

2026년에 AI 에이전트를 구축한다면, 선택하는 추론 제공자가 1년 전보다 더 중요해졌습니다. 그리고 그 이유는 대부분의 비교 글에서 다루지 않는 부분입니다. 컨텍스트 윈도우, 가격, 지연 시간은 기본 사항에 불과합니다. 실제 차별화 요소는 에이전트가 세션당 수십 번의 도구 호출을 시작하고, 병렬 하위 작업을 생성하며, 예측할 수 없는 트래픽 급증으로 인프라를 강타할 때 비로소 드러납니다.
이 가이드는 단순한 채팅 완성이 아닌 에이전트 워크로드를 처리할 수 있는 추론 제공자를 판별하는 다섯 가지 기준을 자세히 설명합니다.
에이전트 워크로드가 다른 이유
채팅 완성은 단일 왕복입니다. 하나의 프롬프트 입력, 하나의 응답 출력. AI 에이전트는 완전히 다른 것입니다.
일반적인 에이전트 워크플로우는 다음과 같습니다:
- 다단계 추론 루프 — 모델이 생각하고, 행동하고, 관찰하고, 다시 생각하며 사용자 요청당 여러 LLM 호출을 연결
- 모든 단계에서 도구 호출 — 검색, 코드 실행, API 호출, 파일 읽기. 각각 모델이 정확히 처리해야 하는 구조화된 응답 필요
- 증가하는 컨텍스트 윈도우 — 모든 도구 결과가 컨텍스트에 추가되므로 2K 토큰으로 시작한 세션이 15단계에서는 80K 토큰에 도달할 수 있음
- 버스트 중심 트래픽 패턴 — 에이전트는 종종 이벤트(웹훅, 사용자 작업, 예약된 작업)에 의해 트리거되며 채팅처럼 부드럽게 분산되지 않음
중요하게 고려해야 할 다섯 가지 기준
1. 도구 호출 안정성
🔧요약 — 제공자가 잘 구성된 도구 호출을 안정적으로 반환하지 못하면 에이전트는 워크플로우 중간에 실패합니다. 이는 협상 불가능한 사항입니다.
정의: 제공자가 다단계 에이전트 루프의 모든 단계에서 항상 잘 구성된 도구 호출 응답을 안정적으로 반환할 수 있는 능력.
에이전트에게 중요한 이유: 채팅 완성은 가끔 잘못된 응답을 허용할 수 있습니다. 그러나 에이전트는 그럴 수 없습니다. 10단계 워크플로우의 6단계에서 모델이 잘못 구조화된 도구 호출을 반환하면 전체 작업이 실패합니다.
확인할 사항:
- OpenAI 호환 함수 호출 API — 사용자 정의 구문 분석이 필요한 독점 형식이 아닌 것
- 구조화된 출력 지원 — 프롬프팅만이 아닌 모델 수준에서 유효한 JSON 스키마를 강제
- 모델 수준 검증 — 모든 모델이 다중 턴 도구 사용을 동일하게 처리하는 것은 아님
Novita AI에서: Novita는 함수 호출과 구조화된 출력을 기본적으로 지원합니다.
2. 컨텍스트 길이
📏요약 — 컨텍스트 길이는 에이전트의 작업 기억 공간입니다. 부족한 컨텍스트는 에이전트를 중단시키지 않지만 품질 저하를 일으킵니다.
정의: 모델이 단일 요청에서 처리할 수 있는 최대 토큰 수 — 이전 대화 턴, 도구 결과, 시스템 프롬프트를 모두 포함합니다.
에이전트에게 중요한 이유: 에이전트가 검색하는 모든 도구 결과가 컨텍스트에 추가됩니다. 웹 검색은 3K 토큰을 반환할 수 있습니다. 코드 실행 출력은 8K 토큰을 반환할 수 있습니다. 연구 에이전트의 10단계에서는 쉽게 50~100K 토큰에 도달합니다. 컨텍스트 길이가 부족하면 시스템 프롬프트에 정의된 제약 조건을 에이전트가 “잊어버리거나”, 이전 추론과 모순되거나, 이미 완료한 단계를 반복하는 등의 미묘한 성능 저하가 발생합니다.
확인할 사항:
- 최소 128K 토큰 — 프로덕션 에이전트용
- 200K+ 토큰 — 연구 에이전트, 장기 계획 작업, 코드 중심 워크플로우용
- 프롬프트 캐싱 — 매 턴마다 큰 컨텍스트를 재전송하면 비용이 많이 듭니다. 안정적인 접두사를 캐싱하면 비용과 지연 시간을 모두 줄일 수 있습니다.
