

Novita AI가 지원하는 DeepSeek-V4-Flash: 토큰당 $0.14/M에 100만 컨텍스트
대부분의 추론 기능을 갖춘 오픈소스 모델은 트레이드오프를 강제합니다. 작은 컨텍스트 창, 느린 처리량, 또는 확장 사고를 활성화하는 즉시 토큰당 $1/M 이상으로 치솟는 가격이 그것입니다. DeepSeek-V4-Flash는 이러한 문제를 완전히 우회합니다. 284B 파라미터, 추론당 13B만 활성화, 기본 1,048,576 토큰 컨텍스트 창, 세 가지 선택 가능한 추론 모드를 제공합니다. 입력 토큰당 $0.14/M의 가격으로, 추론이 가능한 모델이 거의 경쟁하지 못하는 범주에 자리 잡고 있습니다.
요약: DeepSeek-V4-Flash는 DeepSeek AI의 MoE 모델로, 폐쇄형 모델의 프리미엄 가격 없이 처리량이 필요한 개발자에게 100만 토큰 컨텍스트와 조정 가능한 추론 깊이를 제공합니다. 현재 Novita AI API를 통해 사용할 수 있습니다.
DeepSeek-V4-Flash란 무엇인가요?
DeepSeek-V4-Flash는 DeepSeek AI가 개발한 Mixture-of-Experts (MoE) 언어 모델로, 더 큰 DeepSeek-V4-Pro와 함께 DeepSeek-V4 시리즈의 일부로 출시되었습니다. 이 모델은 총 284B 파라미터를 가지며 추론 시 13B만 활성화되어 토큰당 연산 비용을 낮게 유지하면서도 훨씬 더 큰 모델의 파라미터 용량을 유지합니다.
주요 기능 요약:
- 284B 총 / 13B 활성화 파라미터 — MoE 아키텍처, 낮은 추론 비용
- 1,048,576 토큰 컨텍스트 창 (100만 토큰) — 하이브리드 어텐션 아키텍처 지원
- 세 가지 추론 모드: 비추론(빠름), 추론(단계별), 최대 추론(최대 추론 예산)
- 함수 호출 지원 — 도구 사용, 구조화된 출력, JSON 모드
- 32T+ 토큰 학습 및 다단계 사후 학습(SFT, GRPO를 사용한 RL, 온폴리시 증류)
- MIT 라이선스 — HuggingFace에서 가중치 다운로드 가능; 상업적 사용 허용
- FP4 + FP8 혼합 정밀도 — MoE 전문가 가중치는 FP4, 나머지 레이어는 FP8
주요 기능: DeepSeek-V4-Flash가 돋보이는 이유
모델 전환 없이 선택 가능한 추론 깊이
대부분의 모델은 단일 추론 모드(추론 켜짐 또는 꺼짐)로 고정됩니다. DeepSeek-V4-Flash는 동일한 API 엔드포인트에서 세 가지 고유한 작동 모드를 제공합니다:
| 모드 | 특징 | 최적 용도 |
|---|---|---|
| 비추론 | 빠름, 체인오브생각 없음 | 대량 작업, 채팅, 요약 |
| 추론 | 단계별 추론, 균형 잡힘 | 복잡한 Q&A, 코드 생성, 분석 |
| 최대 추론 | 최대 추론 예산 | 수학 경쟁, 어려운 코딩 작업, 벤치마크 |
모드 간 차이는 상당합니다: GPQA Diamond에서 V4-Flash 비추론은 71.2점, 추론은 87.4점, 최대 추론은 88.1점입니다. LiveCodeBench에서 최대 추론은 91.6점, 비추론은 55.2점입니다. 요청당 비용과 품질을 선택할 수 있으며 인프라 변경은 필요하지 않습니다.
100만 토큰 컨텍스트를 위한 하이브리드 어텐션 아키텍처
기본 백만 토큰 컨텍스트는 생각보다 어렵습니다. DeepSeek-V4-Flash는 두 가지 메커니즘을 결합한 특수 제작된 하이브리드 어텐션 아키텍처를 통해 이를 달성합니다:
- 압축 희소 어텐션 (CSA) — 긴 시퀀스에 대한 어텐션 연산 예산을 크게 줄임
- 고압축 어텐션 (HCA) — 100만 컨텍스트 추론을 위한 KV 캐시 공간을 압축
결과: 100만 토큰 입력에 대한 추론을 관리 가능한 FLOP 및 메모리 비용으로 수행할 수 있습니다. 코드베이스 분석, 법률 문서 검토, 장기 세션 에이전트와 같은 워크로드에서 이 아키텍처는 실행 가능과 불가능의 차이를 만듭니다.
