

Developers today struggle to balance speed, cost, and capability when choosing an LLM for real-world coding and agent systems. This article clarifies how Minimax M2.1 solves these pain points by analyzing its architecture, benchmarks, hardware profile, and deployment paths, enabling teams to select and integrate the most practical model for high-frequency development workflows.
Architecture of Minimax M2.1
| Specification | Value |
|---|---|
| Model ID | MiniMaxAI/MiniMax-M2.1 |
| Total parameters | 230B |
| Active parameters | 10B (MoE) |
| Context window | 204,800 tokens |
| Max output | 131,072 tokens |
| Precision | FP8 |
| License | Modified MIT |
| Weights | https://huggingface.co/MiniMaxAI/MiniMax-M2.1 |
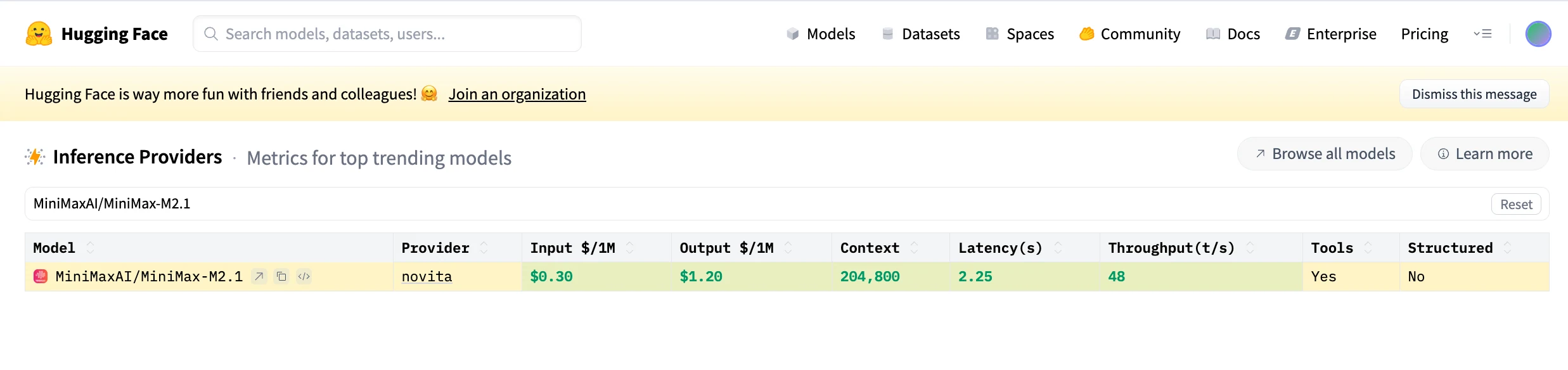
Programming Agent Ability of Minimax M2.1
Compared with Claude, which excels in general reasoning and conversational coherence, MiniMax M2.1 emphasizes engineering completeness: faster agent-loop behavior, stronger multi-language orchestration, and better alignment with real IDE-style workflows, making it more suitable for continuous coding, mobile development, and long-running agent systems.
- Multi-Language Mastery
Industry-leading performance across Rust, Java, Go, C++, Kotlin, Objective-C, TypeScript, and JavaScript, covering the entire stack from systems to applications.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 74.0 | 69.4 | 77.2 | 80.9 | 78.0 | 80.0 | 73.1 |
| Multi-SWE-bench | 49.4 | 36.2 | 44.3 | 50.0 | 42.7 | x | 37.4 |
| SWE-bench Multilingual | 72.5 | 56.5 | 68 | 77.5 | 65.0 | 72.0 | 70.2 |
| Terminal-bench 2.0 | 47.9 | 30.0 | 50.0 | 57.8 | 54.2 | 54.0 | 46.4 |
- Web and App Development
Strong native Android and iOS support, with advanced capability in complex interactions, 3D simulations, and high-quality visualization.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified (Droid) | 71.3 | 68.1 | 72.3 | 75.2 | x | x | 67.0 |
| SWE-bench Verified (mini-swe-agent) | 67.0 | 61.0 | 70.6 | 74.4 | 71.8 | 74.2 | 60.0 |
| SWT-bench | 69.3 | 32.8 | 69.5 | 80.2 | 79.7 | 80.7 | 62.0 |
| SWE-Perf | 3.1 | 1.4 | 3.0 | 4.7 | 6.5 | 3.6 | 0.9 |
| SWE-Review | 8.9 | 3.4 | 10.5 | 16.2 | x | x | 6.4 |
| OctoCodingbench | 26.1 | 13.3 | 22.8 | 36.2 | 22.9 | x | 26.0 |
An Example:
High-Frequency Agent Ability of Minimax M2.1
- Office-Grade Reasoning
Interleaved Thinking and composite instruction execution enable reliable handling of multi-objective, real-world workflows.
