

DeepSeek-V4-Flash com suporte da Novita AI: Contexto de 1M a US$ 0,14/M de Tokens
A maioria dos modelos de código aberto com capacidade de raciocínio impõe um trade-off: janelas de contexto pequenas, baixa taxa de transferência ou preços que ultrapassam US$ 1/M de tokens assim que você ativa o pensamento estendido. O DeepSeek-V4-Flash contorna isso completamente — 284B de parâmetros, apenas 13B ativados por inferência, uma janela de contexto nativa de 1.048.576 tokens e três modos de raciocínio selecionáveis. A US$ 0,14/M de tokens de entrada, ele se enquadra em uma categoria onde modelos com capacidade de raciocínio raramente competem.
Resumindo: DeepSeek-V4-Flash é um modelo MoE da DeepSeek AI que traz contexto de 1M de tokens e profundidade de raciocínio ajustável para desenvolvedores que precisam de taxa de transferência sem o prêmio de preço dos modelos fechados. A partir de hoje, está disponível através da API da Novita AI.
O que é DeepSeek-V4-Flash?
DeepSeek-V4-Flash é um modelo de linguagem Mixture-of-Experts (MoE) da DeepSeek AI, lançado como parte da série DeepSeek-V4 junto com o DeepSeek-V4-Pro, maior. O modelo tem 284B de parâmetros totais com 13B ativados na inferência — mantendo o custo computacional por token baixo, enquanto retém a capacidade de parâmetros de um modelo muito maior.
Principais capacidades em resumo:
- 284B total / 13B ativados — arquitetura MoE, baixo custo de inferência
- Janela de contexto de 1.048.576 tokens (1M de tokens) — habilitada pela Hybrid Attention Architecture
- Três modos de raciocínio: Non-think (rápido), Think (passo a passo), Think Max (orçamento máximo de raciocínio)
- Suporte a chamadas de função — uso de ferramentas, saídas estruturadas, modo JSON
- Treinado em mais de 32T tokens com pós-treinamento em múltiplos estágios (SFT, RL com GRPO, destilação on-policy)
- Licença MIT — pesos disponíveis para download no HuggingFace; uso comercial permitido
- Precisão mista FP4 + FP8 — pesos dos especialistas MoE em FP4, camadas restantes em FP8
Principais Características: Por que o DeepSeek-V4-Flash se Destaca
Profundidade de Raciocínio Selecionável sem Trocar de Modelo
A maioria dos modelos te prende a um único modo de inferência: raciocínio ligado ou desligado. DeepSeek-V4-Flash oferece três modos de operação distintos no mesmo endpoint da API:
| Modo | Características | Melhor Para |
|---|---|---|
| Non-think | Rápido, sem cadeia de pensamento | Tarefas de alto volume, chat, sumarização |
| Think | Raciocínio passo a passo, equilibrado | Perguntas e respostas complexas, geração de código, análise |
| Think Max | Orçamento máximo de raciocínio | Competições de matemática, tarefas de codificação difíceis, benchmarks |
A diferença entre os modos é significativa: no GPQA Diamond, V4-Flash Non-think pontua 71,2 vs Think com 87,4 e Think Max com 88,1. No LiveCodeBench, Think Max atinge 91,6 vs 55,2 do Non-think. Você escolhe custo vs qualidade por requisição — sem necessidade de mudança de infraestrutura.
Arquitetura de Atenção Híbrida para Contexto de 1M de Tokens
Contexto nativo de um milhão de tokens é mais difícil do que parece. DeepSeek-V4-Flash alcança isso através de uma Hybrid Attention Architecture construída sob medida que combina dois mecanismos:
- Compressed Sparse Attention (CSA) — reduz drasticamente o orçamento computacional de atenção para sequências longas
- Heavily Compressed Attention (HCA) — comprime a pegada do cache KV para inferência com contexto de 1M
O resultado: inferência sobre entradas de 1M de tokens com custo gerenciável de FLOP e memória. Para cargas de trabalho como análise de bases de código, revisão de documentos legais ou agentes de sessão longa, essa arquitetura faz a diferença entre viável e proibitivo.
