

Сегодня разработчики сталкиваются с трудностями при выборе LLM для реальных рабочих процессов кодирования и систем агентов, пытаясь сбалансировать скорость, стоимость и функциональность. В этой статье мы разбираем, как Minimax M2.1 решает эти проблемы, анализируя его архитектуру, результаты бенчмарков, аппаратные требования и варианты развертывания, чтобы команды могли выбрать и интегрировать наиболее практичную модель для высокочастотных рабочих процессов разработки.
Архитектура Minimax M2.1
| Спецификация | Значение |
|---|---|
| Model ID | MiniMaxAI/MiniMax-M2.1 |
| Общее количество параметров | 230B |
| Активные параметры | 10B (MoE) |
| Контекстное окно | 204 800 токенов |
| Максимальный вывод | 131 072 токена |
| Точность | FP8 |
| Лицензия | Modified MIT |
| Weights | https://huggingface.co/MiniMaxAI/MiniMax-M2.1 |
Возможности Minimax M2.1 как программирующего агента
В сравнении с Claude, который выделяется общими возможностями рассуждений и связностью диалога, MiniMax M2.1 делает акцент на полноте инженерных решений: более быстрое поведение цикла агента, более надежная оркестрация для нескольких языков и лучшее соответствие реальным рабочим процессам в стиле IDE, что делает его более подходящим для непрерывного кодирования, мобильной разработки и долго работающих систем агентов.
- Владение несколькими языками
Лидирующие в отрасли результаты на Rust, Java, Go, C++, Kotlin, Objective-C, TypeScript и JavaScript, покрывая весь стек от системного до прикладного уровня.
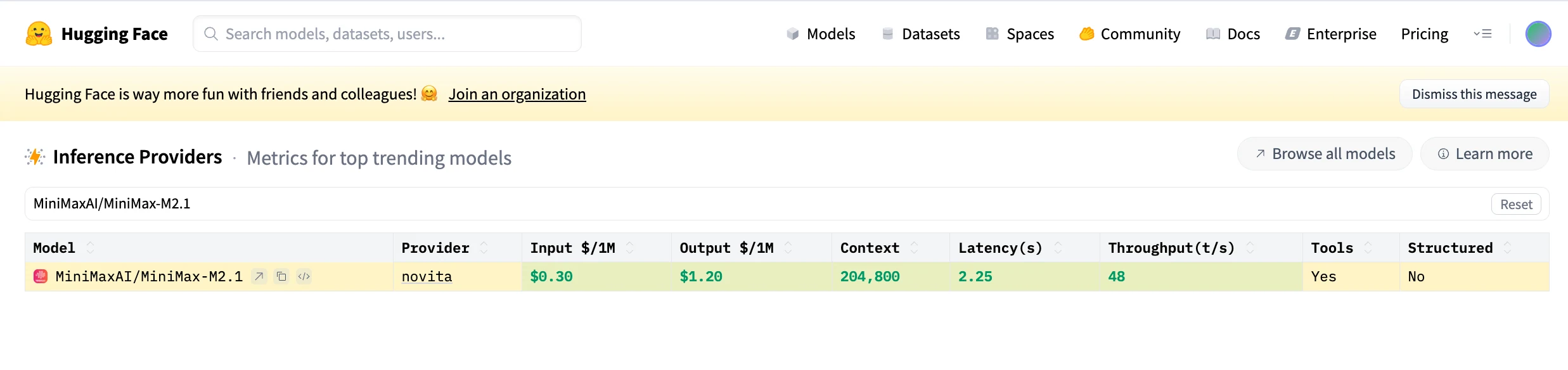
| Бенчмарк | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 74.0 | 69.4 | 77.2 | 80.9 | 78.0 | 80.0 | 73.1 |
| Multi-SWE-bench | 49.4 | 36.2 | 44.3 | 50.0 | 42.7 | x | 37.4 |
| SWE-bench Multilingual | 72.5 | 56.5 | 68 | 77.5 | 65.0 | 72.0 | 70.2 |
| Terminal-bench 2.0 | 47.9 | 30.0 | 50.0 | 57.8 | 54.2 | 54.0 | 46.4 |
- Веб- и разработка приложений
Надежная нативная поддержка Android и iOS, продвинутые возможности для сложных взаимодействий, 3D-симуляций и высококачественной визуализации.
