

Desenvolvedores hoje lutam para equilibrar velocidade, custo e capacidade ao escolher um LLM para codificação do mundo real e sistemas de agentes. Este artigo esclarece como o Minimax M2.1 resolve esses pontos de dor, analisando sua arquitetura, benchmarks, perfil de hardware e caminhos de implantação, permitindo que equipes selecionem e integrem o modelo mais prático para fluxos de trabalho de desenvolvimento de alta frequência.
Arquitetura do Minimax M2.1
| Especificação | Valor |
|---|---|
| ID do Modelo | MiniMaxAI/MiniMax-M2.1 |
| Total de parâmetros | 230B |
| Parâmetros ativos | 10B (MoE) |
| Janela de contexto | 204.800 tokens |
| Saída máxima | 131.072 tokens |
| Precisão | FP8 |
| Licença | Modified MIT |
| Pesos | https://huggingface.co/MiniMaxAI/MiniMax-M2.1 |
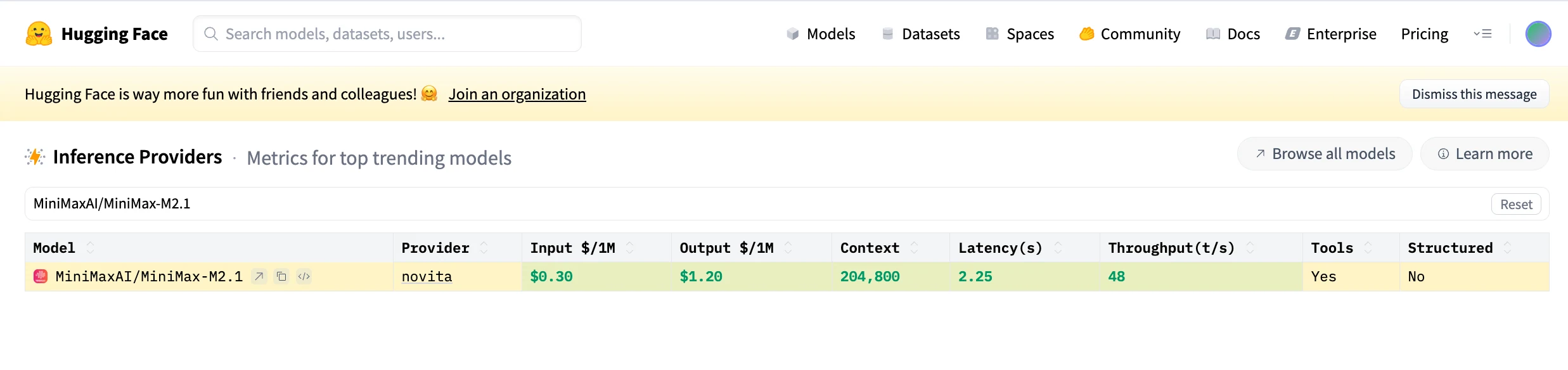
Capacidade de Agente de Programação do Minimax M2.1
Comparado com o Claude, que se destaca em raciocínio geral e coerência conversacional, o MiniMax M2.1 enfatiza a completude de engenharia: comportamento de loop de agente mais rápido, orquestração multilíngue mais forte e melhor alinhamento com fluxos de trabalho reais no estilo IDE, tornando-o mais adequado para codificação contínua, desenvolvimento mobile e sistemas de agentes de longa duração.
- Domínio Multilíngue
Desempenho líder de indústria em Rust, Java, Go, C++, Kotlin, Objective-C, TypeScript e JavaScript, cobrindo toda a pilha de sistemas a aplicações.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 74.0 | 69.4 | 77.2 | 80.9 | 78.0 | 80.0 | 73.1 |
| Multi-SWE-bench | 49.4 | 36.2 | 44.3 | 50.0 | 42.7 | x | 37.4 |
| SWE-bench Multilingual | 72.5 | 56.5 | 68 | 77.5 | 65.0 | 72.0 | 70.2 |
| Terminal-bench 2.0 | 47.9 | 30.0 | 50.0 | 57.8 | 54.2 | 54.0 | 46.4 |
- Desenvolvimento Web e de Aplicativos
Suporte nativo forte para Android e iOS, com capacidade avançada em interações complexas, simulações 3D e visualização de alta qualidade.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified (Droid) | 71.3 | 68.1 | 72.3 | 75.2 | x | x | 67.0 |
| SWE-bench Verified (mini-swe-agent) | 67.0 | 61.0 | 70.6 | 74.4 | 71.8 | 74.2 | 60.0 |
| SWT-bench | 69.3 | 32.8 | 69.5 | 80.2 | 79.7 | 80.7 | 62.0 |
| SWE-Perf | 3.1 | 1.4 | 3.0 | 4.7 | 6.5 | 3.6 | 0.9 |
| SWE-Review | 8.9 | 3.4 | 10.5 | 16.2 | x | x | 6.4 |
| OctoCodingbench | 26.1 | 13.3 | 22.8 | 36.2 | 22.9 | x | 26.0 |
Um Exemplo:
Capacidade de Agente de Alta Frequência do Minimax M2.1
- Raciocínio de Nível Corporativo
O Pensamento Intercalado e a execução de instruções compostas permitem o tratamento confiável de fluxos de trabalho do mundo real com múltiplos objetivos.