Eficiência MoE: 13B Ativados na Escala de 284B
A proporção 284B/13B ativados é de onde vem a eficiência de custo. Apenas 13B de parâmetros estão ativos por passagem direta, mantendo a latência e o custo por token próximos a um modelo denso de 13B — enquanto o pool completo de 284B de parâmetros fornece capacidade de conhecimento comparável a uma rede densa muito maior. A precisão mista FP4 + FP8 reduz ainda mais a pressão na largura de banda da memória para os pesos dos especialistas.
Pipeline de Pós-Treinamento Robusto
DeepSeek-V4-Flash segue um processo de pós-treinamento em dois estágios: primeiro, cultivo de especialistas por domínio via SFT e aprendizado por reforço com GRPO; depois, consolidação unificada do modelo através de destilação on-policy. Isso produz um único modelo com perfis de capacidade diferenciados em codificação, raciocínio e conhecimento geral — não um seguidor de instruções genérico.
Desempenho em Benchmarks
A história dos benchmarks para DeepSeek-V4-Flash é sobre a seleção do modo de raciocínio. No modo Non-think, ele se comporta como um modelo eficiente de 13B ativados. Aumente para Think Max e ele alcança um nível totalmente diferente.
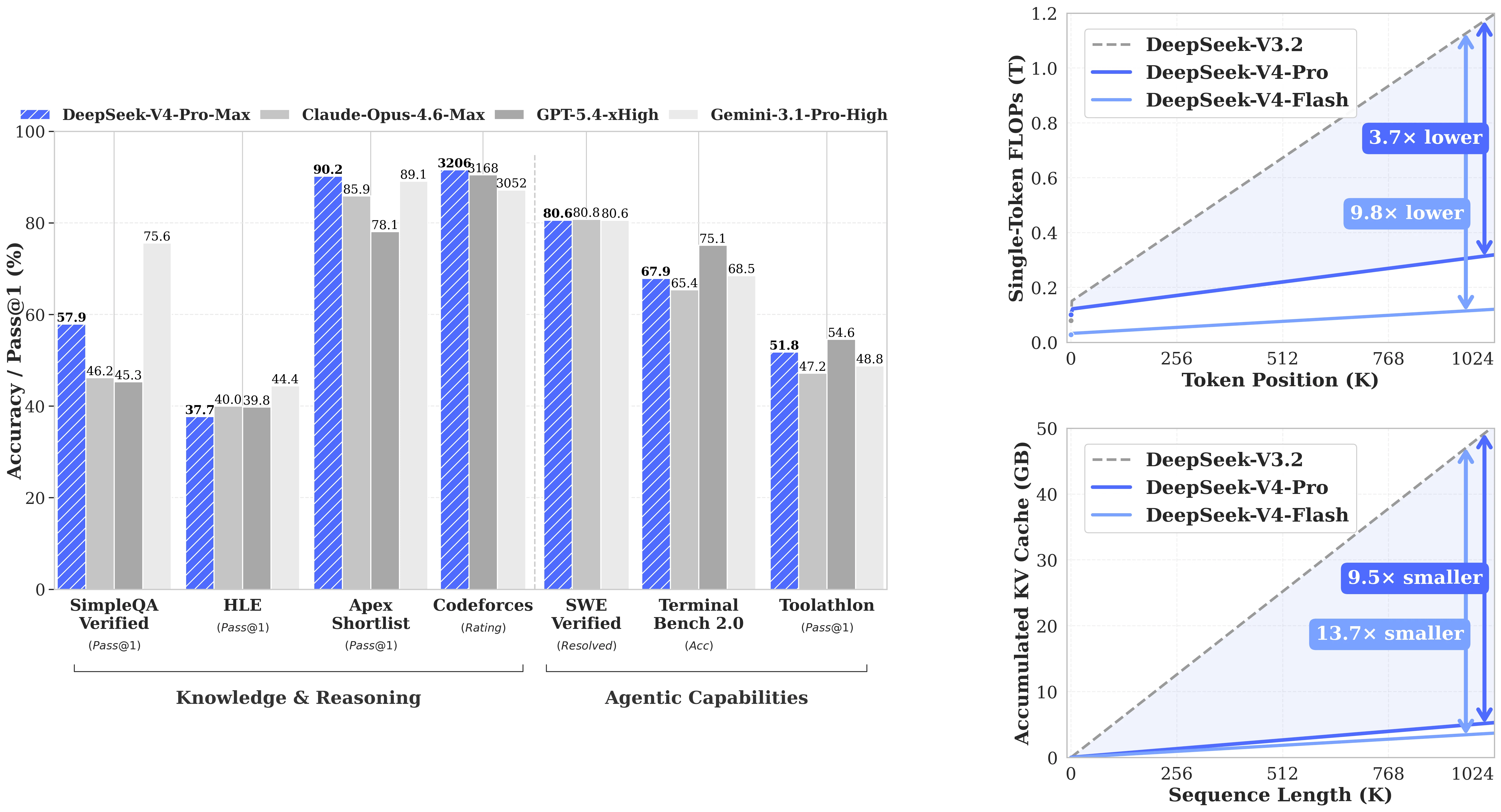
Desempenho do DeepSeek-V4-Flash entre modos vs modelos de fronteira [Fonte: DeepSeek AI / HuggingFace]
Desempenho entre Modos de Raciocínio
Abaixo estão as pontuações do V4-Flash em benchmarks chave, comparando todos os três modos de operação:
| Benchmark | V4-Flash Non-Think | V4-Flash Think | V4-Flash Think Max |
