

DeepSeek-V4-Flash propulsé par Novita AI : Contexte de 1M de tokens à 0,14 $ par million
La plupart des modèles open source dotés de capacités de raisonnement imposent un compromis : fenêtres de contexte réduites, débit faible, ou des prix qui dépassent 1 $ par million de tokens dès que vous activez la réflexion étendue. DeepSeek-V4-Flash contourne entièrement ce problème : 284 milliards de paramètres, seulement 13 milliards activés par inférence, une fenêtre de contexte native de 1 048 576 tokens, et trois modes de raisonnement sélectionnables. À 0,14 $ par million de tokens en entrée, il se place dans une catégorie où les modèles capables de raisonnement concurrencent rarement.
En résumé : DeepSeek-V4-Flash est un modèle MoE de DeepSeek AI qui apporte un contexte de 1 million de tokens et une profondeur de raisonnement ajustable aux développeurs qui ont besoin de débit sans la surcharge tarifaire des modèles propriétaires. Depuis aujourd’hui, il est disponible via l’API Novita AI.
Qu’est-ce que DeepSeek-V4-Flash ?
DeepSeek-V4-Flash est un modèle de langage Mixture-of-Experts (MoE) de DeepSeek AI, publié dans le cadre de la série DeepSeek-V4 aux côtés du modèle plus grand DeepSeek-V4-Pro. Le modèle compte 284 milliards de paramètres au total, avec 13 milliards activés lors de l’inférence, ce qui permet de maintenir un coût de calcul par token faible tout en conservant la capacité paramétrique d’un modèle bien plus grand.
Ses capacités clés en un coup d’œil :
- 284 milliards de paramètres au total / 13 milliards activés — Architecture MoE, coût d’inférence faible
- Fenêtre de contexte de 1 048 576 tokens (1 million de tokens) — Permise par l’architecture d’attention hybride
- Trois modes de raisonnement : Non-think (rapide), Think (étape par étape), Think Max (budget de raisonnement maximal)
- Prise en charge de l’appel de fonctions — Utilisation d’outils, sorties structurées, mode JSON
- Entraîné sur plus de 32 000 milliards de tokens avec un post-entraînement multi-étapes (SFT, RL avec GRPO, distillation sur politique)
- Licence MIT — Les poids sont disponibles en téléchargement sur HuggingFace ; l’usage commercial est autorisé
- Précision mixte FP4 + FP8 — Les poids des experts MoE en FP4, les couches restantes en FP8
Fonctionnalités clés : Pourquoi DeepSeek-V4-Flash se démarque
Profondeur de raisonnement sélectionnable sans changer de modèle
La plupart des modèles vous obligent à utiliser un seul mode d’inférence : soit avec raisonnement, soit sans. DeepSeek-V4-Flash vous propose trois modes de fonctionnement distincts sur le même point d’API :
| Mode | Caractéristiques | Idéal pour |
|---|---|---|
| Non-think | Rapide, pas de chaîne de pensée | Tâches à haut volume, chat, résumé |
| Think | Raisonnement étape par étape, équilibré | Questions-réponses complexes, génération de code, analyse |
| Think Max | Budget de raisonnement maximal | Compétitions de mathématiques, tâches de codage complexes, benchmarks |
L’écart entre les modes est significatif : sur le benchmark GPQA Diamond, le V4-Flash en mode Non-think obtient 71,2 contre 87,4 pour le mode Think et 88,1 pour le mode Think Max. Sur LiveCodeBench, le mode Think Max atteint 91,6 contre 55,2 pour le mode Non-think. Vous choisissez le rapport coût/qualité par requête, sans modification d’infrastructure nécessaire.
Architecture d’attention hybride pour un contexte de 1M de tokens
Un contexte natif d’un million de tokens est plus difficile à mettre en œuvre qu’il n’y paraît. DeepSeek-V4-Flash y parvient grâce à une architecture d’attention hybride spécialement conçue qui combine deux mécanismes :
- Attention éparse compressée (CSA) — Réduit considérablement le budget de calcul d’attention pour les longues séquences
- Attention fortement compressée (HCA) — Réduit l’empreinte du cache KV pour l’inférence sur un contexte de 1M de tokens
Résultat : une inférence sur des entrées de 1 million de tokens avec un coût en FLOP et en mémoire gérable. Pour des charges de travail comme l’analyse de bases de code, la révision de documents juridiques ou des agents sur de longues sessions, cette architecture fait la différence entre ce qui est faisable et ce qui est prohibitif.
