

開発者は現在、実際のコーディングやエージェントシステムに適したLLMを選ぶ際に、スピード、コスト、能力のバランスを取るのに苦労しています。この記事では、Minimax M2.1 がこれらの課題をどのように解決するのか、アーキテクチャ、ベンチマーク、ハードウェア要件、デプロイ方法を分析し、チームが高頻度な開発ワークフローに最適なモデルを選択・統合できるようにします。
Minimax M2.1 のアーキテクチャ
| 仕様 | 値 |
|---|---|
| モデルID | MiniMaxAI/MiniMax-M2.1 |
| 総パラメータ数 | 230B |
| アクティブパラメータ数 | 10B (MoE) |
| コンテキストウィンドウ | 204,800 トークン |
| 最大出力 | 131,072 トークン |
| 精度 | FP8 |
| ライセンス | 修正MITライセンス |
| 重み | https://huggingface.co/MiniMaxAI/MiniMax-M2.1 |
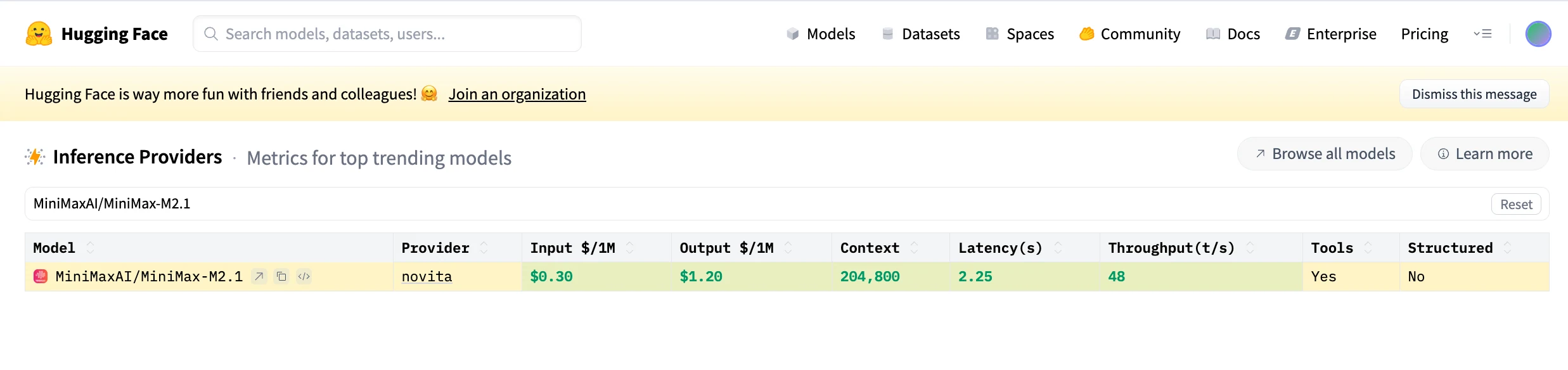
Minimax M2.1 のプログラミングエージェント能力
一般的な推論と会話の一貫性に優れるClaudeと比較して、MiniMax M2.1はエンジニアリングの完全性を重視しています。エージェントループの高速化、マルチ言語オーケストレーションの強化、実際のIDEスタイルのワークフローとの整合性が高く、継続的なコーディング、モバイル開発、長時間稼働するエージェントシステムに適しています。
- マルチ言語対応
Rust、Java、Go、C++、Kotlin、Objective-C、TypeScript、JavaScriptにおいて業界トップクラスの性能を発揮し、システムからアプリケーションまでスタック全体をカバーします。
| ベンチマーク | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (思考) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 74.0 | 69.4 | 77.2 | 80.9 | 78.0 | 80.0 | 73.1 |