MoE 효율성: 284B 스케일에서 13B 활성화
284B/13B 활성화 비율이 비용 효율성의 핵심입니다. 순방향 패스당 13B 파라미터만 활성화되어 지연 시간과 토큰당 비용을 13B 밀집 모델에 가깝게 유지하는 반면, 전체 284B 파라미터 풀은 훨씬 더 큰 밀집 네트워크에 필적하는 지식 용량을 제공합니다. FP4 + FP8 혼합 정밀도는 전문가 가중치에 대한 메모리 대역폭 압력을 더욱 줄입니다.
강력한 사후 학습 파이프라인
DeepSeek-V4-Flash는 2단계 사후 학습 과정을 따릅니다: 먼저 SFT 및 GRPO를 사용한 강화 학습을 통한 도메인별 전문가 육성, 그 다음 온폴리시 증류를 통한 통합 모델 통합입니다. 이는 코딩, 추론 및 일반 지식 전반에 걸쳐 차별화된 기능 프로필을 가진 단일 모델을 생성합니다. 단순한 지시 따르기 모델이 아닙니다.
벤치마크 성능
DeepSeek-V4-Flash의 벤치마크 성능은 추론 모드 선택에 관한 것입니다. 비추론 모드에서는 효율적인 13B 활성화 모델처럼 작동합니다. 최대 추론으로 올리면 완전히 다른 계층에 도달합니다.
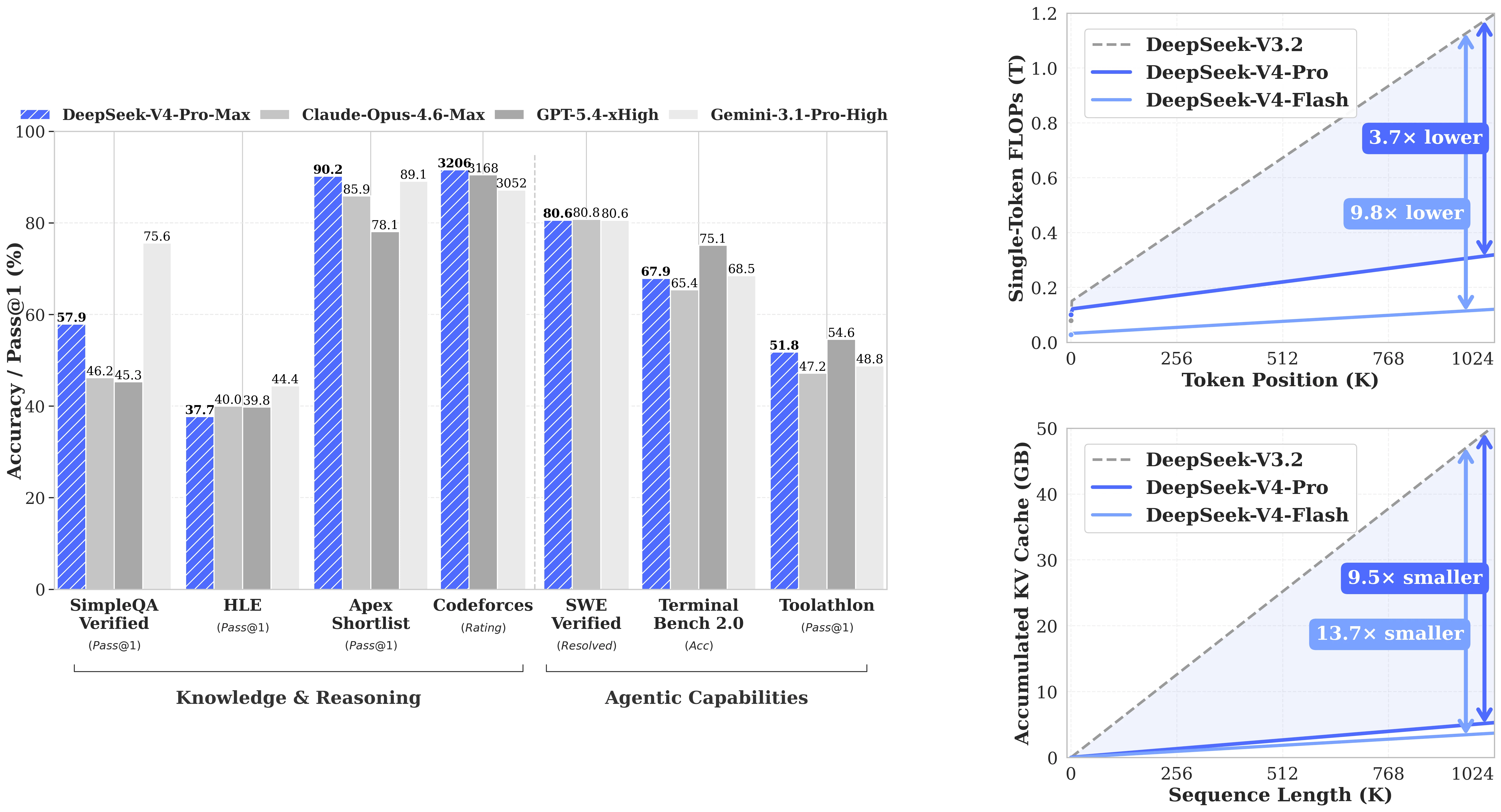
모드별 DeepSeek-V4-Flash 성능 대 최첨단 모델 [출처: DeepSeek AI / HuggingFace]
추론 모드별 성능
다음은 주요 벤치마크에서 V4-Flash의 점수로, 세 가지 작동 모드를 비교합니다:
| 벤치마크 | V4-Flash 비추론 | V4-Flash 추론 | V4-Flash 최대 추론 |
|---|---|---|---|
| LiveCodeBench (Pass@1) | 55.2 | 88.4 | 91.6 |
| GPQA Diamond (Pass@1) | 71.2 | 87.4 | 88.1 |
| HMMT 2026 Feb (Pass@1) | 40.8 | 91.9 | 94.8 |
| IMOAnswerBench (Pass@1) | 41.9 | 85.1 | 88.4 |