Efficacité MoE : 13 milliards de paramètres activés à l’échelle de 284 milliards
C’est le ratio de 284 milliards de paramètres au total pour 13 milliards activés qui permet cette efficacité tarifaire. Seuls 13 milliards de paramètres sont actifs par passage avant, ce qui maintient la latence et le coût par token proches de ceux d’un modèle dense de 13 milliards de paramètres, tandis que l’ensemble des 284 milliards de paramètres offre une capacité de connaissance comparable à celle d’un réseau dense bien plus grand. La précision mixte FP4 + FP8 réduit en outre la pression sur la bande passante mémoire des poids des experts.
Pipeline de post-entraînement performant
DeepSeek-V4-Flash suit un processus de post-entraînement en deux étapes : d’abord, la cultivation d’experts spécialisés par domaine via le SFT (Supervised Fine-Tuning) et l’apprentissage par renforcement avec GRPO ; puis, la consolidation unifiée du modèle par distillation sur politique. Cela produit un modèle unique avec des profils de capacité différenciés en matière de codage, de raisonnement et de connaissances générales, et pas un simple modèle générique d’exécution d’instructions.
Performances aux benchmarks
L’histoire des performances de DeepSeek-V4-Flash aux benchmarks tourne autour du choix du mode de raisonnement. En mode Non-think, il se comporte comme un modèle efficace de 13 milliards de paramètres activés. Passez en mode Think Max et il atteint une catégorie de performance totalement différente.
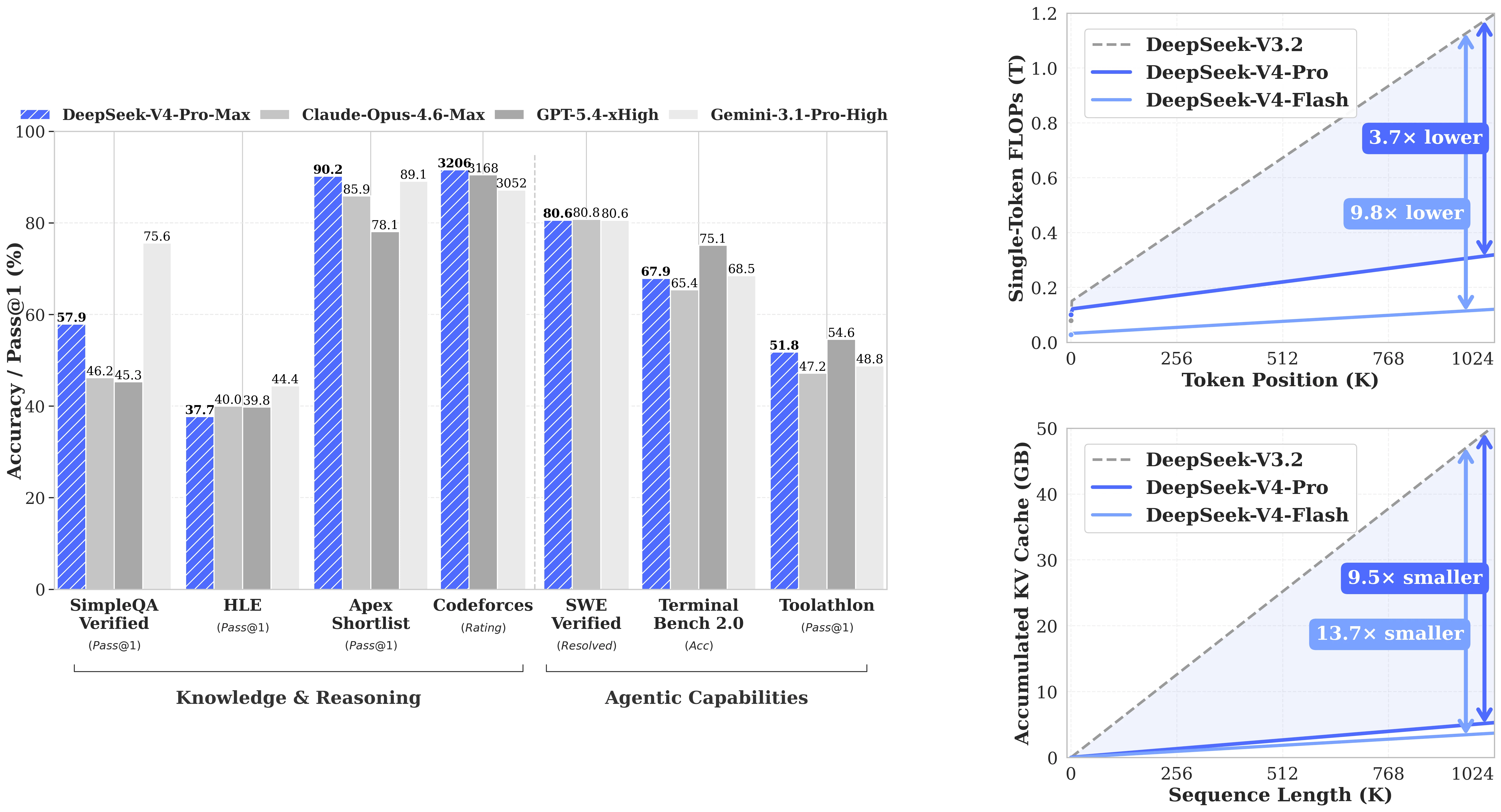
Performances de DeepSeek-V4-Flash selon les modes par rapport aux modèles de pointe [Source : DeepSeek AI / HuggingFace]
Performances selon les modes de raisonnement