| Multi-SWE-bench | 49.4 | 36.2 | 44.3 | 50.0 | 42.7 | x | 37.4 |
| SWE-bench Multilingual | 72.5 | 56.5 | 68 | 77.5 | 65.0 | 72.0 | 70.2 |
| Terminal-bench 2.0 | 47.9 | 30.0 | 50.0 | 57.8 | 54.2 | 54.0 | 46.4 |
- Webおよびアプリ開発
ネイティブのAndroidおよびiOSサポートが充実しており、複雑なインタラクション、3Dシミュレーション、高品質な可視化において高度な能力を発揮します。
| ベンチマーク | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (思考) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified (Droid) | 71.3 | 68.1 | 72.3 | 75.2 | x | x | 67.0 |
| SWE-bench Verified (mini-swe-agent) | 67.0 | 61.0 | 70.6 | 74.4 | 71.8 | 74.2 | 60.0 |
| SWT-bench | 69.3 | 32.8 | 69.5 | 80.2 | 79.7 | 80.7 | 62.0 |
| SWE-Perf | 3.1 | 1.4 | 3.0 | 4.7 | 6.5 | 3.6 | 0.9 |
| SWE-Review | 8.9 | 3.4 | 10.5 | 16.2 | x | x | 6.4 |
| OctoCodingbench | 26.1 | 13.3 | 22.8 | 36.2 | 22.9 | x | 26.0 |
一例:
Minimax M2.1 の高頻度エージェント能力
- オフィスグレードの推論
