

Los desarrolladores actuales tienen dificultades para equilibrar velocidad, costo y capacidad al elegir un LLM para sistemas de codificación y agentes reales. Este artículo aclara cómo Minimax M2.1 resuelve estos problemas analizando su arquitectura, benchmarks, perfil de hardware y rutas de despliegue, permitiendo a los equipos seleccionar e integrar el modelo más práctico para flujos de trabajo de desarrollo de alta frecuencia.
Arquitectura de Minimax M2.1
| Especificación | Valor |
|---|---|
| ID del modelo | MiniMaxAI/MiniMax-M2.1 |
| Parámetros totales | 230B |
| Parámetros activos | 10B (MoE) |
| Ventana de contexto | 204,800 tokens |
| Salida máxima | 131,072 tokens |
| Precisión | FP8 |
| Licencia | Modified MIT |
| Pesos | https://huggingface.co/MiniMaxAI/MiniMax-M2.1 |
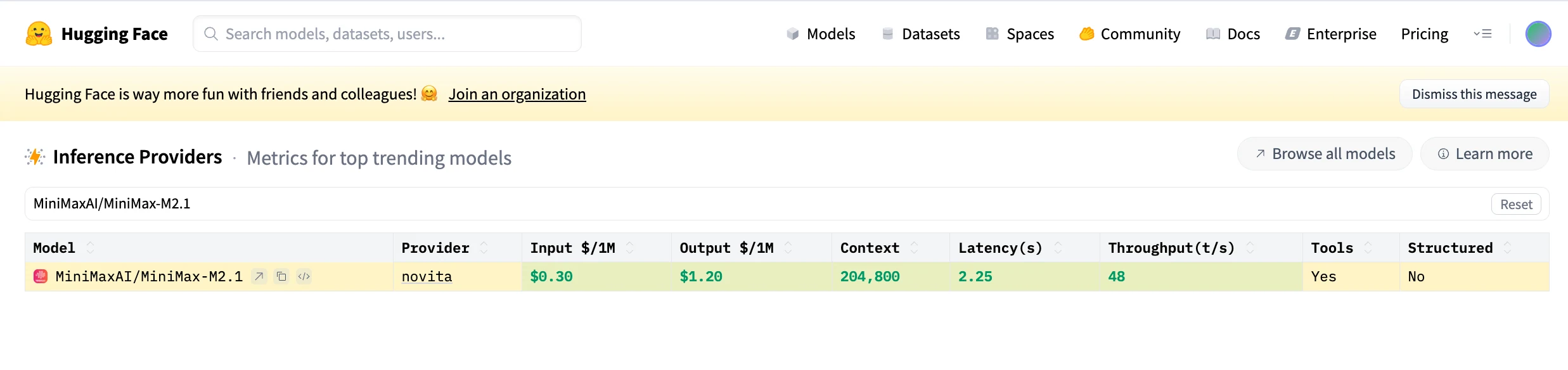
Capacidad de Agente de Programación de Minimax M2.1
En comparación con Claude, que sobresale en razonamiento general y coherencia conversacional, MiniMax M2.1 enfatiza la integridad de ingeniería: comportamiento de bucle de agente más rápido, orquestación multilingüe más fuerte y mejor alineación con flujos de trabajo de estilo IDE real, lo que lo hace más adecuado para codificación continua, desarrollo móvil y sistemas de agente de larga duración.
- Dominio multilingüe
Rendimiento líder en la industria en Rust, Java, Go, C++, Kotlin, Objective-C, TypeScript y JavaScript, cubriendo toda la pila desde sistemas hasta aplicaciones.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 74.0 | 69.4 | 77.2 | 80.9 | 78.0 | 80.0 | 73.1 |
| Multi-SWE-bench | 49.4 | 36.2 | 44.3 | 50.0 | 42.7 | x | 37.4 |
| SWE-bench Multilingual | 72.5 | 56.5 | 68 | 77.5 | 65.0 | 72.0 | 70.2 |
| Terminal-bench 2.0 | 47.9 | 30.0 | 50.0 | 57.8 | 54.2 | 54.0 | 46.4 |
- Desarrollo web y de aplicaciones
Soporte nativo sólido para Android e iOS, con capacidad avanzada en interacciones complejas, simulaciones 3D y visualización de alta calidad.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified (Droid) | 71.3 | 68.1 | 72.3 | 75.2 | x | x | 67.0 |
| SWE-bench Verified (mini-swe-agent) | 67.0 | 61.0 | 70.6 | 74.4 | 71.8 | 74.2 | 60.0 |
| SWT-bench | 69.3 | 32.8 | 69.5 | 80.2 | 79.7 | 80.7 | 62.0 |
| SWE-Perf | 3.1 | 1.4 | 3.0 | 4.7 | 6.5 | 3.6 | 0.9 |
| SWE-Review | 8.9 | 3.4 | 10.5 | 16.2 | x | x | 6.4 |
| OctoCodingbench | 26.1 | 13.3 | 22.8 | 36.2 | 22.9 | x | 26.0 |
Un ejemplo:
Capacidad de Agente de Alta Frecuencia de Minimax M2.1
- Razonamiento de nivel oficina
El pensamiento intercalado y la ejecución de instrucciones compuestas permiten manejar de manera confiable flujos de trabajo del mundo real con múltiples objetivos.