| Бенчмарк | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified (Droid) | 71.3 | 68.1 | 72.3 | 75.2 | x | x | 67.0 |
| SWE-bench Verified (mini-swe-agent) | 67.0 | 61.0 | 70.6 | 74.4 | 71.8 | 74.2 | 60.0 |
| SWT-bench | 69.3 | 32.8 | 69.5 | 80.2 | 79.7 | 80.7 | 62.0 |
| SWE-Perf | 3.1 | 1.4 | 3.0 | 4.7 | 6.5 | 3.6 | 0.9 |
| SWE-Review | 8.9 | 3.4 | 10.5 | 16.2 | x | x | 6.4 |
| OctoCodingbench | 26.1 | 13.3 | 22.8 | 36.2 | 22.9 | x | 26.0 |
Пример:
Возможности Minimax M2.1 как высокочастотного агента
- Рассуждение уровня офисных задач
Interleaved Thinking и выполнение составных инструкций позволяют надежно обрабатывать многоцелевые реальные рабочие процессы.
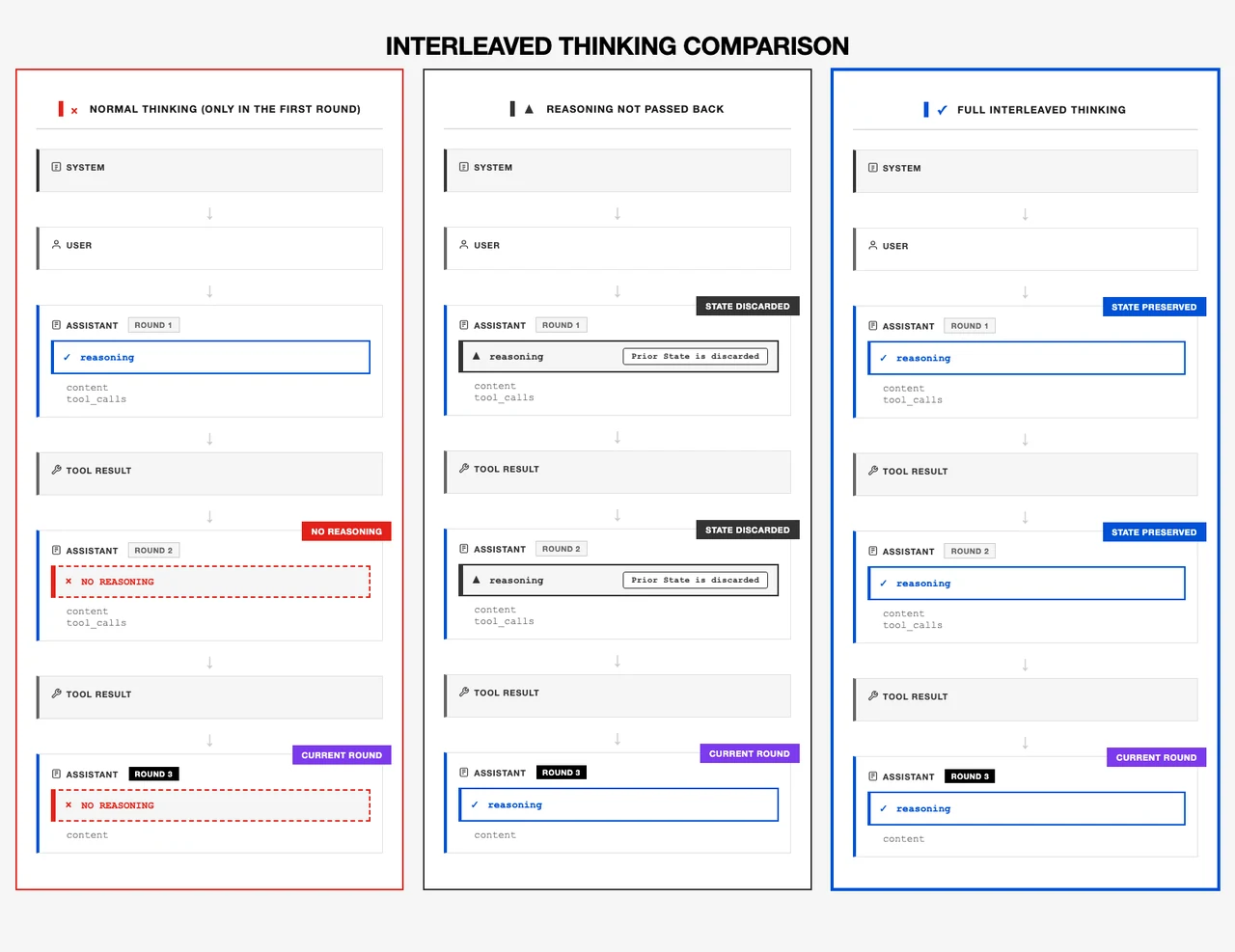
Из: Minimax
- Более высокая эффективность
Более короткие ответы, меньшее использование токенов и быстрое взаимодействие, оптимизированные для непрерывного кодирования и долго выполняемых задач.