| Codeforces Rating | — | 2816 | 3052 |
| SWE Verified (해결됨) | 73.7 | 78.6 | 79.0 |
| MRCR 1M (MMR) | 37.5 | 76.9 | 78.7 |
| MCPAtlas (Pass@1) | 64.0 | 67.4 | 69.0 |
| MMLU-Pro (EM) | 83.0 | 86.4 | 86.2 |
최종 확인: 2026-04-27. 출처: DeepSeek-V4 기술 보고서 및 HuggingFace 모델 카드.
V4-Flash와 경쟁 모델 비교
V4-Flash 최대 추론 (SWE Verified 79.0, LiveCodeBench 91.6)은 훨씬 높은 토큰당 비용으로 실행되는 모델과 경쟁합니다. 모든 리더보드에서 1위를 차지하지는 않지만(대부분의 최첨단 벤치마크에서 V4-Pro Max가 선두), 작업당 비용을 기준으로 평가하는 개발자에게는 유리한 트레이드오프입니다:
| 벤치마크 | V4-Flash 최대 추론 | V4-Pro 최대 추론 | Claude Opus 4.6 최대 추론 | Gemini 3.1 Pro High |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 91.6 | 93.5 | 88.8 | 91.7 |
| GPQA Diamond (Pass@1) | 88.1 | 90.1 | 91.3 | 94.3 |
| SWE Verified (해결됨) | 79.0 | 80.6 | 80.8 | 80.6 |
| HMMT 2026 Feb (Pass@1) | 94.8 | 95.2 | 96.2 | 94.7 |
| MRCR 1M (MMR) | 78.7 | 83.5 | 92.9 | 76.3 |
최종 확인: 2026-04-27. Claude Opus 4.6 최대 추론 및 Gemini 3.1 Pro High 수치는 DeepSeek-V4 기술 보고서에서 가져왔습니다(V4-Pro 최첨단 비교 표). 해당 보고서에서 V4-Flash와 직접 비교 측정된 점수는 아닙니다.