Novita AI에서: 컨텍스트 길이는 최대 1M 토큰(MiniMax M1)까지 지원하며, 대부분의 플래그십 모델은 128K~204K 토큰입니다. GLM-4.7 및 MiniMax M2.x 시리즈는 204,800 토큰을 지원합니다. Llama 3.3 70B는 131,072 토큰을 지원합니다. DeepSeek V3.2 및 V3-0324는 163,840 토큰을 지원합니다. 프롬프트 캐싱 을 기본적으로 제공합니다.
3. 버스트 트래픽 처리
⚡요약 — 테스트에서는 잘 작동하는 속도 제한이 프로덕션에서는 에이전트 워크플로우 실행 중간을 중단시키는 429 오류로 나타납니다.
정의: 제공자가 갑작스러운 요청량 급증을 심각한 지연 시간 저하나 하드 장애 없이 흡수할 수 있는 능력.
에이전트에게 중요한 이유: 에이전트 트래픽은 본질적으로 버스트 특성을 가집니다. 사용자 트리거 이벤트는 한 번에 10개의 병렬 하위 에이전트 호출로 확장될 수 있습니다. 예약된 작업은 자정에 동시에 50개의 에이전트를 시작할 수 있습니다.
확인할 사항:
- 높은 RPM 상한 — 특히 오늘 팀이 액세스할 수 있는 계층에서
- 모델별 속도 제한 — 모든 모델에 걸친 공유 풀이 아닌 것
- 전용 엔드포인트 — 보장된 용량이 필요할 때 옵션으로
Novita AI에서: T3 이상에서는 대부분의 모델이 1,000 RPM을 지원합니다. T5에서는 모델당 3,000~6,000 RPM으로 확장됩니다. TPM은 모든 계층에서 분당 50M 토큰으로 제한됩니다. 전용 엔드포인트를 사용하여 예약 용량과 보장된 SLA를 제공합니다.
4. 콜드 스타트 지연 시간
🚀요약 — 다단계 에이전트 루프에서 지연 시간은 누적됩니다. 3초 콜드 스타트 × 8회 도구 호출 = 세션당 24초의 불필요한 오버헤드가 발생합니다.
정의: 모델 인스턴스가 이미 "워밍업"되지 않아 요청을 처리하기 전에 초기화가 필요한 경우 발생하는 지연.
에이전트에게 중요한 이유: 콜드 스타트는 군집하는 경향이 있습니다. 에이전트가 몇 분 동안 트래픽을 받지 않으면 다음 요청 배치가 모두 콜드 인스턴스에 동시에 도달합니다. 서버리스 추론 제공자의 경우 콜드 스타트는 종종 벤치마크가 포착하지 못하는 숨겨진 성능 변수입니다.
확인할 사항:
- 인기 모델에 대한 일관되게 웜 인스턴스
- 요청 패턴 전반에 걸친 예측 가능한 TTFT(첫 번째 토큰까지의 시간)
- 코드 실행 에이전트를 위한 200ms 미만 시작 시간의 에이전트 샌드박스 인프라
Novita AI에서: 200개 이상의 모델을 운영하는 대규모 플랫폼인 Novita는 인기 모델 인스턴스를 웜 상태로 유지합니다. E2E 지연 시간 및 TTFT 메트릭(P95 및 P99 백분위수 포함)은 관찰 가능성 대시보드를 통해 노출됩니다. 에이전트 샌드박스 시작 시간은 200ms 미만입니다.
5. 동시성
🔀요약 — 동시성은 단순히 규모의 문제가 아닙니다. 아키텍처의 문제입니다. 하위 작업을 병렬로 실행하는 에이전트는 순차적 에이전트보다 훨씬 빠릅니다.
정의: 제공자가 처리할 수 있는 동시 요청 수 — API 수준(RPM/TPM)과 인프라 수준(병렬 에이전트 실행) 모두 포함.
에이전트에게 중요한 이유: 다중 에이전트 시스템은 여러 수준에서 동시성이 필요합니다. 병렬 LLM 호출, 병렬 도구 실행, 병렬 샌드박스 인스턴스 등이 필요합니다.
확인할 사항:
- 병렬 에이전트 호출을 지원하는 높은 모델별 RPM
- 샌드박스 동시성 — 한 번에 50개의 격리된 실행 환경을 생성할 수 있는가?
- 샌드박스에 대한 초당 과금 — 분당이 아닌
Novita AI에서: 에이전트 샌드박스는 CPU 및 RAM에 대한 초당 과금으로 대규모 동시 생성을 지원합니다. T3+ 계정은 모델당 1,000 RPM에 도달하며, 관찰 가능성 계층은 RPM을 실시간으로 추적합니다.