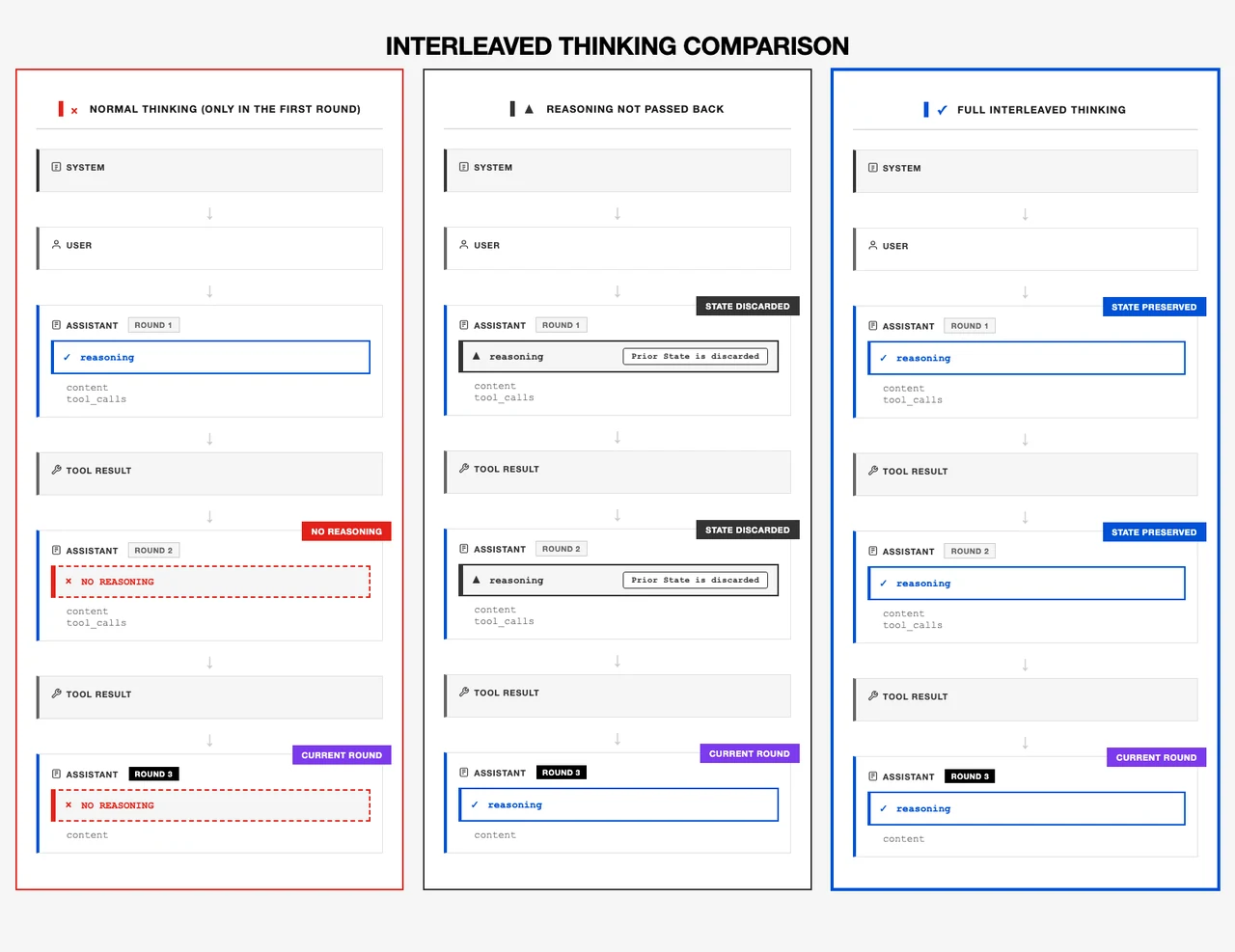
De Minimax
- Mayor eficiencia
Respuestas más cortas, menor uso de tokens e interacción más rápida, optimizado para codificación continua y tareas de larga duración.