|---|---|---|---|
| LiveCodeBench (Pass@1) | 55,2 | 88,4 | 91,6 |
| GPQA Diamond (Pass@1) | 71,2 | 87,4 | 88,1 |
| HMMT 2026 Feb (Pass@1) | 40,8 | 91,9 | 94,8 |
| IMOAnswerBench (Pass@1) | 41,9 | 85,1 | 88,4 |
| Codeforces Rating | — | 2816 | 3052 |
| SWE Verified (Resolved) | 73,7 | 78,6 | 79,0 |
| MRCR 1M (MMR) | 37,5 | 76,9 | 78,7 |
| MCPAtlas (Pass@1) | 64,0 | 67,4 | 69,0 |
| MMLU-Pro (EM) | 83,0 | 86,4 | 86,2 |
Última verificação: 2026-04-27. Fonte: Relatório técnico do DeepSeek-V4 e card do modelo no HuggingFace.
Como o V4-Flash se Compara aos Concorrentes
V4-Flash Think Max (79,0 SWE Verified, 91,6 LiveCodeBench) compete com modelos rodando a um custo por token muito maior. Ele não lidera todos os rankings — V4-Pro Max lidera na maioria dos benchmarks de fronteira — mas para desenvolvedores que olham para o custo por tarefa em vez do pico de desempenho bruto, o trade-off é favorável:
| Benchmark | V4-Flash Max | V4-Pro Max | Claude Opus 4.6 Max | Gemini 3.1 Pro High |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 91,6 | 93,5 | 88,8 | 91,7 |
| GPQA Diamond (Pass@1) | 88,1 | 90,1 | 91,3 | 94,3 |
| SWE Verified (Resolved) | 79,0 | 80,6 | 80,8 | 80,6 |
| HMMT 2026 Feb (Pass@1) | 94,8 | 95,2 | 96,2 | 94,7 |
| MRCR 1M (MMR) | 78,7 | 83,5 | 92,9 | 76,3 |
Última verificação: 2026-04-27. Os números do Claude Opus 4.6 Max e Gemini 3.1 Pro High são provenientes do relatório técnico do DeepSeek-V4 (tabela de comparação de fronteira do V4-Pro). Essas pontuações não foram medidas diretamente contra o V4-Flash nesse relatório.