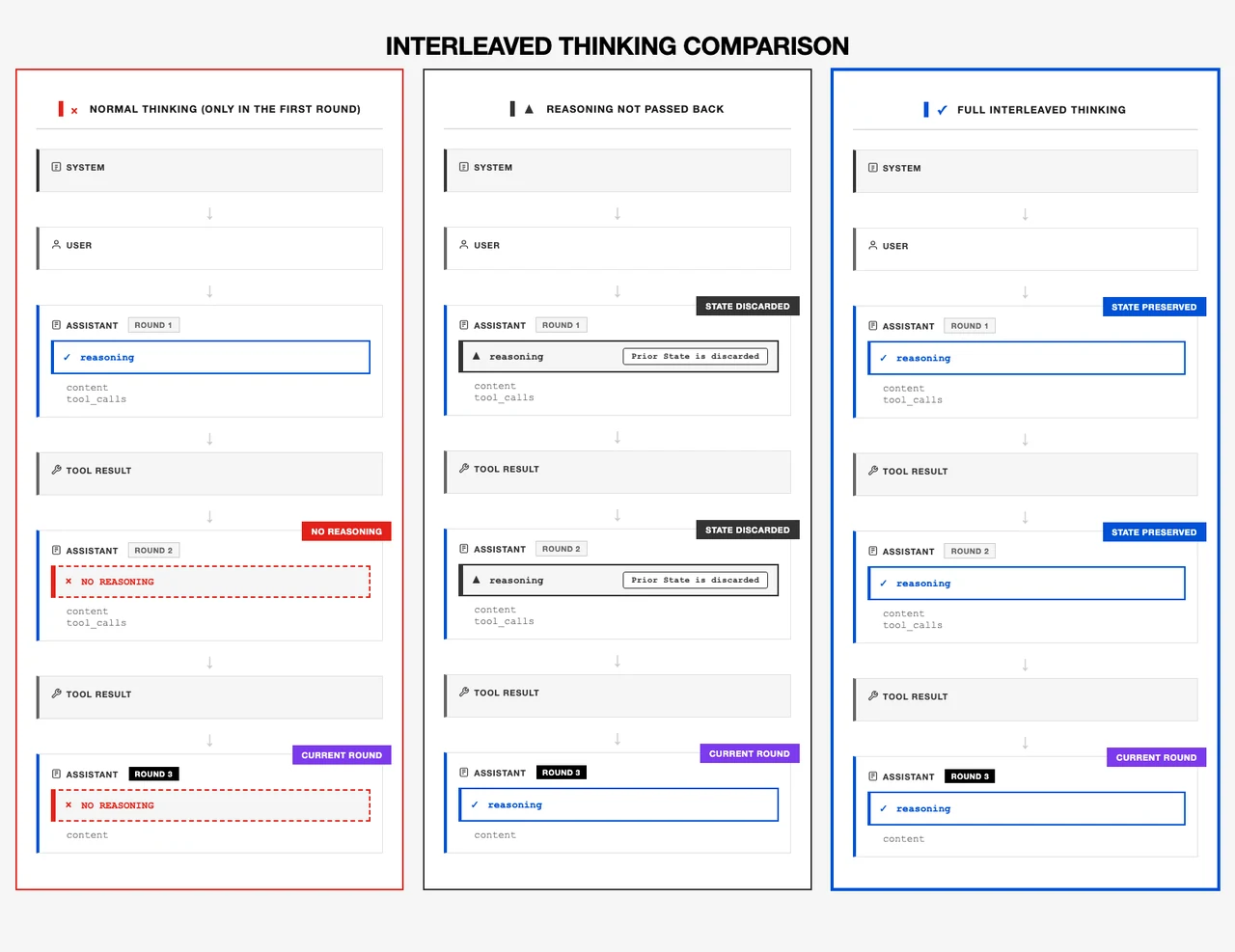
De Minimax
- Maior Eficiência
Respostas mais curtas, menor uso de tokens e interação mais rápida, otimizadas para codificação contínua e tarefas de longa duração.