특히 MRCR 1M에서 V4-Flash 최대 추론(78.7)은 장기 컨텍스트 검색 작업에서 Gemini 3.1 Pro High(76.3)를 능가합니다. 이 벤치마크는 100만 컨텍스트 사용 사례를 가장 직접적으로 반영합니다. SWE Verified에서는 네 모델 모두 79–81 사이에 모여 있어, 폐쇄형 모델 가격의 극히 일부로 실제 코딩 에이전트 범주에서 경쟁력이 있습니다.
Novita AI를 통해 DeepSeek-V4-Flash 사용하는 방법
옵션 1: 플레이그라운드 (코드 불필요)
Novita AI 모델 콘솔에서 브라우저에서 직접 모델을 테스트하세요. API 키 없이 시작할 수 있습니다. 채팅 인터페이스에서 비추론, 추론, 최대 추론 모드 간에 전환할 수 있습니다.
옵션 2: API (Python)
DeepSeek-V4-Flash는 OpenAI 호환 API를 사용합니다. Novita 기본 URL과 함께 모델 ID deepseek/deepseek-v4-flash를 사용하세요:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Your prompt here"}]
)
print(response.choices[0].message.content)
추론 또는 최대 추론 모드를 활성화하려면 요청 본문에 reasoning 매개변수를 전달하세요:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
# 최대 추론 모드 — 최대 추론 예산
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Solve: x^4 - 5x^2 + 4 = 0"}],
extra_body={"reasoning": {"effort": "high"}} # "low" = 추론, "high" = 최대 추론
)
print(response.choices[0].message.content)
API 키는 novita.ai/settings에서 받으세요.
옵션 3: 타사 도구
Novita AI는 OpenAI 호환 엔드포인트를 제공하므로 DeepSeek-V4-Flash를 다음 도구와 바로 사용할 수 있습니다:
- LangChain / LlamaIndex —
ChatOpenAI를base_url="https://api.novita.ai/v3/openai"와 함께 사용 - OpenWebUI — 사용자 정의 OpenAI 호환 엔드포인트로 추가
- Continue.dev / Cursor — Novita 기본 URL을 사용하여 사용자 정의 모델로 구성
가격
DeepSeek-V4-Flash는 주요 제공업체에서 일관되게 가격이 책정됩니다. 모든 수치는 백만 토큰 기준이며, 2026-04-27 기준:
| 제공업체 | 입력 ($/M) | 출력 ($/M) | 캐시 읽기 ($/M) | 최대 컨텍스트 |
|---|---|---|---|---|
| Novita AI | $0.14 | $0.28 | $0.028 | 1,048,576 토큰 |
| DeepSeek 공식 | $0.14 | $0.28 | $0.028 | 131,072 토큰 |
| SiliconFlow | $0.14 | $0.28 | $0.028 | 65,536 토큰 |
| DeepInfra | $0.14 | $0.28 | — | 16,384 토큰 |
토큰당 요금은 모든 곳에서 동일하지만 최대 컨텍스트는 크게 다릅니다. Novita AI는 전체 100만 토큰 컨텍스트 창을 제공합니다. DeepInfra는 16,384 토큰으로 제한됩니다. 장문 문서, 코드베이스 또는 다중 턴 에이전트를 다루는 워크로드라면 Novita가 실용적인 선택입니다.
권장 사용 사례
자율 코딩 에이전트
V4-Flash의 100만 컨텍스트 창은 에이전트가 코드베이스 전체를 청킹 없이 컨텍스트에 로드할 수 있음을 의미합니다. 최대 추론 모드에서 SWE Verified 79.0과 결합하여 다중 파일 리팩터링 및 디버깅을 턴 사이에 상태 손실 없이 처리합니다.
장문 문서 QA 및 RAG
MRCR 1M (다중 라운드 컨텍스트 검색) 최대 추론 78.7% — 이 벤치마크는 실제 100만 토큰 창에서의 검색 정확도를 측정합니다. 법률 문서, 학술 논문 또는 긴 기술 사양 색인화에 대해 V4-Flash는 대부분의 모델이 32K 토큰 이후 성능이 저하되는 경우에도 정확하게 검색합니다.
수학 및 과학 추론
HMMT 2026 2월 (경쟁 수학) 최대 추론 94.8%. 예산 생각 모드를 사용하면 비용 대비 정확도를 조정할 수 있습니다. 표준 문제에는 추론을, 어려운 문제에는 최대 추론을 사용하세요. 단일 요청이 고정된 연산 예산을 소모하지 않습니다. 직접 선택할 수 있습니다.