Notavelmente, V4-Flash Think Max no MRCR 1M (78,7) supera o Gemini 3.1 Pro High (76,3) na tarefa de recuperação de contexto longo — o benchmark que mais diretamente mapeia casos de uso de 1M de contexto. No SWE Verified, todos os quatro modelos ficam entre 79–81, tornando o V4-Flash competitivo na categoria de agente de codificação do mundo real a uma fração do preço dos modelos fechados.
Como Usar DeepSeek-V4-Flash via Novita AI
Opção 1: Playground (Sem Código)
Teste o modelo diretamente no seu navegador no console de modelos da Novita AI. Nenhuma chave de API necessária para começar — alterne entre os modos Non-think, Think e Think Max através da interface de chat.
Opção 2: API (Python)
DeepSeek-V4-Flash usa a API compatível com OpenAI. Use o ID do modelo deepseek/deepseek-v4-flash com a URL base da Novita:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="SUA_CHAVE_API_NOVITA",
)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Seu prompt aqui"}]
)
print(response.choices[0].message.content)
Para habilitar o modo Think ou Think Max, passe o parâmetro reasoning no corpo da requisição:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="SUA_CHAVE_API_NOVITA",
)
# Modo Think Max — orçamento máximo de raciocínio
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Resolva: x^4 - 5x^2 + 4 = 0"}],
extra_body={"reasoning": {"effort": "high"}} # "low" = Think, "high" = Think Max
)
print(response.choices[0].message.content)
Obtenha sua chave de API em novita.ai/settings.
Opção 3: Ferramentas de Terceiros
Como a Novita AI expõe um endpoint compatível com OpenAI, DeepSeek-V4-Flash funciona perfeitamente com:
- LangChain / LlamaIndex — use
ChatOpenAIcombase_url="https://api.novita.ai/v3/openai" - OpenWebUI — adicione como um endpoint personalizado compatível com OpenAI
- Continue.dev / Cursor — configure como um modelo personalizado com a URL base da Novita
Preços
DeepSeek-V4-Flash tem preço consistente entre os principais provedores. Todos os valores são por milhão de tokens, a partir de 2026-04-27:
| Provedor | Entrada ($/M) | Saída ($/M) | Leitura de Cache ($/M) | Contexto Máximo |
|---|---|---|---|---|
| Novita AI | US$ 0,14 | US$ 0,28 | US$ 0,028 | 1.048.576 tokens |
| DeepSeek Official | US$ 0,14 | US$ 0,28 | US$ 0,028 | 131.072 tokens |
| SiliconFlow | US$ 0,14 | US$ 0,28 | US$ 0,028 | 65.536 tokens |
| DeepInfra | US$ 0,14 | US$ 0,28 | — | 16.384 tokens |
A taxa por token é a mesma em todos os lugares — mas o contexto máximo varia significativamente. A Novita AI oferece a janela de contexto completa de 1M de tokens. DeepInfra limita a 16.384 tokens. Se sua carga de trabalho envolve documentos longos, bases de código ou agentes de várias interações, a Novita é a escolha prática.
Casos de Uso Recomendados
Agentes de Codificação Autônomos
A janela de contexto de 1M do V4-Flash significa que um agente pode carregar uma base de código inteira no contexto sem fragmentação. Combinado com 79,0 no SWE Verified no modo Think Max, ele lida com refatorações multiarquivo e depuração sem perder estado entre as interações.
Perguntas e Respostas e RAG com Documentos Longos
MRCR 1M (Multi-Round Context Retrieval) a 78,7% no Think Max — o benchmark mede a precisão da recuperação em uma janela genuína de 1M de tokens. Para indexar documentos legais, artigos acadêmicos ou especificações técnicas longas, o V4-Flash recupera com precisão onde a maioria dos modelos degrada após 32K tokens.
