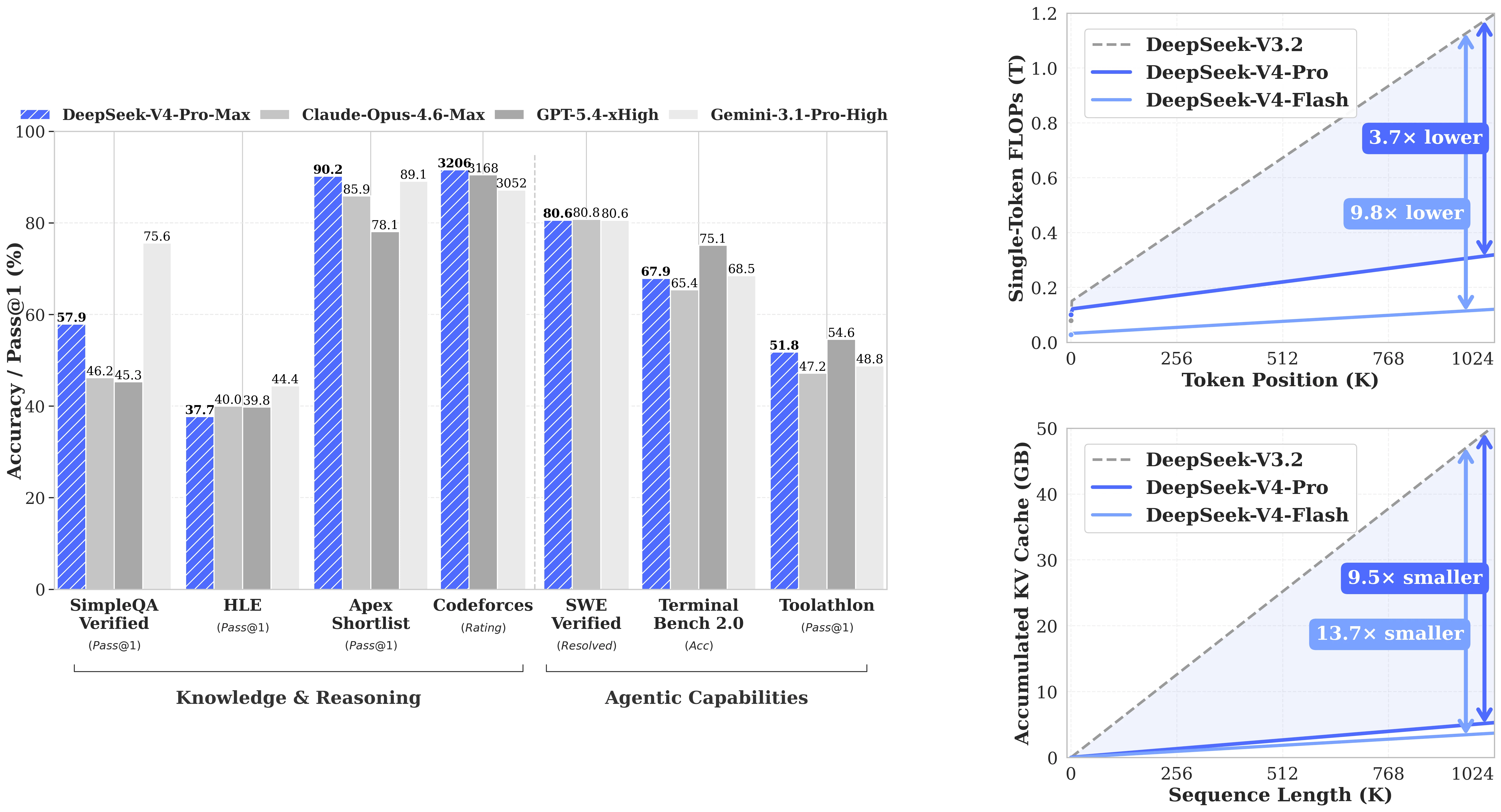
DeepSeek-V4-Flash 各模式性能对比前沿模型 [来源:DeepSeek AI / HuggingFace]
各推理模式性能表现
以下是 V4-Flash 在关键基准测试中的得分,对比了全部三种运行模式:
| 基准测试 | V4-Flash 无思考 | V4-Flash 思考 | V4-Flash 思考最大化 |
|---|---|---|---|
| LiveCodeBench (Pass@1) | 55.2 | 88.4 | 91.6 |
| GPQA Diamond (Pass@1) | 71.2 | 87.4 | 88.1 |
| HMMT 2026 年 2 月 (Pass@1) | 40.8 | 91.9 | 94.8 |
| IMOAnswerBench (Pass@1) | 41.9 | 85.1 | 88.4 |
| Codeforces 评分 | — | 2816 | 3052 |
| SWE Verified (已解决) | 73.7 | 78.6 | 79.0 |
| MRCR 1M (MMR) | 37.5 | 76.9 | 78.7 |
| MCPAtlas (Pass@1) | 64.0 | 67.4 | 69.0 |
| MMLU-Pro (EM) | 83.0 | 86.4 | 86.2 |
最后验证时间:2026-04-27。来源:DeepSeek-V4 技术报告与 HuggingFace 模型卡片。
V4-Flash 与竞品对比
V4-Flash 思考最大化模式(SWE Verified 79.0 分,LiveCodeBench 91.6 分)的表现足以媲美单 token 成本高得多的模型。它并非所有基准测试都排名第一——V4-Pro Max 在多数前沿基准测试中领先——但对于关注单任务成本而非原始峰值性能的开发者来说,这种取舍非常划算:
| 基准测试 | V4-Flash 最大值 | V4-Pro Max | Claude Opus 4.6 Max | Gemini 3.1 Pro 高配版 |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 91.6 | 93.5 | 88.8 | 91.7 |
| GPQA Diamond (Pass@1) | 88.1 | 90.1 | 91.3 | 94.3 |
| SWE Verified (已解决) | 79.0 | 80.6 | 80.8 | 80.6 |
| HMMT 2026 年 2 月 (Pass@1) | 94.8 | 95.2 | 96.2 | 94.7 |
| MRCR 1M (MMR) | 78.7 | 83.5 | 92.9 | 76.3 |
最后验证时间:2026-04-27。Claude Opus 4.6 Max 和 Gemini 3.1 Pro 高配版的分数来自 DeepSeek-V4 技术报告(V4-Pro 前沿对比表格)。这些分数并非在该报告中与 V4-Flash 进行头对头测试得出的。
值得注意的是,V4-Flash 思考最大化模式在 MRCR 1M(78.7 分)的长上下文检索任务中超过了 Gemini 3.1 Pro 高配版(76.3 分)——该基准测试最直接对应 1M 上下文的使用场景。在 SWE Verified 测试中,四款模型的得分都集中在 79-81 分区间,使得 V4-Flash 在真实编码智能体场景中,以远低于闭源模型的价格具备了竞争力。
如何通过 Novita AI 使用 DeepSeek-V4-Flash
选项 1:在线 playground(无需代码)
你可以在浏览器中直接访问 Novita AI 模型控制台 测试该模型。无需 API 密钥即可开始使用,通过聊天界面即可切换无思考、思考、思考最大化三种模式。