インターリーブドシンキングと複合命令実行により、多目的な実世界のワークフローを確実に処理できます。
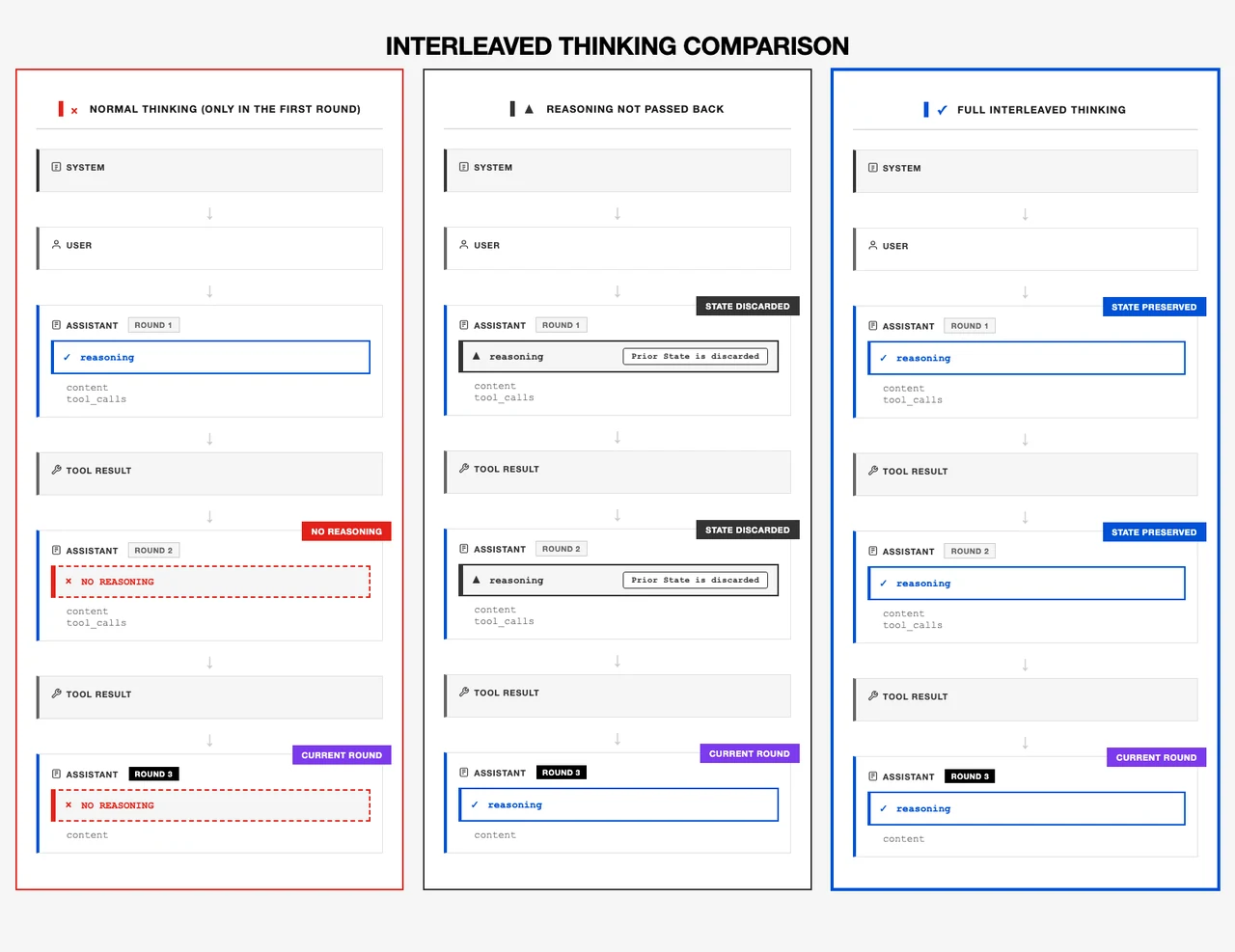
出典: Minimax
- 高効率
応答が短く、トークン使用量が少なく、インタラクションが高速で、継続的なコーディングや長時間のタスクに最適化されています。
一例:
出典: Minimax
Minimax M2.1 のハードウェア要件とローカルでの使用方法
大多数のコーディングおよびエージェントワークロードでは、80~96 GBクラスのGPU4枚で200Kコンテキストウィンドウを快適に処理できます。8GPU構成は、数百万トークンの拡張コンテキスト領域で運用する場合にのみ必要です。
| 構成 | 最大コンテキスト | ユースケース |
|---|---|---|
| 4× A100 または A800 (80 GB) | 400K トークン | 標準デプロイ |
| 4× H200 または H20 (96 GB+) | 400K トークン | 標準デプロイ |
| 8× H200 (141 GB) | 3M トークン | 拡張コンテキストワークロード |
Novitaは最安のオンデマンドH100価格($1.45/時)を提供しており、同じGPU性能の他社より最大30%安くなっています。
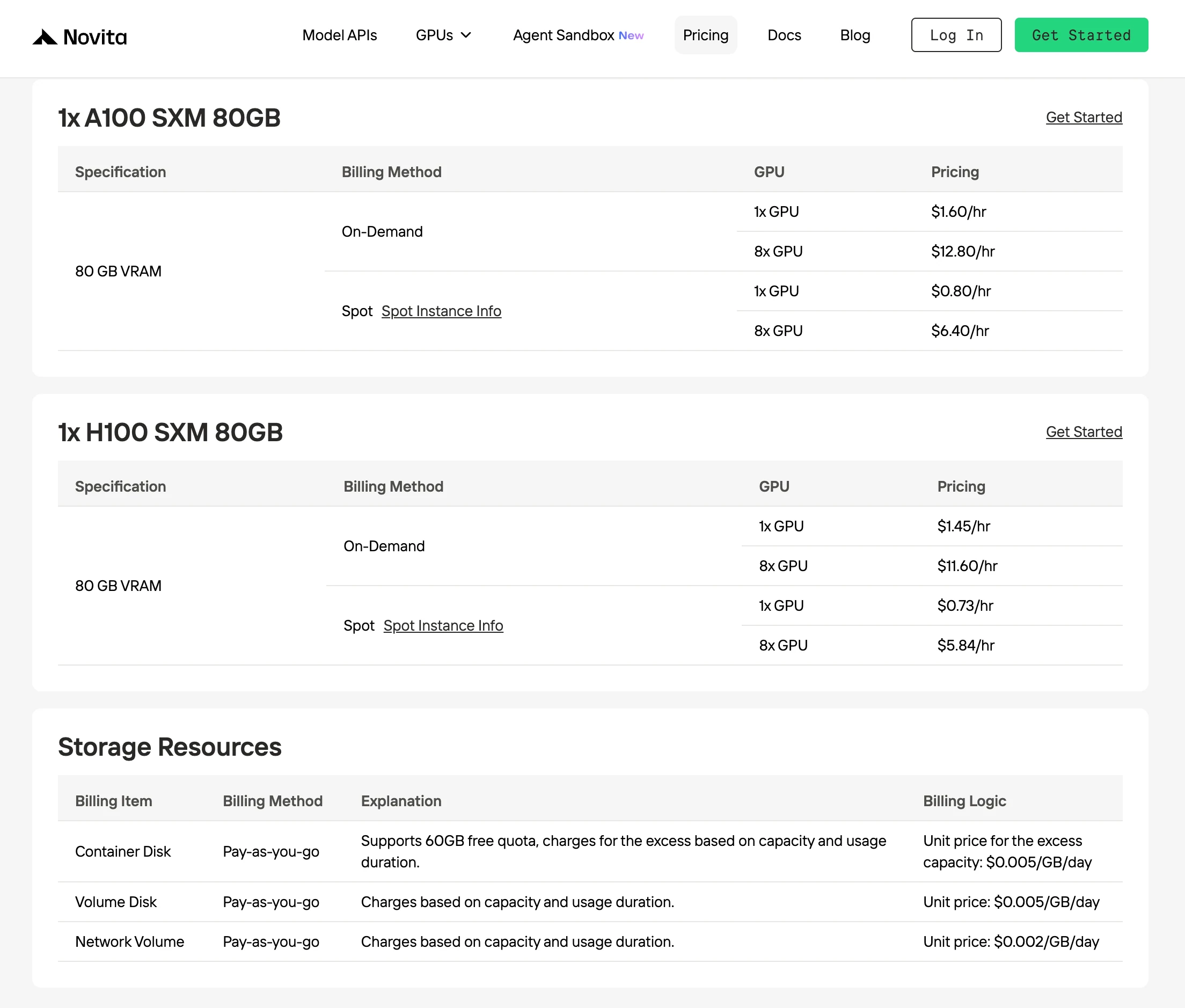
Novita AIのSpotmodeは、プラットフォームの未使用またはアイドル状態のGPU容量を活用するコスト最適化されたGPUレンタルオプションです。専用ハードウェアを予約して継続使用を保証するオンデマンドインスタンスとは異なり、Spotインスタンスは中断可能であり、通常40〜60%安い価格で提供されます。
この価格設定モデルは、Novitaがアイドル状態のGPUを空きのままにせず、短期利用者に動的に再割り当てすることで機能します。これによりプラットフォームのインフラストラクチャ利用率全体が向上し、開発者は柔軟なワークロードに対してはるかに低い計算コストの恩恵を受けられます。
お得な価格でMinimax M2.1を使うには?