Пример:
Из: Mimimax
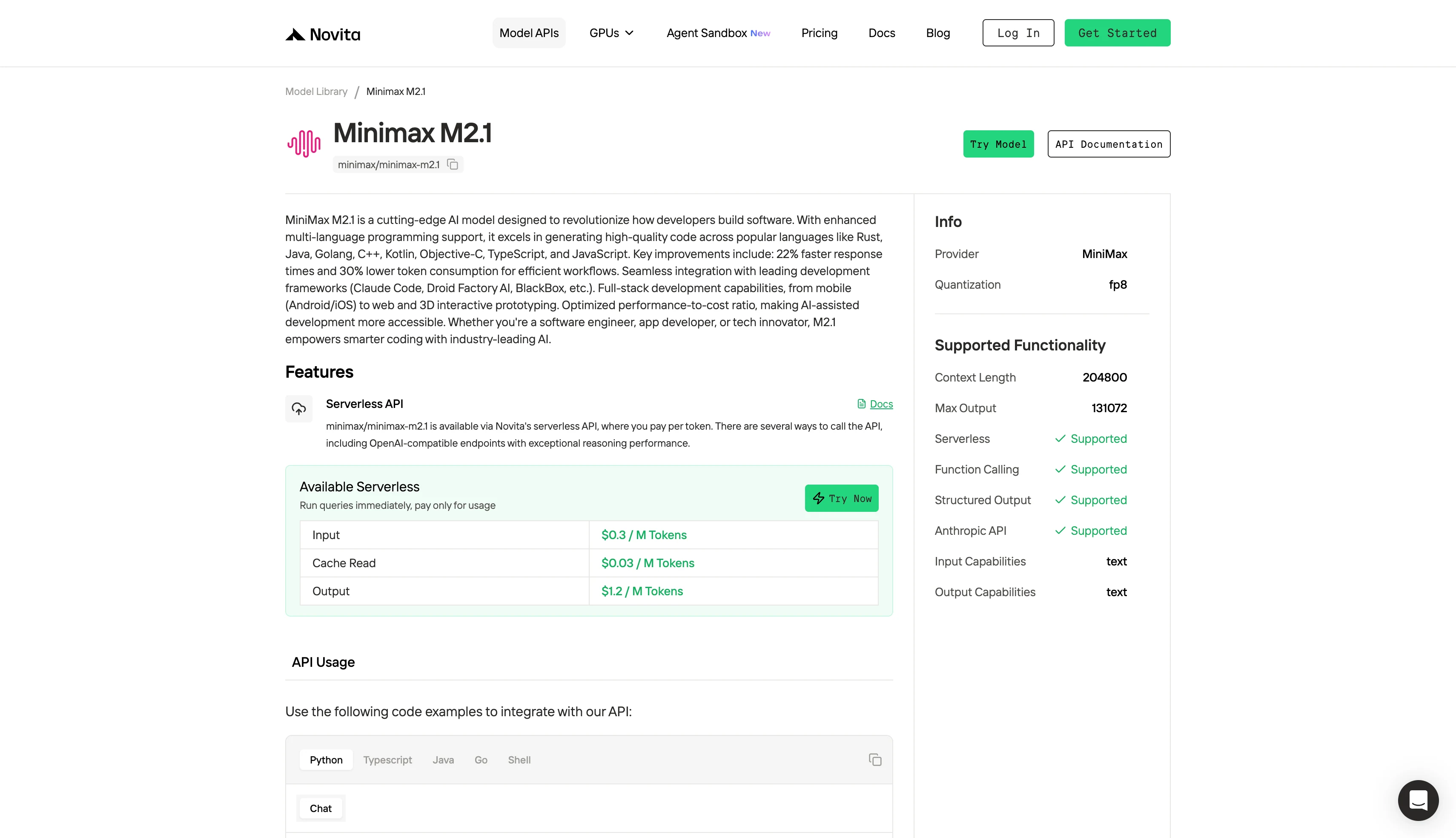
Аппаратные требования для Minimax M2.1 и как запустить его локально?