选项 2:API(Python)
DeepSeek-V4-Flash 采用兼容 OpenAI 的 API。使用模型 ID deepseek/deepseek-v4-flash,配合 Novita 的基础 URL 即可:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Your prompt here"}]
)
print(response.choices[0].message.content)
如需开启思考或思考最大化模式,在请求体中传入 reasoning 参数即可:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
# Think Max mode — maximum reasoning budget
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Solve: x^4 - 5x^2 + 4 = 0"}],
extra_body={"reasoning": {"effort": "high"}} # "low" = Think, "high" = Think Max
)
print(response.choices[0].message.content)
你可以在 novita.ai/settings 获取你的 API 密钥。
选项 3:第三方工具
由于 Novita AI 提供的是兼容 OpenAI 的端点,DeepSeek-V4-Flash 可以开箱即用支持以下工具:
- LangChain / LlamaIndex — 使用
ChatOpenAI并设置base_url="https://api.novita.ai/v3/openai"即可 - OpenWebUI — 添加为自定义 OpenAI 兼容端点即可
- Continue.dev / Cursor — 配置为自定义模型,使用 Novita 基础 URL 即可
定价
DeepSeek-V4-Flash 在各主流服务商处的定价一致。以下均为每百万 token 的价格,统计时间为 2026-04-27:
| 服务商 | 输入($/百万) | 输出($/百万) | 缓存读取($/百万) | 最大上下文 |
|---|---|---|---|---|
| Novita AI | $0.14 | $0.28 | $0.028 | 1,048,576 tokens |
| DeepSeek 官方 | $0.14 | $0.28 | $0.028 | 131,072 tokens |
| SiliconFlow | $0.14 | $0.28 | $0.028 | 65,536 tokens |
| DeepInfra | $0.14 | $0.28 | — | 16,384 tokens |
各服务商的单 token 定价完全相同,但最大上下文长度差异巨大。Novita AI 提供完整的 1M token 上下文窗口,而 DeepInfra 仅支持 16,384 token。如果你的工作负载涉及长文档、代码库或多轮智能体,Novita 是更实用的选择。
推荐使用场景
自主编码智能体
V4-Flash 的 1M 上下文窗口意味着智能体可以将整个代码库载入上下文,无需分块处理。搭配思考最大化模式下 79.0 分的 SWE Verified 成绩,它可以处理多文件重构和调试任务,且在多轮交互中不会丢失状态。
长文档问答与 RAG
MRCR 1M(多轮上下文检索)在思考最大化模式下得分 78.7%——该基准测试衡量的是真实 1M token 窗口内的检索准确率。对于法律文档、学术论文或长技术规格的索引场景,V4-Flash 在大多数模型超过 32K token 后性能下降的区间,仍能保持准确的检索效果。
数学与科学推理