Un ejemplo:
De Mimimax
Hardware de Minimax M2.1 y Cómo Usarlo Localmente?
Para la gran mayoría de las cargas de trabajo de codificación y agentes, cuatro GPU en la clase de 80–96 GB manejan cómodamente una ventana de contexto de 200K. La configuración de 8 GPU solo se vuelve necesaria cuando se opera en el régimen de contexto extendido de varios millones de tokens.
| Configuración | Contexto máximo | Caso de uso |
|---|---|---|
| 4× A100 o A800 (80 GB) | 400K tokens | Despliegues estándar |
| 4× H200 o H20 (96 GB+) | 400K tokens | Despliegues estándar |
| 8× H200 (141 GB) | 3M tokens | Cargas de trabajo de contexto extendido |
Novita ofrece el precio bajo demanda más bajo para H100 a $1.45/hora, hasta un 30% más barato que otros proveedores con rendimiento de GPU idéntico.
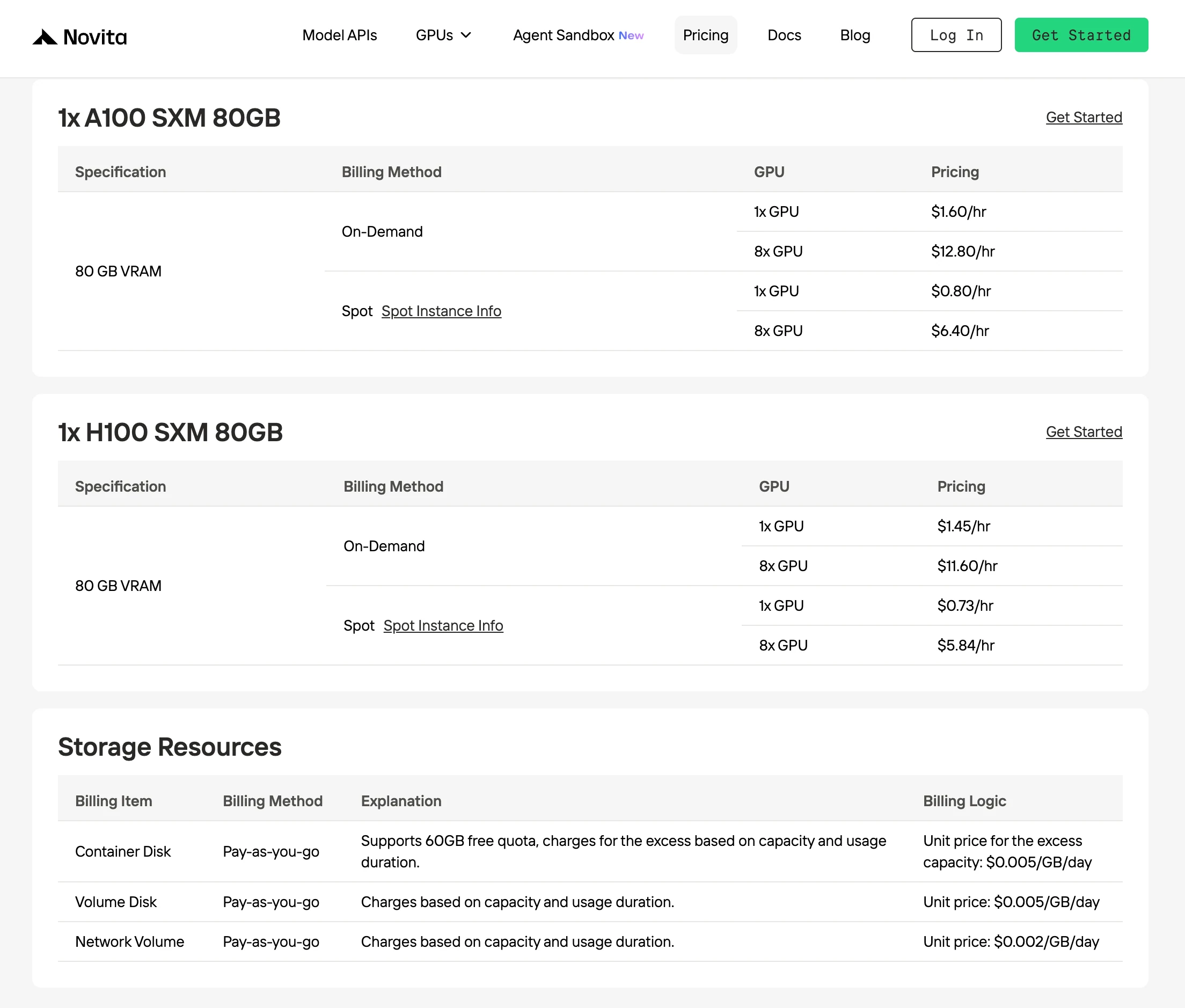
El Spotmode de Novita AI es una opción de alquiler de GPU optimizada en costo que aprovecha la capacidad GPU no utilizada o inactiva de la plataforma. A diferencia de las instancias bajo demanda, que reservan hardware dedicado para uso continuo garantizado, las instancias Spot son interrumpibles y se ofrecen a precios significativamente más bajos, típicamente 40–60% más baratas.