Vous trouverez ci-dessous les scores du V4-Flash sur les principaux benchmarks, comparant les trois modes de fonctionnement :
| Benchmark | V4-Flash Non-Think | V4-Flash Think | V4-Flash Think Max |
|---|---|---|---|
| LiveCodeBench (Pass@1) | 55.2 | 88.4 | 91.6 |
| GPQA Diamond (Pass@1) | 71.2 | 87.4 | 88.1 |
| HMMT 2026 Feb (Pass@1) | 40.8 | 91.9 | 94.8 |
| IMOAnswerBench (Pass@1) | 41.9 | 85.1 | 88.4 |
| Codeforces Rating | — | 2816 | 3052 |
| SWE Verified (Resolved) | 73.7 | 78.6 | 79.0 |
| MRCR 1M (MMR) | 37.5 | 76.9 | 78.7 |
| MCPAtlas (Pass@1) | 64.0 | 67.4 | 69.0 |
| MMLU-Pro (EM) | 83.0 | 86.4 | 86.2 |
Dernière vérification : 27/04/2026. Source : Rapport technique DeepSeek-V4 et fiche modèle HuggingFace.
Comment le V4-Flash se compare à ses concurrents
Le V4-Flash en mode Think Max (79,0 sur SWE Verified, 91,6 sur LiveCodeBench) concurrence des modèles dont le coût par token est bien plus élevé. Il n’est pas premier sur tous les classements — le V4-Pro Max est en tête sur la plupart des benchmarks de pointe — mais pour les développeurs qui regardent le coût par tâche plutôt que la performance brute maximale, le compromis est favorable :
| Benchmark | V4-Flash Max | V4-Pro Max | Claude Opus 4.6 Max | Gemini 3.1 Pro High |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 91.6 | 93.5 | 88.8 | 91.7 |
| GPQA Diamond (Pass@1) | 88.1 | 90.1 | 91.3 | 94.3 |
| SWE Verified (Resolved) | 79.0 | 80.6 | 80.8 | 80.6 |
| HMMT 2026 Feb (Pass@1) | 94.8 | 95.2 | 96.2 | 94.7 |
| MRCR 1M (MMR) | 78.7 | 83.5 | 92.9 | 76.3 |
Dernière vérification : 27/04/2026. Les scores de Claude Opus 4.6 Max et Gemini 3.1 Pro High proviennent du rapport technique DeepSeek-V4 (tableau de comparaison des modèles de pointe V4-Pro). Ces scores n’ont pas été mesurés en comparaison directe avec le V4-Flash dans ce rapport.