Для подавляющего большинства рабочих нагрузок, связанных с кодированием и работой агентов, четыре GPU класса 80–96 ГБ без проблем обрабатывают контекстное окно в 200K токенов. Конфигурация из 8 GPU становится необходимой только при работе в режиме расширенного контекста с количеством токенов в несколько миллионов.
| Конфигурация | Максимальный контекст | Сценарий использования |
|---|---|---|
| 4× A100 или A800 (80 ГБ) | 400K токенов | Стандартные развертывания |
| 4× H200 или H20 (96 ГБ+) | 400K токенов | Стандартные развертывания |
| 8× H200 (141 ГБ) | 3M токенов | Рабочие нагрузки с расширенным контекстом |
Novita предлагает самые низкие цены на аренду H100 по запросу — $1.45 в час, что на 30% дешевле, чем у других провайдеров с идентичной производительностью GPU.
Попробуйте дешевые GPU прямо сейчас!
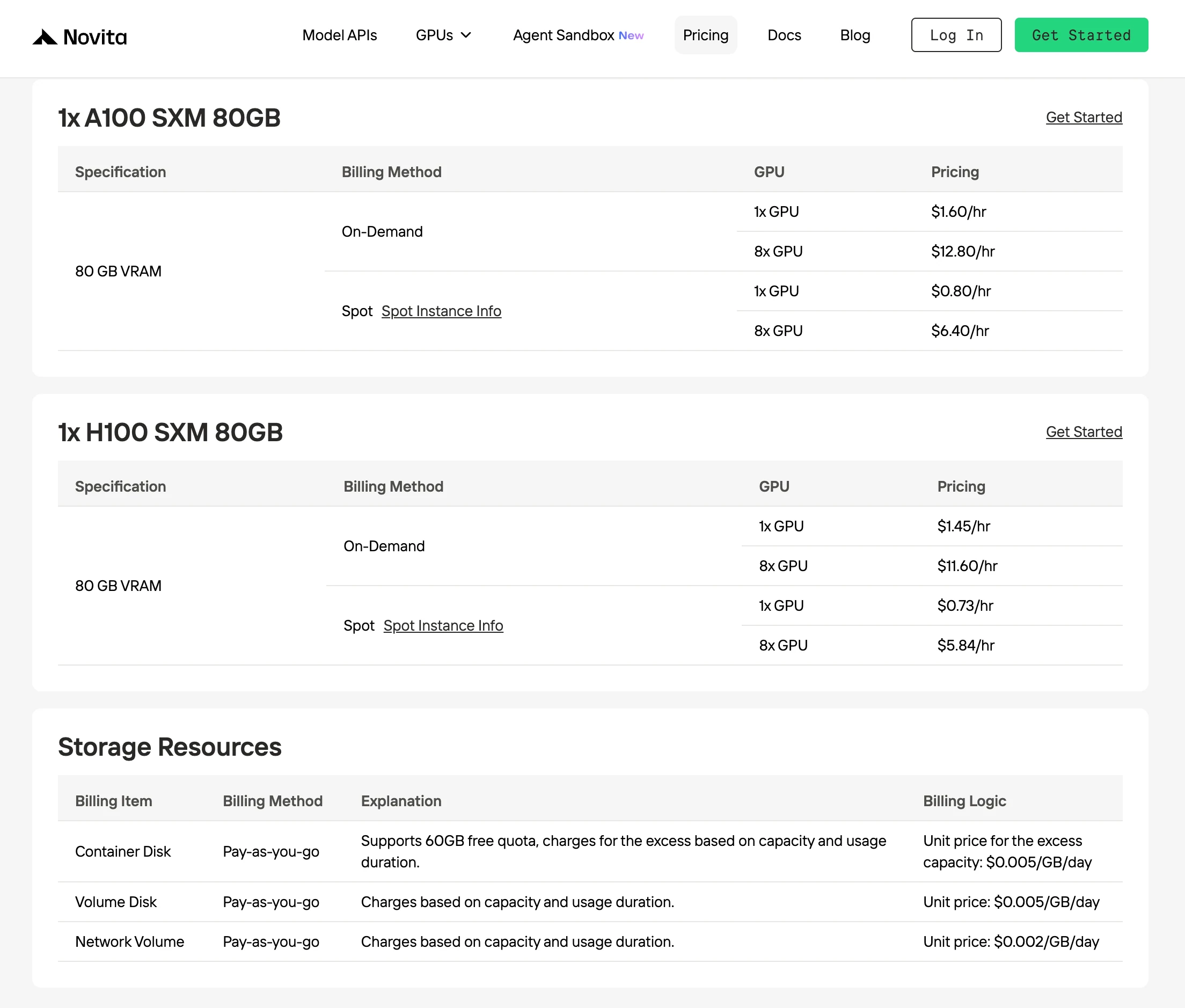
Spotmode от Novita AI — это оптимизированный по стоимости вариант аренды GPU, который использует неиспользуемую или простаивающую мощность GPU платформы. В отличие от инстансов по запросу, которые резервируют выделенное оборудование для гарантированного непрерывного использования, Spot-инстансы являются прерываемыми и предлагаются по значительно более низким ценам, обычно на 40–60% дешевле.