Um Exemplo:
De Mimimax
Hardware do Minimax M2.1 e Como Usá-lo Localmente?
Para a grande maioria das cargas de trabalho de codificação e agentes, quatro GPUs da classe de 80 a 96 GB lidam confortavelmente com uma janela de contexto de 200K. A configuração de 8 GPUs se torna necessária apenas ao operar no regime de contexto estendido de milhões de tokens.
| Configuração | Contexto Máximo | Caso de Uso |
|---|---|---|
| 4× A100 ou A800 (80 GB) | 400K tokens | Implantações padrão |
| 4× H200 ou H20 (96 GB+) | 400K tokens | Implantações padrão |
| 8× H200 (141 GB) | 3M tokens | Cargas de trabalho de contexto estendido |
A Novita oferece o menor preço sob demanda para H100 a US$ 1,45/hora, até 30% mais barato que outros provedores com desempenho de GPU idêntico.
Experimente GPUs Baratos Agora!
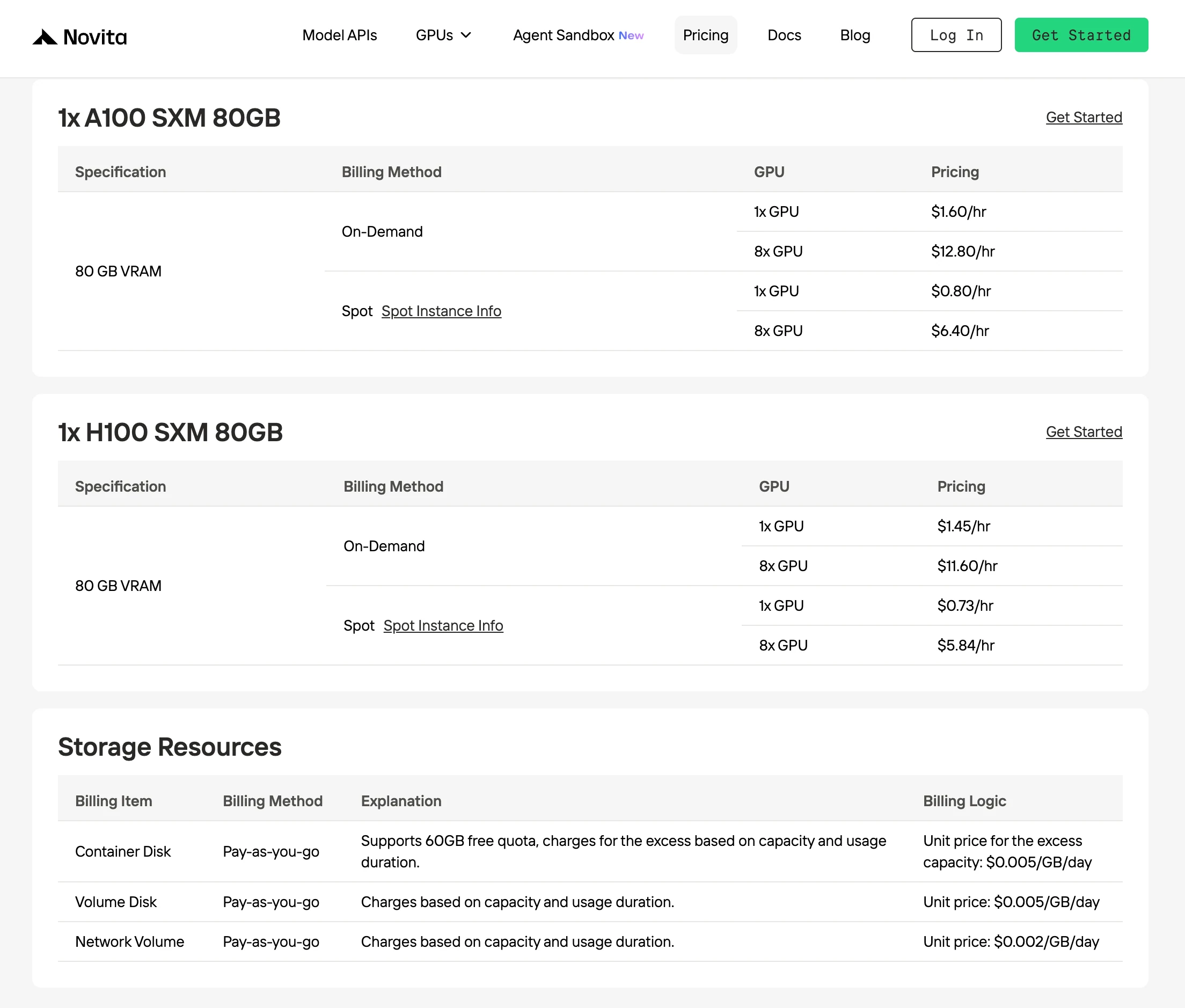
O Spotmode da Novita AI é uma opção de aluguel de GPU otimizada para custos que aproveita a capacidade de GPU não utilizada ou ociosa da plataforma. Ao contrário das instâncias sob demanda, que reservam hardware dedicado para uso contínuo garantido, as instâncias Spot são interrompíveis — oferecidas a preços significativamente mais baixos, tipicamente 40–60% mais baratas.
