

当今开发者在为实际编码和智能体系统选择大语言模型时,常常难以平衡速度、成本与能力。本文通过分析 Minimax M2.1 的架构、基准测试、硬件配置及部署路径,阐明它如何解决这些痛点,帮助团队选择并集成最适合高频开发工作流的实用模型。
Minimax M2.1 架构
| 规格 | 值 |
|---|---|
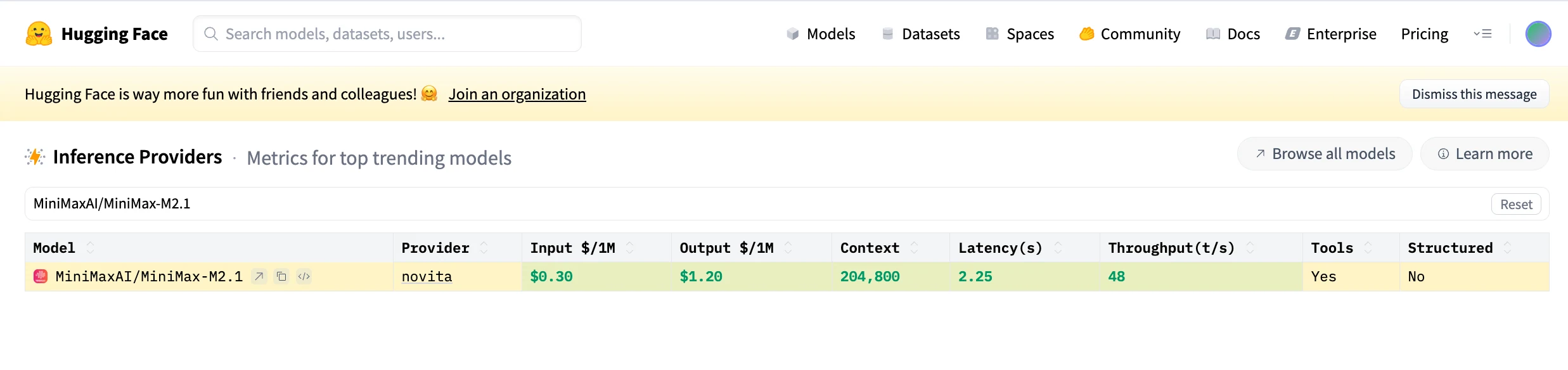
| 模型 ID | MiniMaxAI/MiniMax-M2.1 |
| 总参数量 | 230B |
| 激活参数量 | 10B(MoE) |
| 上下文窗口 | 204,800 tokens |
| 最大输出 | 131,072 tokens |
| 精度 | FP8 |
| 许可证 | 修改版 MIT |
| 权重 | https://huggingface.co/MiniMaxAI/MiniMax-M2.1 |
Minimax M2.1 的编程智能体能力
与在通用推理和对话连贯性方面表现出色的 Claude 相比,MiniMax M2.1 更强调工程完整性:更快的智能体循环行为、更强的多语言编排能力,以及与真实 IDE 风格工作流更好的对齐,使其更适合持续编码、移动开发和长时间运行的智能体系统。
- 多语言精通
在 Rust、Java、Go、C++、Kotlin、Objective-C、TypeScript 和 JavaScript 上均表现出行业领先的性能,覆盖从系统编程到应用开发的完整技术栈。
| 基准测试 | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2(推理) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 74.0 | 69.4 | 77.2 | 80.9 | 78.0 | 80.0 | 73.1 |
| Multi-SWE-bench | 49.4 | 36.2 | 44.3 | 50.0 | 42.7 | x | 37.4 |
| SWE-bench Multilingual | 72.5 | 56.5 | 68 | 77.5 | 65.0 | 72.0 | 70.2 |
| Terminal-bench 2.0 | 47.9 | 30.0 | 50.0 | 57.8 | 54.2 | 54.0 | 46.4 |
- Web 与移动应用开发
原生支持 Android 和 iOS,在复杂交互、3D 模拟和高质量可视化方面具有先进能力。
| 基准测试 | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2(推理) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified (Droid) | 71.3 | 68.1 | 72.3 | 75.2 | x | x | 67.0 |
| SWE-bench Verified (mini-swe-agent) | 67.0 | 61.0 | 70.6 | 74.4 | 71.8 | 74.2 | 60.0 |