Este modelo de precios funciona porque Novita reasigna dinámicamente las GPU inactivas a usuarios a corto plazo en lugar de dejarlas sin usar. Al hacerlo, la plataforma mejora la eficiencia general de utilización de la infraestructura, mientras que los desarrolladores se benefician de costos computacionales mucho más bajos para cargas de trabajo flexibles.
¿Cómo Usar Minimax M2.1 a un Buen Precio?
Conecta sin problemas Minimax M2.1 Flash a tus aplicaciones, flujos de trabajo o chatbots con la API REST unificada de Novita AI, sin necesidad de gestionar pesos de modelo ni infraestructura. Novita AI ofrece SDKs multilingües (Python, Node.js, cURL y más) y controles de parámetros avanzados para usuarios avanzados.
Opción 1: Integración directa con la API (Ejemplo en Python)
Características clave:
- Endpoint unificado:
/v3/openaisoporta el formato de la API Chat Completions de OpenAI. - Controles flexibles: Ajusta temperature, top-p, penalties y más para obtener resultados personalizados.
- Streaming y lotes: Elige tu modo de respuesta preferido.
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
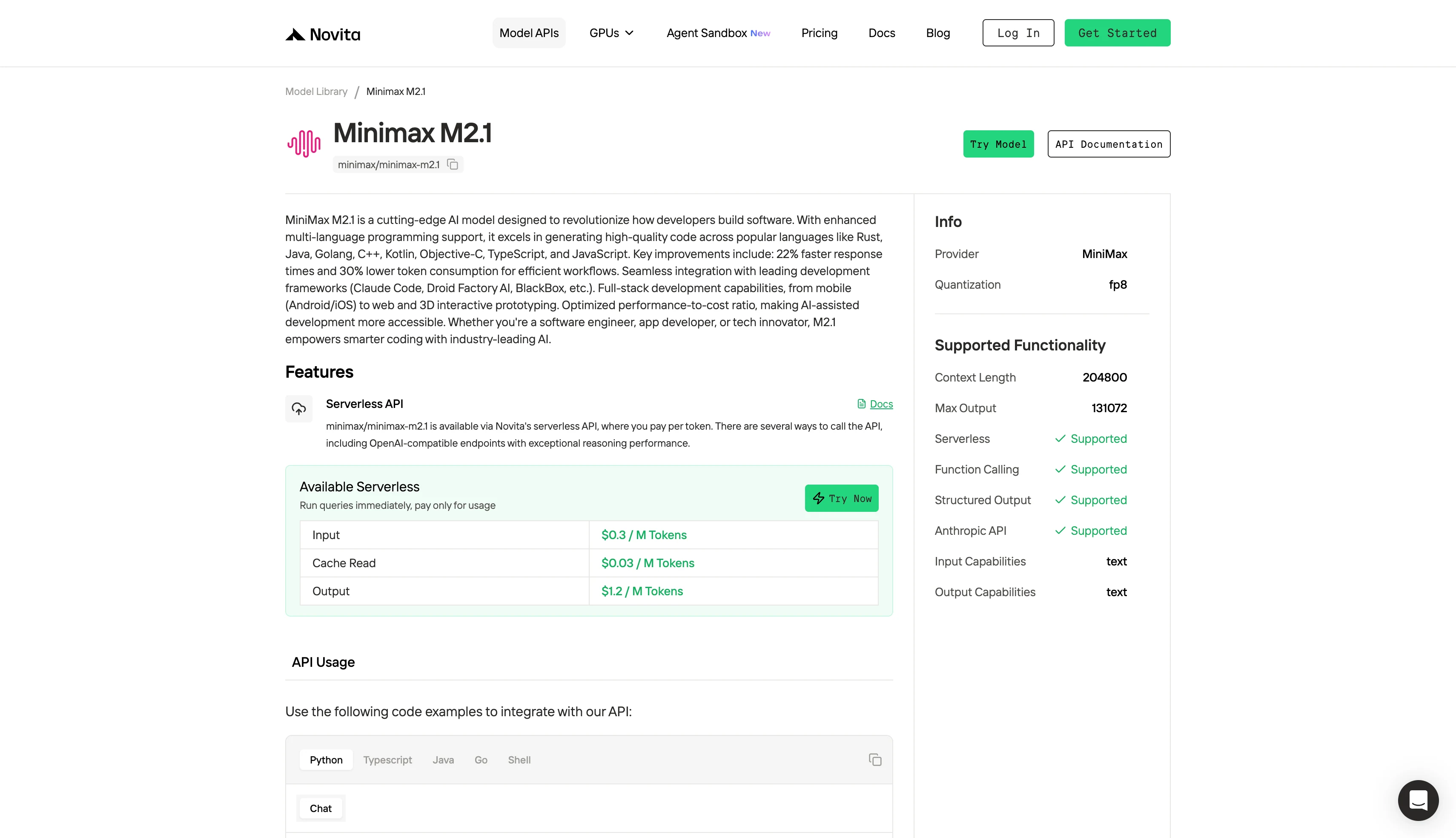
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Settings”, puedes copiar la clave API como se indica en la imagen.

from openai import OpenAI
client = OpenAI(
api_key="<Tu Clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Opción 2: Flujos de trabajo multi-agente con OpenAI Agents SDK
Construye sistemas multi-agente avanzados integrando Novita AI con el OpenAI Agents SDK:
- Plug-and-play: Usa los LLM de Novita AI en cualquier flujo de trabajo de OpenAI Agents.
- Soporta transferencias, enrutamiento y uso de herramientas: Diseña agentes que puedan delegar, clasificar o ejecutar funciones, todo impulsado por los modelos de Novita AI.
- Integración Python: Simplemente apunta el SDK al endpoint de Novita (
https://api.novita.ai/v3/openai) y usa tu clave API.
Opción 3: Conecta la API de GLM 4.7 Flash en plataformas de terceros