在 2026 年 2 月 HMMT(竞赛数学)测试中,思考最大化模式得分达 94.8%。预算推理模式允许你根据需求调整成本与准确率——普通问题使用思考模式,高难度问题使用思考最大化模式。单次请求不会消耗固定的计算预算,完全由你自主选择。
带缓存的生产级 API
缓存读取价格仅为 $0.028/百万 token,大规模场景下重复使用的系统提示和工具 schema 几乎零成本。每次调用都会重新注入相同上下文的聊天机器人产品和 API 封装工具,使用缓存读取定价比原始输入定价划算得多。
常见问题
什么是 DeepSeek-V4-Flash?
DeepSeek-V4-Flash 是 DeepSeek AI 开发的 284B 参数混合专家语言模型,发布于 2026-04-23。每次前向传播仅激活 13B 参数,比能力相近的稠密模型速度快得多、成本低得多。它支持 1,048,576 token 的上下文窗口,以及三种推理模式:无思考(快速)、预算推理、扩展推理(思考最大化)。
DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 有什么区别?
V4-Flash 是更轻量、更快的版本,针对速度和成本进行了优化。V4-Pro 是旗舰模型,峰值基准测试得分更高(例如 LiveCodeBench 思考最大化模式下,V4-Pro 得 93.5 分,V4-Flash 为 91.6 分)。DeepSeek 官方表示“当给予更大的推理预算时,V4-Flash 可以达到与 Pro 版本相当的推理性能”——实际使用中,V4-Flash 思考最大化模式以更低的单 token 成本,追平了与 V4-Pro 思考最大化模式的大部分性能差距。
模型名中的「Flash」是什么意思?
「Flash」代表速度优化版本,和 Google 为 Gemini Flash 命名的逻辑一致。DeepSeek-V4-Flash 优先保证低延迟和低成本,而非原始最高准确率,当你需要缩小性能差距时,可以使用推理模式来实现。
Novita AI 支持的 DeepSeek-V4-Flash 是否支持 1M 上下文窗口?
是的。Novita AI 开放了完整的 1,048,576 token 上下文窗口,是当前所有服务商中该模型支持的最大上下文长度。Novita 上的最大补全 token 数为 393,216。
如何通过 API 切换推理模式?
传入 extra_body={"reasoning": {"effort": "low"}} 参数即可开启预算推理模式,传入 "effort": "high" 可开启思考最大化模式。完全省略该参数则为无思考(快速)模式。API 兼容 OpenAI 规范,无需修改 SDK 即可使用。
Novita AI 支持的 DeepSeek-V4-Flash 定价是多少?
截至 2026-04-27:输入 $0.14/百万 token,输出 $0.28/百万 token,缓存读取 $0.028/百万 token。该定价与 DeepSeek 官方定价一致,各服务商价格相同——Novita 的核心差异在于提供完整的 1M 上下文窗口和稳定的服务可用性。
DeepSeek-V4-Flash 是开源模型吗?
是的。该模型权重已在 HuggingFace 以 MIT 许可证 发布,这一信息已在 DeepSeek-V4 官方仓库中确认。MIT 条款允许自行部署和商用。通过 Novita AI 的 API 使用该模型,完全无需自行部署。
立即开始使用 DeepSeek-V4-Flash
DeepSeek-V4-Flash 现已通过 Novita AI 提供服务,支持完整的 1M 上下文窗口,定价具有竞争力,且无需承担任何基础设施成本。你只需选择推理模式,其余工作都由 Novita 处理。
→ 试用 Novita AI 支持的 DeepSeek-V4-Flash