Esse modelo de preços funciona porque a Novita realoca dinamicamente GPUs ociosas para usuários de curto prazo, em vez de deixá-las sem uso. Ao fazer isso, a plataforma melhora a eficiência geral de utilização da infraestrutura, enquanto os desenvolvedores se beneficiam de custos computacionais muito mais baixos para cargas de trabalho flexíveis.
Como Usar o Minimax M2.1 por um Bom Preço?
Conecte o Minimax M2.1 Falsh sem interrupções aos seus aplicativos, fluxos de trabalho ou chatbots com a API REST unificada da Novita AI — não é necessário gerenciar pesos de modelo ou infraestrutura. A Novita AI oferece SDKs multilíngues (Python, Node.js, cURL e outros) e controles de parâmetros avançados para usuários avançados.
Opção 1: Integração Direta de API (Exemplo em Python)
Principais Funcionalidades:
- Endpoint unificado:
/v3/openaisuporta o formato da API de Conclusões de Chat da OpenAI. - Controles flexíveis: Ajuste temperatura, top-p, penalidades e mais para resultados personalizados.
- Streaming e agrupamento: Escolha o modo de resposta de sua preferência.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Experimente o Minimax M2.1 Agora!
Passo 3: Inicie Seu Teste Gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
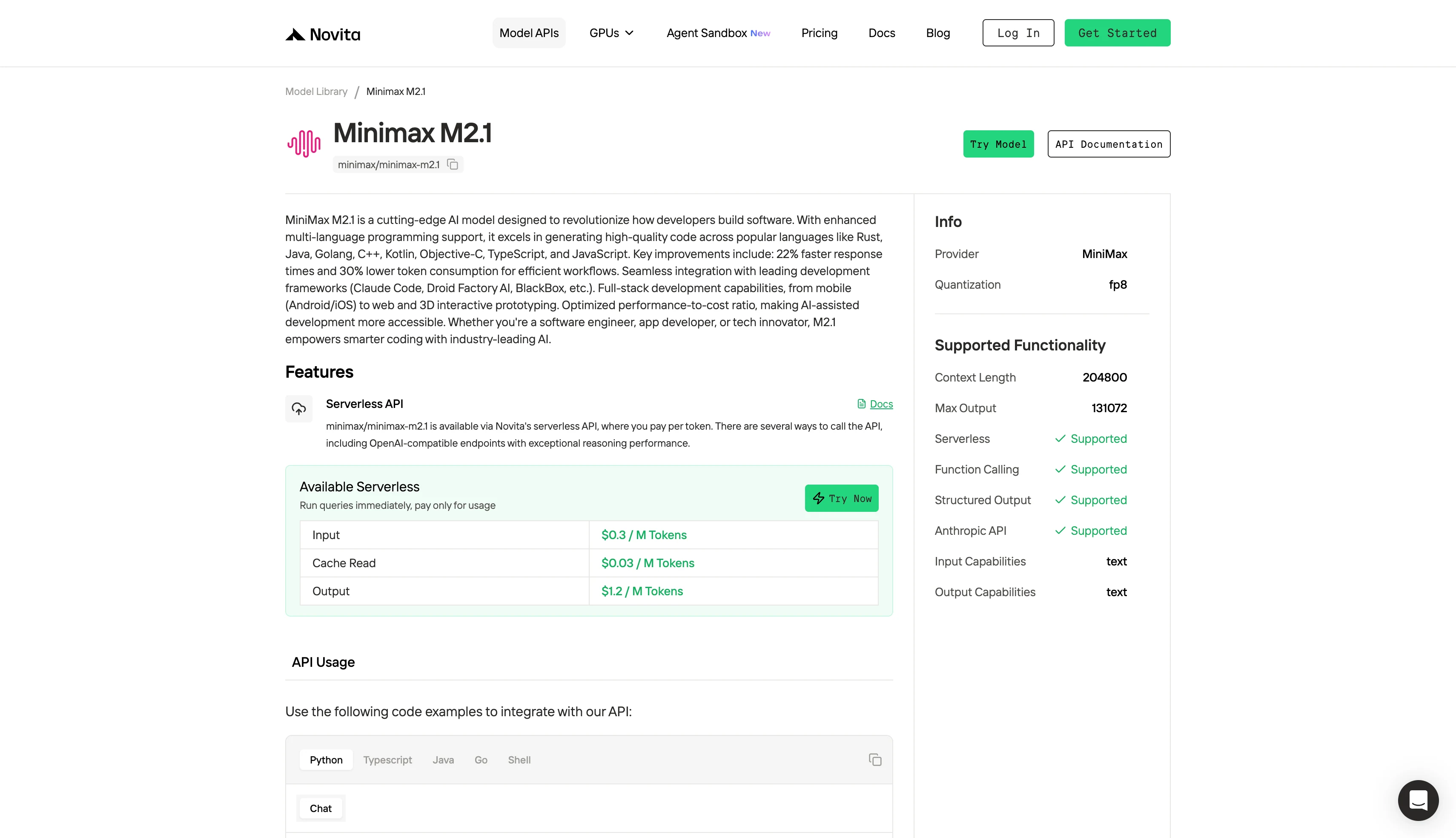
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API para você. Acessando a página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Opção 2: Fluxos de Trabalho Multi-Agente com o SDK OpenAI Agents
Construa sistemas multi-agente avançados integrando a Novita AI com o OpenAI Agents SDK:
- Plug-and-play: Use os LLMs da Novita AI em qualquer fluxo de trabalho do OpenAI Agents.
- Suporta transferências, roteamento e uso de ferramentas: Projete agentes que podem delegar, triar ou executar funções, todos alimentados pelos modelos da Novita AI.
- Integração com Python: Aponte o SDK simplesmente para o endpoint da Novita (
https://api.novita.ai/v3/openai) e use sua chave de API.