Эта модель ценообразования работает, потому что Novita динамически перераспределяет простаивающие GPU для краткосрочных пользователей, вместо того чтобы оставлять их неиспользуемыми. Благодаря этому платформа повышает общую эффективность использования инфраструктуры, а разработчики получают значительно более низкие вычислительные затраты для гибких рабочих нагрузок.
Как использовать Minimax M2.1 по выгодной цене?
Без проблем подключайте Minimax M2.1 Falsh к вашим приложениям, рабочим процессам или чат-ботам с помощью единого REST API от Novita AI — нет необходимости управлять весами модели или инфраструктурой. Novita AI предлагает многоязычные SDK (Python, Node.js, cURL и другие) и продвинутые настройки параметров для опытных пользователей.
Вариант 1: Прямая интеграция через API (пример на Python)
Ключевые особенности:
- Единая конечная точка:
/v3/openaiподдерживает формат API Chat Completions от OpenAI. - Гибкие настройки: Регулируйте температуру, top-p, штрафы и другие параметры для получения результатов, адаптированных под ваши задачи.
- Потоковая передача и пакетная обработка: Выбирайте предпочтительный режим получения ответов.
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.

Попробуйте Minimax M2.1 прямо сейчас!
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Вариант 2: Многоагентные рабочие процессы с SDK OpenAI Agents
Создавайте продвинутые многоагентные системы, интегрируя Novita AI с OpenAI Agents SDK:
- Подключи и работай: Используйте LLM от Novita AI в любом рабочем процессе OpenAI Agents.
- Поддержка передачи задач, маршрутизации и использования инструментов: Создавайте агентов, которые могут делегировать задачи, сортировать их или запускать функции, все на основе моделей Novita AI.
- Интеграция с Python: Просто укажите SDK конечную точку Novita (
https://api.novita.ai/v3/openai) и используйте ваш API-ключ.
Вариант 3:Подключите API GLM 4.7 Flash на сторонних платформах
- Hugging Face: Используйте MInimax M2.1 в Spaces, конвейерах или с библиотекой Transformers через конечные точки Novita AI.
- Фреймворки для агентов и оркестрации: Легко подключайте Novita AI к партнерским платформам, таким как Continue, AnythingLLM,LangChain, Dify и Langflow с помощью официальных коннекторов и пошаговых руководств по интеграции.
- Совместимый с OpenAI API: Наслаждайтесь простой миграцией и интеграцией с такими инструментами, как Cline и Cursor, разработанными по стандарту API OpenAI.
Кроме того, согласно рекомендациям с Reddit, использование Minimax M2.1 вместе с GLM 4.7 дает особенно хорошие результаты. Novita AI также предоставляет API для GLM 4.7, и вы можете нажать кнопку ниже, чтобы ознакомиться с ним.
Попробуйте API разнообразных моделей прямо сейчас!
Minimax M2.1 предлагает редкое сочетание масштабируемого контекста, эффективности MoE и скорости цикла агента, что делает его выбором производственного уровня для непрерывного кодирования и многоагентных систем. Он смещает оптимизацию с пиковой интеллектуальной производительности на реальную пропускную способность разработчиков.
Почему Minimax M2.1 подходит для кодирования с длинным контекстом?
Minimax M2.1 поддерживает контекстное окно в 204 800 токенов, что позволяет выполнять рассуждения на уровне всего репозитория и рефакторинг нескольких файлов за один проход.
Minimax M2.1 лучше Claude для агентов кодирования?
Для непрерывной разработки и циклов работы агентов Minimax M2.1 делает акцент на более быстрой итерации и отзывчивости в стиле IDE по сравнению с Claude.
Какой самый экономически эффективный способ использования Minimax M2.1?
Использование Minimax M2.1 через совместимый с OpenAI API от Novita AI или режим Spot GPU обеспечивает значительно более низкие операционные затраты для производственных рабочих нагрузок.
Novita AI — это облачная AI-платформа, которая предлагает разработчикам простой способ развертывания AI-моделей с помощью нашего простого API, а также доступное и надежное облако GPU для построения и масштабирования решений.



