

Les développeurs ont aujourd’hui du mal à trouver un équilibre entre vitesse, coût et performances lorsqu’ils choisissent un LLM pour des systèmes de codage et d’agents concrets. Cet article explique comment Minimax M2.1 résout ces problèmes en analysant son architecture, ses benchmarks, son profil matériel et ses chemins de déploiement, permettant aux équipes de sélectionner et d’intégrer le modèle le plus adapté aux flux de travail de développement à haute fréquence.
Architecture de Minimax M2.1
| Spécification | Valeur |
|---|---|
| Model ID | MiniMaxAI/MiniMax-M2.1 |
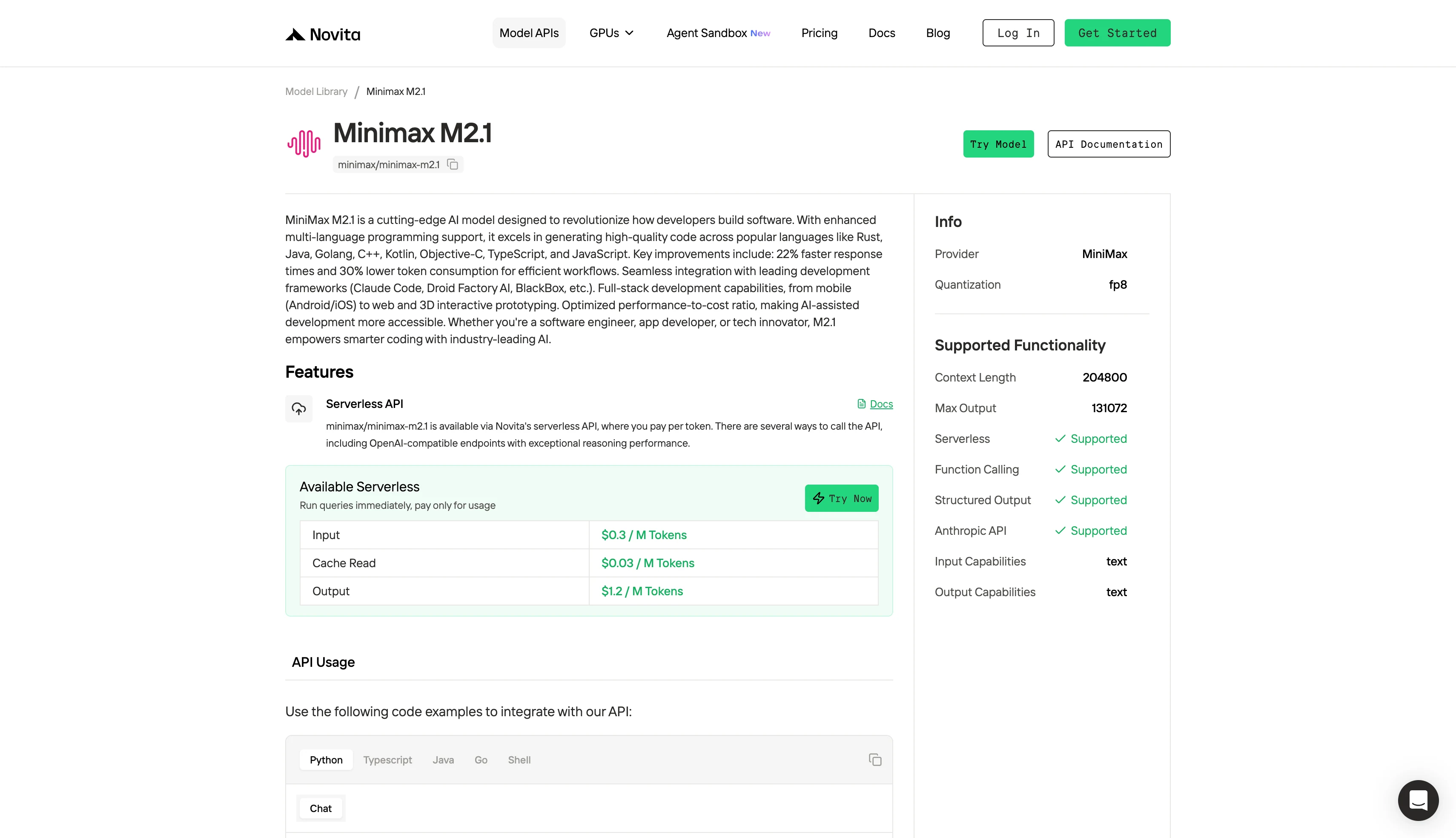
| Total parameters | 230B |
| Active parameters | 10B (MoE) |
| Context window | 204,800 tokens |
| Max output | 131,072 tokens |
| Précision | FP8 |
| License | Modified MIT |
| Weights | https://huggingface.co/MiniMaxAI/MiniMax-M2.1 |
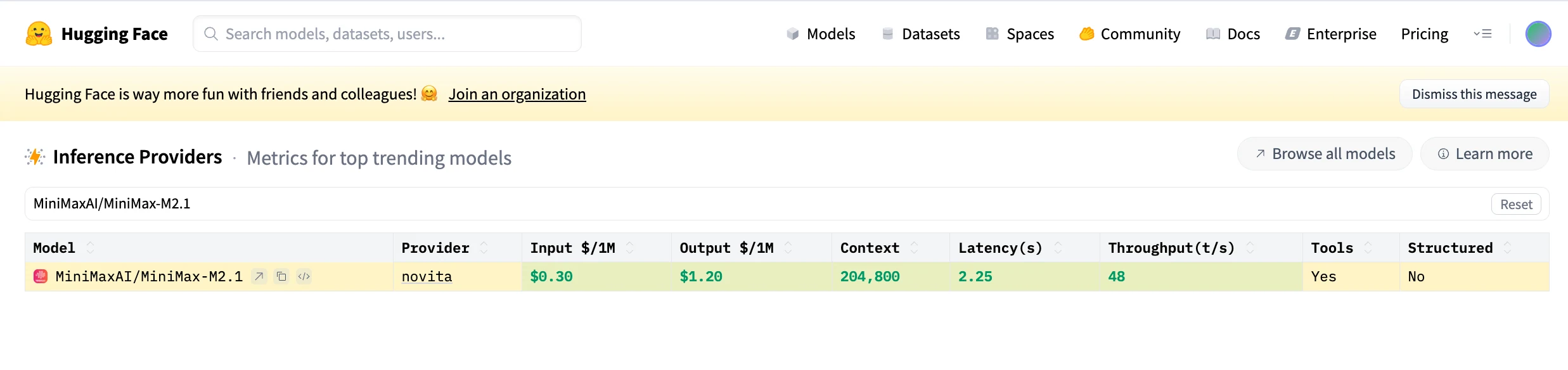
Capacités d’agent de programmation de Minimax M2.1
Par rapport à Claude, qui excelle dans le raisonnement général et la cohérence conversationnelle, MiniMax M2.1 met l’accent sur l’exhaustivité technique : un comportement de boucle d’agent plus rapide, une orchestration multilingue plus performante et une meilleure adéquation avec les flux de travail réels de type IDE, ce qui le rend plus adapté au codage continu, au développement mobile et aux systèmes d’agents de longue durée.
- Maîtrise multilingue