Opção 3:Conecte a API GLM 4.7 Flash em Plataformas de Terceiros
- Hugging Face: Use o MInimax M2.1 em Spaces, pipelines ou com a biblioteca Transformers via endpoints da Novita AI.
- Frameworks de Agente e Orquestração: Conecte facilmente a Novita AI com plataformas parceiras como Continue, AnythingLLM,LangChain, Dify e Langflow por meio de conectores oficiais e guias de integração passo a passo.
- API Compatível com OpenAI: Aproveite uma migração e integração sem complicações com ferramentas como Cline e Cursor, projetadas para o padrão de API da OpenAI.
Além disso, com base nas recomendações do Reddit, usar o Minimax M2.1 junto com o GLM 4.7 funciona especialmente bem. A Novita AI também fornece uma API para o GLM 4.7, e você pode clicar no botão abaixo para explorá-la.
Experimente a API de Modelos Diversos Agora!
O Minimax M2.1 oferece uma combinação rara de contexto de escala de fronteira, eficiência MoE e velocidade de loop de agente, tornando-o uma escolha de nível de produção para codificação contínua e sistemas multi-agente. Ele desloca a otimização da inteligência de pico para o throughput real de desenvolvedores.
Por que o Minimax M2.1 é adequado para codificação de longo contexto?
O Minimax M2.1 suporta uma janela de contexto de 204.800 tokens, permitindo raciocínio em todo o repositório e refatorações de múltiplos arquivos em uma única passagem.
O Minimax M2.1 é melhor que o Claude para agentes de codificação?
Para desenvolvimento contínuo e loops de agente, o Minimax M2.1 enfatiza iteração mais rápida e responsividade no estilo IDE em comparação com o Claude.
Qual é a forma mais econômica de usar o Minimax M2.1?
Usar o Minimax M2.1 por meio da API compatível com OpenAI da Novita AI ou do modo Spot GPU oferece custo operacional significativamente menor para cargas de trabalho de produção.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer nuvem de GPU acessível e confiável para construção e escalonamento.