On notera que le V4-Flash en mode Think Max sur MRCR 1M (78,7) surpasse le Gemini 3.1 Pro High (76,3) sur la tâche de récupération sur long contexte — le benchmark qui correspond le plus directement aux cas d’usage de contexte de 1M de tokens. Sur SWE Verified, les quatre modèles se regroupent entre 79 et 81, ce qui rend le V4-Flash compétitif dans la catégorie des agents de codage réels à une fraction du prix des modèles propriétaires.
Comment utiliser DeepSeek-V4-Flash via Novita AI
Option 1 : Playground (sans code)
Testez le modèle directement dans votre navigateur sur la console de modèles Novita AI. Aucune clé API n’est requise pour commencer — basculez entre les modes Non-think, Think et Think Max via l’interface de chat.
Option 2 : API (Python)
DeepSeek-V4-Flash utilise une API compatible OpenAI. Utilisez l’identifiant de modèle deepseek/deepseek-v4-flash avec l’URL de base Novita :
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Your prompt here"}]
)
print(response.choices[0].message.content)
Pour activer le mode Think ou Think Max, passez le paramètre reasoning dans le corps de la requête :
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
# Think Max mode — maximum reasoning budget
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Solve: x^4 - 5x^2 + 4 = 0"}],
extra_body={"reasoning": {"effort": "high"}} # "low" = Think, "high" = Think Max
)
print(response.choices[0].message.content)
Récupérez votre clé API sur novita.ai/settings.
Option 3 : Outils tiers
Étant donné que Novita AI expose un point d’API compatible OpenAI, DeepSeek-V4-Flash fonctionne immédiatement avec :
- LangChain / LlamaIndex — Utilisez
ChatOpenAIavecbase_url="https://api.novita.ai/v3/openai" - OpenWebUI — Ajoutez-le comme point d’API compatible OpenAI personnalisé
- Continue.dev / Cursor — Configurez-le comme modèle personnalisé avec l’URL de base Novita
Tarification
Le tarif de DeepSeek-V4-Flash est cohérent auprès des principaux fournisseurs. Tous les chiffres sont par million de tokens, au 27/04/2026 :
| Fournisseur | Entrée ($/M) | Sortie ($/M) | Lecture de cache ($/M) | Contexte max |
|---|---|---|---|---|
| Novita AI | 0,14 $ | 0,28 $ | 0,028 $ | 1 048 576 tokens |
| DeepSeek Official | 0,14 $ | 0,28 $ | 0,028 $ | 131 072 tokens |
| SiliconFlow | 0,14 $ | 0,28 $ | 0,028 $ | 65 536 tokens |
| DeepInfra | 0,14 $ | 0,28 $ | — | 16 384 tokens |
Le tarif par token est identique partout — mais le contexte maximal varie considérablement. Novita AI propose la fenêtre de contexte complète de 1 million de tokens. DeepInfra est plafonné à 16 384 tokens. Si votre charge de travail implique des documents longs, des bases de code ou des agents multi-tours, Novita est le choix pratique.
Cas d’usage recommandés
Agents de codage autonomes
La fenêtre de contexte de 1M de tokens du V4-Flash signifie qu’un agent peut charger une base de code entière dans le contexte sans la découper en morceaux. Combiné à un score de 79,0 sur SWE Verified en mode Think Max, il gère les refactorisations multi-fichiers et le débogage sans perdre l’état entre les tours.
Questions-réponses sur documents longs et RAG
MRCR 1M (récupération de contexte multi-tours) à 78,7 % en mode Think Max — ce benchmark mesure la précision de la récupération sur une fenêtre de 1 million de tokens réelle. Pour l’indexation de documents juridiques, d’articles académiques ou de spécifications techniques longues, le V4-Flash récupère les informations avec précision là où la plupart des modèles voient leurs performances se dégrader après 32 000 tokens.
Raisonnement mathématique et scientifique
94,8 % sur le HMMT de février 2026 (mathématiques de compétition) en mode Think Max. Le mode de raisonnement à budget vous permet d’ajuster le rapport coût/précision : utilisez le mode Think pour les problèmes standards, le mode Think Max pour les plus difficiles. Une seule requête ne consomme pas un budget de calcul fixe ; c’est vous qui choisissez.