- Hugging Face: Usa Minimax M2.1 en Spaces, pipelines o con la biblioteca Transformers a través de los endpoints de Novita AI.
- Frameworks de Agentes y Orquestación: Conecta fácilmente Novita AI con plataformas asociadas como Continue, AnythingLLM, LangChain, Dify y Langflow a través de conectores oficiales y guías de integración paso a paso.
- API compatible con OpenAI: Disfruta de una migración e integración sin problemas con herramientas como Cline y Cursor, diseñadas para el estándar de API de OpenAI.
Además, según recomendaciones de Reddit, usar Minimax M2.1 junto con GLM 4.7 funciona especialmente bien. Novita AI también proporciona una API para GLM 4.7, y puedes hacer clic en el botón de abajo para explorarla.
¡Prueba la API de modelos diversos ahora!
Minimax M2.1 ofrece una combinación poco común de contexto de escala fronteriza, eficiencia MoE y velocidad de bucle de agente, lo que lo convierte en una opción de nivel de producción para codificación continua y sistemas multi-agente. Cambia la optimización de la inteligencia máxima al rendimiento real del desarrollador.
¿Por qué es Minimax M2.1 adecuado para codificación de contexto largo?
Minimax M2.1 soporta una ventana de contexto de 204,800 tokens, lo que permite razonamiento sobre el repositorio completo y refactorizaciones de múltiples archivos en una sola pasada.
¿Es Minimax M2.1 mejor que Claude para agentes de codificación?
Para desarrollo continuo y bucles de agente, Minimax M2.1 enfatiza iteraciones más rápidas y capacidad de respuesta al estilo IDE en comparación con Claude.
¿Cuál es la forma más rentable de usar Minimax M2.1?
Usar Minimax M2.1 a través de la API compatible con OpenAI de Novita AI o el modo GPU Spot ofrece un costo operativo significativamente menor para cargas de trabajo de producción.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma fácil de implementar modelos de IA usando su API simple, al mismo tiempo que proporciona nube GPU asequible y confiable para construir y escalar.