의사 결정 프레임워크
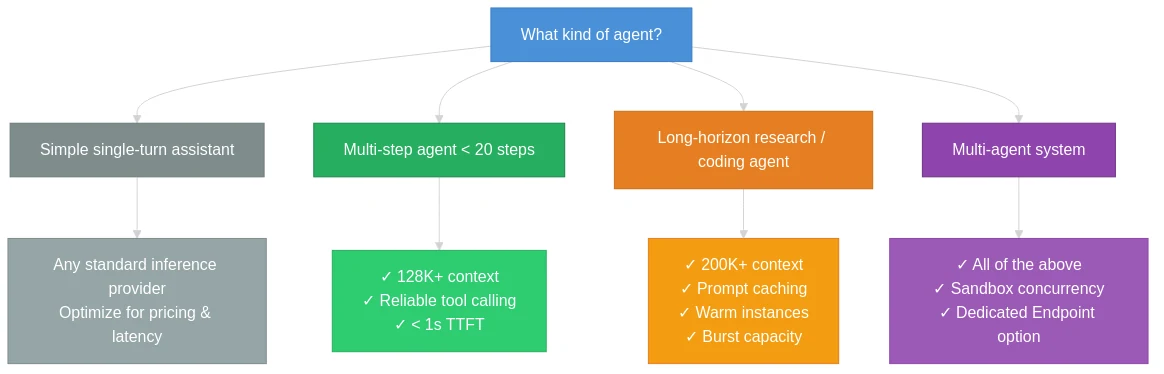
| 기준 | 최소 요구 사항 | 프로덕션 수준 |
|---|---|---|
| 도구 호출 | OpenAI 호환 함수 호출 | 구조화된 출력 + 검증된 다중 턴 지원 |
| 컨텍스트 길이 | 32K | 128K+ (연구 에이전트의 경우 200K+) |
| 버스트 용량 | 100 RPM | 모델당 1,000+ RPM |
| 콜드 스타트 | 평균 TTFT 3초 미만 | P95 TTFT 1초 미만, 웜 인스턴스 보장 |
| 동시성 | 순차적 | 병렬 LLM 호출 + 샌드박스 실행 |
결론
AI 에이전트를 위한 추론 제공자를 선택하는 것은 챗봇을 위한 것과 동일하지 않습니다. 다섯 가지 기준 — 도구 호출 안정성, 컨텍스트 길이, 버스트 트래픽, 콜드 스타트, 동시성 — 은 채팅용으로 설계된 제공자와 프로덕션 에이전트를 실행하도록 구축된 제공자를 구분합니다.
Novita AI는 AI 및 에이전트 클라우드 플랫폼으로 포지셔닝되었습니다. 단일 OpenAI 호환 API를 통한 200개 이상의 모델, 200ms 미만 시작 시간과 초당 과금을 제공하는 에이전트 샌드박스, 긴 컨텍스트 비용 효율성을 위한 프롬프트 캐시, 프로토타이핑(30 RPM)부터 프로덕션(모델당 6,000 RPM)까지 확장되는 계층화된 속도 제한 구조를 갖추고 있습니다.
Novita AI는 개발자와 스타트업이 고성능, 안정성 및 비용 효율성으로 모델과 에이전트 애플리케이션을 구축, 배포 및 확장할 수 있도록 돕는 AI 및 에이전트 클라우드 플랫폼입니다.
자주 묻는 질문
에이전트에서 도구 호출에 사용하는 모델이 중요한가요?
네, 매우 중요합니다. 모든 모델이 다중 턴 함수 호출을 동일한 안정성으로 처리하는 것은 아닙니다. 특정 에이전트 워크플로우를 테스트하고, 모델을 도구 호출 능력에 따라 명시적으로 분류하는 제공자를 찾으십시오.
실제로 필요한 컨텍스트 길이는 어떻게 추정하나요?
대표적인 세션의 각 단계에서 실제 토큰 수를 로깅하는 것부터 시작하십시오. 합리적인 규칙: 세션당 5회 이상의 도구 호출 → 64K+ 토큰; 10회 이상의 도구 호출 → 128K+ 토큰.
전용 엔드포인트를 사용할 가치가 있나요?
초기 단계 팀의 경우 공유 서버리스 엔드포인트로 충분합니다. 전용 엔드포인트는 (a) 트래픽이 예약 용량을 정당화할 만큼 예측 가능할 때, (b) 공유 계층에서 속도 제한에 도달했을 때, © SLA에 요청 대기열이 없어야 할 때 적합합니다.
추천 문서