APIs de production avec mise en cache
À 0,028 $ par million de lectures de cache, les prompts système répétés et les schémas d’outils ne coûtent pratiquement rien à grande échelle. Les produits de chatbot et les wrappers d’API qui réinjectent le même contexte à chaque appel bénéficient du tarif de lecture de cache plutôt que du tarif d’entrée brute.
Foire aux questions
Qu’est-ce que DeepSeek-V4-Flash ?
DeepSeek-V4-Flash est un modèle de langage Mixture-of-Experts de 284 milliards de paramètres développé par DeepSeek AI, publié le 23/04/2026. Il n’active que 13 milliards de paramètres par passage avant, ce qui le rend significativement plus rapide et moins cher que des modèles denses de capacité comparable. Il prend en charge une fenêtre de contexte de 1 048 576 tokens et trois modes de raisonnement : Non-thinking (rapide), Budget Thinking et Extended Thinking (Think Max).
En quoi DeepSeek-V4-Flash diffère-t-il de DeepSeek-V4-Pro ?
Le V4-Flash est la variante plus légère et plus rapide, optimisée pour la vitesse et le coût. Le V4-Pro est le modèle phare avec des scores de benchmark de pointe plus élevés (par exemple 93,5 contre 91,6 sur LiveCodeBench en mode Think Max). Le V4-Flash « obtient des performances de raisonnement comparables à la version Pro lorsqu’on lui donne un budget de réflexion plus important » — en pratique, le V4-Flash en mode Think Max comble la plupart de l’écart avec le V4-Pro en mode Think Max à un coût par token inférieur.
Que signifie « Flash » dans le nom du modèle ?
« Flash » indique une variante optimisée pour la vitesse, conformément à l’utilisation que fait Google de ce terme pour Gemini Flash. DeepSeek-V4-Flash privilégie une latence et un coût plus faibles plutôt que la précision brute maximale, les modes de réflexion étant disponibles lorsque vous avez besoin de combler l’écart de performance.
DeepSeek-V4-Flash prend-il en charge une fenêtre de contexte de 1M de tokens via Novita AI ?
Oui. Novita AI expose la fenêtre de contexte complète de 1 048 576 tokens — la plus grande disponible auprès de tous les fournisseurs actuels pour ce modèle. Le nombre maximal de tokens de complétion sur Novita est de 393 216.
Comment changer de mode de raisonnement via l’API ?
Passez le paramètre extra_body={"reasoning": {"effort": "low"}} pour le mode Budget Thinking, ou "effort": "high" pour le mode Think Max. Omettez entièrement le paramètre pour le mode Non-thinking (rapide). L’API est compatible OpenAI, aucune modification de SDK n’est nécessaire.
Quel est le tarif de DeepSeek-V4-Flash via Novita AI ?
Au 27/04/2026 : 0,14 $ par million de tokens en entrée, 0,28 $ par million de tokens en sortie, 0,028 $ par million de tokens de lecture de cache. Cela correspond aux tarifs officiels de DeepSeek et est cohérent auprès de tous les fournisseurs — le différenciateur de Novita est la fenêtre de contexte complète de 1M de tokens et une disponibilité fiable.
DeepSeek-V4-Flash est-il open source ?
Oui. Les poids du modèle sont disponibles sur HuggingFace sous licence MIT — ceci est confirmé dans le dépôt officiel DeepSeek-V4. L’auto-hébergement et l’usage commercial sont autorisés selon les termes de la licence MIT. L’utiliser via l’API de Novita AI ne nécessite aucun auto-hébergement.
Commencez à utiliser DeepSeek-V4-Flash dès aujourd’hui
DeepSeek-V4-Flash est désormais disponible via Novita AI avec la fenêtre de contexte complète de 1M de tokens, des tarifs compétitifs et aucun surcoût d’infrastructure. Vous choisissez le mode de raisonnement ; Novita s’occupe du reste.
→ Essayez DeepSeek-V4-Flash propulsé par Novita AI
→ Documentation de l’API LLM Novita AI