Des performances de premier plan dans les langages Rust, Java, Go, C++, Kotlin, Objective-C, TypeScript et JavaScript, couvrant l’ensemble de la pile technique, des systèmes aux applications.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 74.0 | 69.4 | 77.2 | 80.9 | 78.0 | 80.0 | 73.1 |
| Multi-SWE-bench | 49.4 | 36.2 | 44.3 | 50.0 | 42.7 | x | 37.4 |
| SWE-bench Multilingual | 72.5 | 56.5 | 68 | 77.5 | 65.0 | 72.0 | 70.2 |
| Terminal-bench 2.0 | 47.9 | 30.0 | 50.0 | 57.8 | 54.2 | 54.0 | 46.4 |
- Développement web et d’applications
Une prise en charge native solide d’Android et iOS, avec des capacités avancées pour les interactions complexes, les simulations 3D et la visualisation de haute qualité.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified (Droid) | 71.3 | 68.1 | 72.3 | 75.2 | x | x | 67.0 |
| SWE-bench Verified (mini-swe-agent) | 67.0 | 61.0 | 70.6 | 74.4 | 71.8 | 74.2 | 60.0 |
| SWT-bench | 69.3 | 32.8 | 69.5 | 80.2 | 79.7 | 80.7 | 62.0 |
| SWE-Perf | 3.1 | 1.4 | 3.0 | 4.7 | 6.5 | 3.6 | 0.9 |
| SWE-Review | 8.9 | 3.4 | 10.5 | 16.2 | x | x | 6.4 |
| OctoCodingbench | 26.1 | 13.3 | 22.8 | 36.2 | 22.9 | x | 26.0 |
Un exemple :
Capacités d’agent à haute fréquence de Minimax M2.1
- Raisonnement de qualité bureautique
L’Interleaved Thinking et l’exécution d’instructions composites permettent de gérer de manière fiable des flux de travail concrets multi-objectifs.