캐싱을 활용한 프로덕션 API
$0.028/M 캐시 읽기 가격으로 반복되는 시스템 프롬프트와 도구 스키마는 규모에서 사실상 비용이 들지 않습니다. 매 호출마다 동일한 컨텍스트를 다시 주입하는 챗봇 제품 및 API 래퍼는 원시 입력 가격 대신 캐시 읽기 가격의 혜택을 받습니다.
자주 묻는 질문
DeepSeek-V4-Flash란 무엇인가요?
DeepSeek-V4-Flash는 DeepSeek AI가 개발한 284B 파라미터 Mixture-of-Experts 언어 모델로, 2026-04-23에 출시되었습니다. 순방향 패스당 13B 파라미터만 활성화하여 비슷한 성능의 밀집 모델보다 훨씬 빠르고 저렴합니다. 1,048,576 토큰 컨텍스트 창과 세 가지 추론 모드(비추론, 예산 추론, 확장 추론(최대 추론))를 지원합니다.
DeepSeek-V4-Flash와 DeepSeek-V4-Pro의 차이점은 무엇인가요?
V4-Flash는 속도와 비용에 최적화된 더 가볍고 빠른 변형입니다. V4-Pro는 더 높은 최고 벤치마크 점수(예: LiveCodeBench 최대 추론에서 93.5 대 91.6)를 가진 플래그십 모델입니다. V4-Flash는 “더 큰 사고 예산이 주어질 때 Pro 버전과 비슷한 추론 성능을 달성합니다.” 실제로 V4-Flash 최대 추론은 더 낮은 토큰당 비용으로 V4-Pro 최대 추론과의 격차를 대부분 좁힙니다.
모델 이름에서 "Flash"는 무엇을 의미하나요?
Flash는 Google이 Gemini Flash에서 사용하는 용어와 일관되게 속도 최적화 변형을 나타냅니다. DeepSeek-V4-Flash는 성능 격차를 좁혀야 할 때 추론 모드를 사용할 수 있도록 하면서, 원시 최대 정확도보다 낮은 지연 시간과 비용을 우선시합니다.
DeepSeek-V4-Flash가 Novita AI에서 100만 컨텍스트 창을 지원하나요?
네. Novita AI는 전체 1,048,576 토큰 컨텍스트 창을 제공합니다. 이는 현재 이 모델에 대해 모든 제공업체 중에서 가장 큰 것입니다. Novita의 최대 완성 토큰은 393,216입니다.
API를 통해 추론 모드를 어떻게 전환하나요?
예산 추론의 경우 extra_body={"reasoning": {"effort": "low"}} 매개변수를 전달하고, 최대 추론의 경우 "effort": "high"를 전달하세요. 모드를 생략하면 비추론(빠름) 모드가 됩니다. API는 OpenAI 호환이므로 SDK 변경이 필요하지 않습니다.
Novita AI가 지원하는 DeepSeek-V4-Flash의 가격은 얼마인가요?
2026-04-27 기준: 입력 토큰 $0.14/M, 출력 토큰 $0.28/M, 캐시 읽기 토큰 $0.028/M입니다. 이는 DeepSeek의 공식 가격과 일치하며 모든 제공업체에서 일관됩니다. Novita의 차별점은 전체 100만 컨텍스트 창과 안정적인 가동 시간입니다.
DeepSeek-V4-Flash는 오픈소스인가요?
네. 모델 가중치는 HuggingFace에서 MIT 라이선스로 제공됩니다. 공식 DeepSeek-V4 저장소에서 확인되었습니다. 자체 호스팅 및 상업적 사용은 MIT 조건에 따라 허용됩니다. Novita AI의 API를 통해 사용하는 경우 자체 호스팅이 전혀 필요하지 않습니다.
지금 DeepSeek-V4-Flash 사용 시작하기
DeepSeek-V4-Flash가 이제 Novita AI에서 전체 100만 컨텍스트 창, 경쟁력 있는 가격, 제로 인프라 오버헤드로 제공됩니다. 추론 모드를 선택하면 Novita가 나머지를 처리합니다.
→ Novita AI가 지원하는 DeepSeek-V4-Flash 사용해보기