From Minimax
- Higher Efficiency
Shorter responses, lower token usage, and faster interaction, optimized for continuous coding and long-running tasks.
An Example:
From Mimimax
Hardware of Minimax M2.1 and How to Use it Locally?
For the vast majority of coding and agent workloads, four GPUs in the 80–96 GB class handle a 200K context window comfortably. The 8-GPU configuration becomes necessary only when operating in the multi-million-token extended context regime.
| Configuration | Max Context | Use Case |
|---|---|---|
| 4× A100 or A800 (80 GB) | 400K tokens | Standard deployments |
| 4× H200 or H20 (96 GB+) | 400K tokens | Standard deployments |
| 8× H200 (141 GB) | 3M tokens | Extended-context workloads |
Novita offers the lowest on-demand H100 pricing at $1.45/hr up to 30% cheaper than other providers with identical GPU performance.
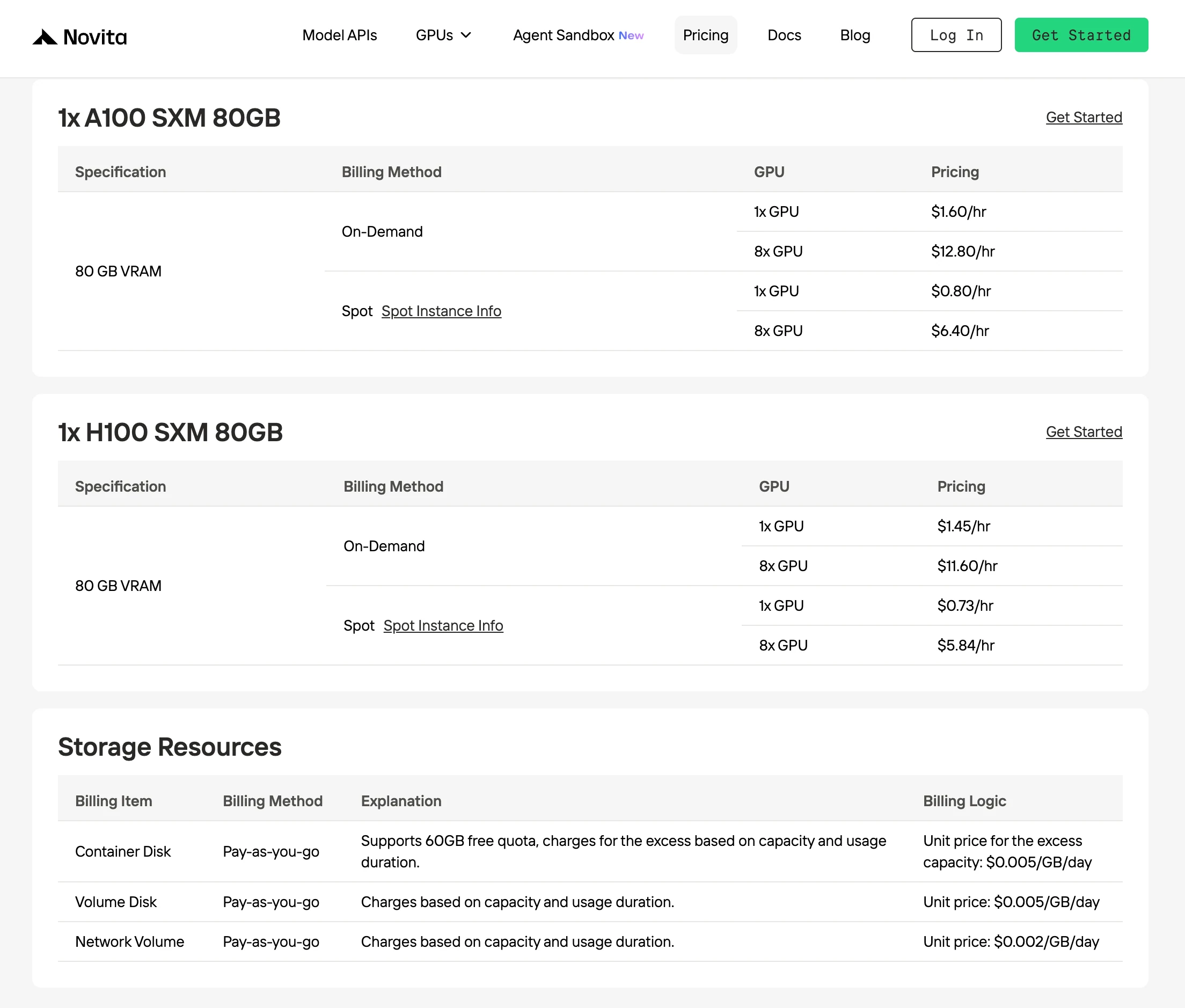
Novita AI’s Spotmode is a cost-optimized GPU rental option that leverages the platform’s unused or idle GPU capacity. Unlike on-demand instances, which reserve dedicated hardware for guaranteed continuous use, Spot instances are interruptible—offered at significantly lower prices, typically 40–60% cheaper.
This pricing model works because Novita dynamically reallocates idle GPUs to short-term users instead of leaving them unused. By doing so, the platform improves overall infrastructure utilization efficiency, while developers benefit from much lower computational costs for flexible workloads.
How to Use Minimax M2.1 at A Good Price?
Seamlessly connect Minimax M2.1 Falsh to your applications, workflows, or chatbots with Novita AI’s unified REST API—no need to manage model weights or infrastructure. Novita AI offers multi-language SDKs (Python, Node.js, cURL, and more) and advanced parameter controls for power users.
Option 1: Direct API Integration (Python Example)
Key Features:
- Unified endpoint:
/v3/openaisupports OpenAI’s Chat Completions API format. - Flexible controls: Adjust temperature, top-p, penalties, and more for tailored results.
- Streaming & batching: Choose your preferred response mode.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)Option 2: Multi-Agent Workflows with OpenAI Agents SDK