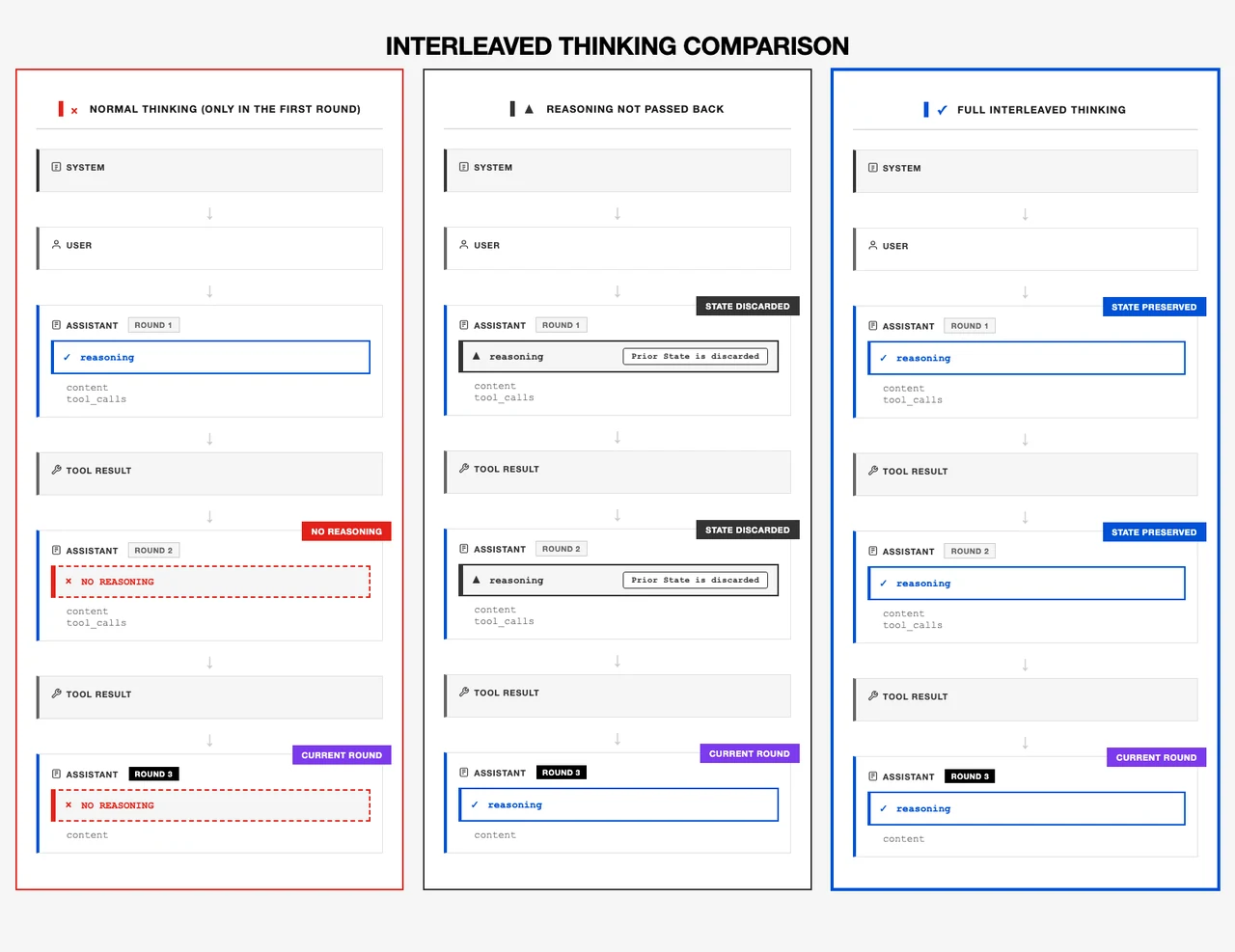
Source : Minimax
- Efficacité accrue
Des réponses plus courtes, une utilisation de tokens réduite et des interactions plus rapides, optimisées pour le codage continu et les tâches de longue durée.
Un exemple :
Source : Mimimax
Matériel pour Minimax M2.1 et comment l’utiliser localement ?