Raciocínio em Matemática e Ciências
94,8% no HMMT 2026 February (matemática de competição) com Think Max. O modo de pensamento com orçamento permite ajustar custo vs precisão — use Think para problemas padrão, Think Max para os difíceis. Uma única requisição não consome um orçamento computacional fixo; você escolhe.
APIs de Produção com Cache
A US$ 0,028/M de leituras de cache, prompts de sistema repetidos e esquemas de ferramentas efetivamente não custam nada em escala. Produtos de chatbot e wrappers de API que reinjetam o mesmo contexto a cada chamada se beneficiam do preço de leitura de cache sobre o preço bruto de entrada.
Perguntas Frequentes
O que é DeepSeek-V4-Flash?
DeepSeek-V4-Flash é um modelo de linguagem Mixture-of-Experts de 284B parâmetros desenvolvido pela DeepSeek AI, lançado em 23/04/2026. Ele ativa apenas 13B parâmetros por passagem direta, tornando-o significativamente mais rápido e mais barato do que modelos densos de capacidade comparável. Ele suporta uma janela de contexto de 1.048.576 tokens e três modos de raciocínio: Non-thinking (rápido), Budget Thinking e Extended Thinking (Think Max).
Como DeepSeek-V4-Flash é diferente de DeepSeek-V4-Pro?
V4-Flash é a variante mais leve e rápida, otimizada para velocidade e custo. V4-Pro é o modelo principal com pontuações de pico mais altas em benchmarks (por exemplo, 93,5 vs 91,6 no LiveCodeBench Think Max). V4-Flash “alcança desempenho de raciocínio comparável à versão Pro quando recebe um orçamento de pensamento maior” — na prática, V4-Flash Think Max fecha a maior parte da lacuna contra V4-Pro Think Max a um custo por token menor.
O que “Flash” significa no nome do modelo?
Flash sinaliza uma variante otimizada para velocidade, consistente com o uso do termo pelo Google para Gemini Flash. DeepSeek-V4-Flash prioriza menor latência e custo em detrimento da precisão máxima bruta, com os modos de pensamento disponíveis quando você precisa fechar a lacuna de desempenho.
DeepSeek-V4-Flash suporta uma janela de contexto de 1M com suporte da Novita AI?
Sim. A Novita AI expõe a janela de contexto completa de 1.048.576 tokens — a maior disponível entre todos os provedores atuais para este modelo. O número máximo de tokens de conclusão na Novita é 393.216.
Como alternar os modos de raciocínio via API?
Passe o parâmetro extra_body={"reasoning": {"effort": "low"}} para Budget Thinking, ou "effort": "high" para Think Max. Omita o parâmetro completamente para o modo Non-thinking (rápido). A API é compatível com OpenAI — nenhuma alteração de SDK necessária.
Qual é o preço do DeepSeek-V4-Flash com suporte da Novita AI?
A partir de 2026-04-27: US$ 0,14/M de tokens de entrada, US$ 0,28/M de tokens de saída, US$ 0,028/M de tokens de leitura de cache. Isso corresponde ao preço oficial da DeepSeek e é consistente entre os provedores — o diferencial na Novita é a janela de contexto completa de 1M e uptime confiável.
DeepSeek-V4-Flash é open source?
Sim. Os pesos do modelo estão disponíveis no HuggingFace sob a Licença MIT — confirmado no repositório oficial DeepSeek-V4. Auto-hospedagem e uso comercial são permitidos sob os termos MIT. Usá-lo através da API da Novita AI não requer auto-hospedagem alguma.
Comece a Usar DeepSeek-V4-Flash Hoje
DeepSeek-V4-Flash já está disponível via Novita AI com a janela de contexto completa de 1M, preços competitivos e zero sobrecarga de infraestrutura. Você escolhe o modo de raciocínio; a Novita cuida do resto.
→ Experimente DeepSeek-V4-Flash com suporte da Novita AI
→ Documentação da API LLM da Novita AI