Build advanced multi-agent systems by integrating Novita AI with the OpenAI Agents SDK:
- Plug-and-play: Use Novita AI’s LLMs in any OpenAI Agents workflow.
- Supports handoffs, routing, and tool use: Design agents that can delegate, triage, or run functions, all powered by Novita AI’s models.
- Python integration: Simply point the SDK to Novita’s endpoint (
https://api.novita.ai/v3/openai) and use your API key.
Option 3:Connect GLM 4.7 Flash API on Third-Party Platforms
- Hugging Face: Use MInimax M2.1 in Spaces, pipelines, or with the Transformers library via Novita AI endpoints.
- Agent & Orchestration Frameworks: Easily connect Novita AI with partner platforms like Continue, AnythingLLM,LangChain, Dify and Langflow through official connectors and step-by-step integration guides.
- OpenAI-Compatible API: Enjoy hassle-free migration and integration with tools such as Cline and Cursor, designed for the OpenAI API standard.
Additionally, based on recommendations from Reddit, using Minimax M2.1 together with GLM 4.7 works especially well. Novita AI also provides an API for GLM 4.7, and you can click the button below to explore it.
Minimax M2.1 delivers a rare combination of frontier-scale context, MoE efficiency, and agent-loop speed, making it a production-grade choice for continuous coding and multi-agent systems. It shifts optimization from peak intelligence to real developer throughput.
Why is Minimax M2.1 suitable for long-context coding?
Minimax M2.1 supports a 204,800-token context window, allowing whole-repo reasoning and multi-file refactors in a single pass.
Is Minimax M2.1 better than Claude for coding agents?
For continuous development and agent loops, Minimax M2.1 emphasizes faster iteration and IDE-style responsiveness compared with Claude.
What is the most cost-efficient way to use Minimax M2.1?
Using Minimax M2.1 through Novita AI’s OpenAI-compatible API or Spot GPU mode offers significantly lower operational cost for production workloads.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing affordable and reliable GPU cloud for building and scaling.