Pour la grande majorité des charges de travail de codage et d’agents, quatre GPU de la classe 80 à 96 Go gèrent confortablement une fenêtre de contexte de 200K tokens. La configuration à 8 GPU n’est nécessaire que lorsque l’on opère dans le régime de contexte étendu à plusieurs millions de tokens.
| Configuration | Contexte maximum | Cas d’usage |
|---|---|---|
| 4× A100 ou A800 (80 Go) | 400K tokens | Déploiements standards |
| 4× H200 ou H20 (96 Go+) | 400K tokens | Déploiements standards |
| 8× H200 (141 Go) | 3M tokens | Charges de travail à contexte étendu |
Novita propose les tarifs de location à la demande de H100 les plus bas, à 1,45 $/h, soit jusqu’à 30 % moins cher que les autres fournisseurs avec des performances GPU identiques.
Essayez des GPU bon marché dès maintenant !
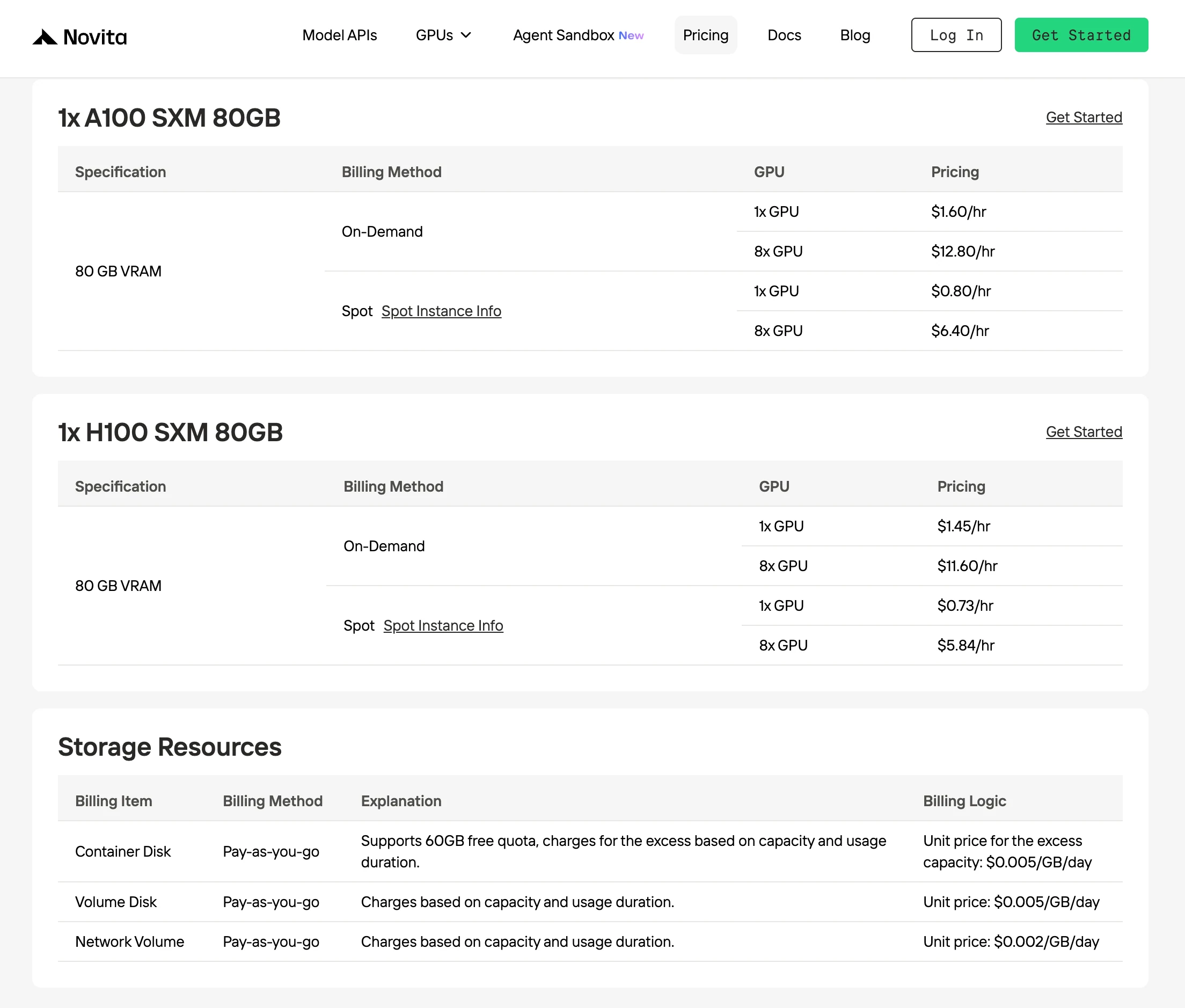
Le Spotmode de Novita AI est une option de location de GPU optimisée sur le coût qui exploite la capacité GPU inutilisée ou inactive de la plateforme. Contrairement aux instances à la demande, qui réservent du matériel dédié pour une utilisation continue garantie, les instances Spot sont interruptibles et proposées à des tarifs significativement plus bas, généralement 40 à 60 % moins chers.