Novita AIの統一REST APIを使用して、Minimax M2.1 Flashをアプリケーション、ワークフロー、チャットボットにシームレスに接続できます。モデルの重みやインフラを管理する必要はありません。Novita AIは多言語SDK(Python、Node.js、cURLなど)と、パワーユーザー向けの高度なパラメータ制御を提供します。
オプション1: 直接API統合(Python例)
主な機能:
- 統一エンドポイント:
/v3/openaiはOpenAIのChat Completions API形式をサポート。 - 柔軟な制御: temperature、top-p、ペナルティなどを調整して結果をカスタマイズ。
- ストリーミングとバッチ処理: 好みの応答モードを選択可能。
ステップ1: ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリボタンをクリックします。

ステップ2: モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。

ステップ3: 無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
ステップ4: APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに移動し、画像のようにAPIキーをコピーします。

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "あなたは役立つアシスタントです。"},
{"role": "user", "content": "こんにちは、お元気ですか?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
オプション2: OpenAI Agents SDKとのマルチエージェントワークフロー
Novita AIをOpenAI Agents SDKと統合して、高度なマルチエージェントシステムを構築します:
- プラグアンドプレイ: Novita AIのLLMをあらゆるOpenAI Agentsワークフローで使用可能。
- ハンドオフ、ルーティング、ツール使用をサポート: 委任、トリアージ、関数実行を行うエージェントを設計可能。すべてNovita AIのモデルを活用。
- Python統合: SDKをNovitaのエンドポイント(
https://api.novita.ai/v3/openai)に向けてAPIキーを使用するだけ。
オプション3: サードパーティプラットフォームでGLM 4.7 Flash APIに接続
- Hugging Face: Novita AIエンドポイント経由で、Spaces、パイプライン、またはTransformersライブラリと共にMinimax M2.1を使用。
- エージェント&オーケストレーションフレームワーク: Continue、AnythingLLM、LangChain、Dify、Langflowなどのパートナープラットフォームと、公式コネクタおよびステップバイステップの統合ガイドを通じて簡単に接続。
- OpenAI互換API: ClineやCursorなど、OpenAI API標準向けに設計されたツールとのシームレスな移行と統合。
さらに、Redditの推奨に基づくと、Minimax M2.1をGLM 4.7と組み合わせて使用すると特に効果的です。Novita AIはGLM 4.7のAPIも提供しており、下のボタンをクリックして探索できます。
Minimax M2.1は、フロンティア級のコンテキスト、MoE効率、エージェントループの高速性という希有な組み合わせを提供し、継続的なコーディングやマルチエージェントシステムにおいてプロダクショングレードの選択肢となります。ピーク時の知能から、実際の開発者スループットへと最適化の焦点を移します。
Minimax M2.1が長いコンテキストのコーディングに適している理由は?
Minimax M2.1は204,800トークンのコンテキストウィンドウをサポートしており、一回のパスでリポジトリ全体の推論や複数ファイルのリファクタリングが可能です。
Minimax M2.1はコーディングエージェントにおいてClaudeより優れていますか?
継続的な開発とエージェントループにおいて、Minimax M2.1はClaudeと比較して、より高速なイテレーションとIDEスタイルの応答性を重視しています。
Minimax M2.1を最もコスト効率よく使用する方法は?
Novita AIのOpenAI互換APIまたはSpot GPUモードを介してMinimax M2.1を使用すると、本番ワークロードの運用コストが大幅に削減されます。
Novita AI は、シンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃な価格で信頼性の高いGPUクラウドも提供しています。開発者は構築とスケーリングにこれを活用できます。