Ce modèle tarifaire fonctionne car Novita réaffecte dynamiquement les GPU inactifs aux utilisateurs à court terme au lieu de les laisser inutilisés. Ce faisant, la plateforme améliore l’efficacité globale d’utilisation de l’infrastructure, tandis que les développeurs bénéficient de coûts de calcul beaucoup plus bas pour des charges de travail flexibles.
Comment utiliser Minimax M2.1 à un bon prix ?
Connectez Minimax M2.1 Falsh de manière transparente à vos applications, flux de travail ou chatbots grâce à l’API REST unifiée de Novita AI : pas besoin de gérer les poids du modèle ou l’infrastructure. Novita AI propose des SDK multilingues (Python, Node.js, cURL, et plus encore) et des contrôles de paramètres avancés pour les utilisateurs expérimentés.
Option 1 : Intégration API directe (exemple en Python)
Fonctionnalités clés :
- Point de terminaison unifié :
/v3/openaiprend en charge le format de l’API Chat Completions d’OpenAI. - Contrôles flexibles : Ajustez la température, le top-p, les pénalités et plus encore pour obtenir des résultats adaptés à vos besoins.
- Flux et traitement par lots : Choisissez le mode de réponse qui vous convient.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Essayez Minimax M2.1 dès maintenant !
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2 : Flux de travail multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents avancés en intégrant Novita AI avec le SDK OpenAI Agents :
- Prêt à l’emploi : Utilisez les LLM de Novita AI dans tout flux de travail OpenAI Agents.
- Prend en charge les transferts, le routage et l’utilisation d’outils : Concevez des agents capables de déléguer, de trier ou d’exécuter des fonctions, le tout alimenté par les modèles de Novita AI.
- Intégration Python : Il suffit de pointer le SDK vers le point de terminaison de Novita (
https://api.novita.ai/v3/openai) et d’utiliser votre clé API.
Option 3:Connectez l’API GLM 4.7 Flash sur des plateformes tierces
- Hugging Face : Utilisez MInimax M2.1 dans les Spaces, les pipelines ou avec la bibliothèque Transformers via les points de terminaison Novita AI.
- Frameworks d’agents et d’orchestration : Connectez facilement Novita AI à des plateformes partenaires comme Continue, AnythingLLM,LangChain, Dify et Langflow grâce à des connecteurs officiels et des guides d’intégration étape par étape.
- API compatible OpenAI : Profitez d’une migration et d’une intégration sans problème avec des outils comme Cline et Cursor, conçus pour la norme d’API OpenAI.
De plus, d’après les recommandations de Reddit, l’utilisation de Minimax M2.1 en association avec GLM 4.7 donne des résultats particulièrement bons. Novita AI propose également une API pour GLM 4.7, et vous pouvez cliquer sur le bouton ci-dessous pour l’explorer.
Essayez l’API de modèles divers dès maintenant !
Minimax M2.1 offre une combinaison rare de contexte à l’échelle de l’état de l’art, d’efficacité MoE et de vitesse de boucle d’agent, ce qui en fait un choix de qualité production pour le codage continu et les systèmes multi-agents. Il déplace l’optimisation de l’intelligence maximale vers le débit réel des développeurs.
Pourquoi Minimax M2.1 est-il adapté au codage avec contexte long ?
Minimax M2.1 prend en charge une fenêtre de contexte de 204 800 tokens, permettant un raisonnement sur l’ensemble du dépôt et des refactorisations multi-fichiers en une seule passe.
Minimax M2.1 est-il meilleur que Claude pour les agents de codage ?
Pour le développement continu et les boucles d’agents, Minimax M2.1 met l’accent sur des itérations plus rapides et une réactivité de type IDE par rapport à Claude.
Quelle est la méthode la plus rentable pour utiliser Minimax M2.1 ?
L’utilisation de Minimax M2.1 via l’API compatible OpenAI de Novita AI ou le mode Spot GPU permet de réduire considérablement les coûts opérationnels pour les charges de travail de production.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA grâce à notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.