| SWT-bench | 69.3 | 32.8 | 69.5 | 80.2 | 79.7 | 80.7 | 62.0 |
| SWE-Perf | 3.1 | 1.4 | 3.0 | 4.7 | 6.5 | 3.6 | 0.9 |
| SWE-Review | 8.9 | 3.4 | 10.5 | 16.2 | x | x | 6.4 |
| OctoCodingbench | 26.1 | 13.3 | 22.8 | 36.2 | 22.9 | x | 26.0 |
示例:
Minimax M2.1 的高频智能体能力
- 办公级推理
交错思考与复合指令执行,能够可靠处理多目标、真实世界的工作流。
来源:Minimax
- 更高的效率
更短的响应、更低的 token 消耗和更快的交互,针对持续编码和长时间运行的任务进行了优化。
示例:
来源:Minimax
Minimax M2.1 的硬件配置与本地使用方法
对于绝大多数编码和智能体工作负载,四块 80–96 GB 级 GPU 即可轻松处理 200K 的上下文窗口。只有在需要运行数百万 token 的扩展上下文时,才需要八 GPU 配置。
| 配置 | 最大上下文 | 使用场景 |
|---|---|---|
| 4× A100 或 A800 (80 GB) | 400K tokens | 标准部署 |
| 4× H200 或 H20 (96 GB+) | 400K tokens | 标准部署 |
| 8× H200 (141 GB) | 3M tokens | 扩展上下文工作负载 |
Novita 提供最低的按需 H100 价格,仅 $1.45/小时,比同等 GPU 性能的其他提供商便宜 30%。
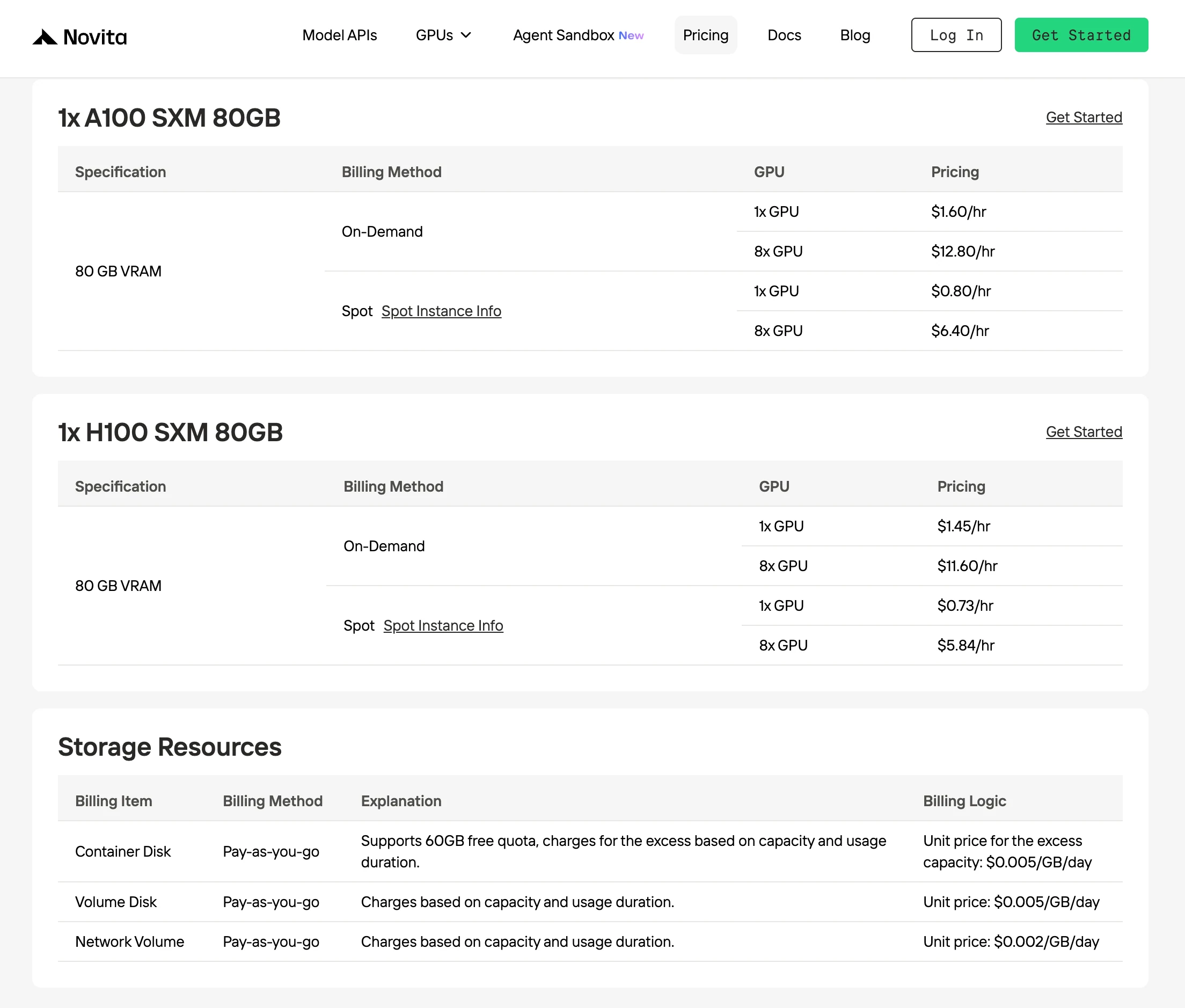
Novita AI 的 Spotmode 是一种成本优化的 GPU 租赁选项,利用平台未使用或闲置的 GPU 容量。与预留专用硬件以保证持续使用的按需实例不同,Spot 实例是可中断的——以显著更低的价格提供,通常便宜 40–60%。
这种定价模型之所以有效,是因为 Novita 将闲置的 GPU 动态分配给短期用户,而不是让它们闲置。这样一来,平台提高了整体基础设施的利用效率,同时开发者也因灵活工作负载获得了更低的计算成本。
如何以优惠价格使用 Minimax M2.1?
使用 Novita AI 的统一 REST API,无缝地将 Minimax M2.1 Flash 集成到您的应用程序、工作流或聊天机器人中——无需管理模型权重或基础设施。Novita AI 提供多语言 SDK(Python、Node.js、cURL 等)以及面向高级用户的精细参数控制。
选项 1:直接 API 集成(Python 示例)
主要特点:
- 统一端点:
/v3/openai支持 OpenAI 的 Chat Completions API 格式。 - 灵活控制: 调整 temperature、top-p、惩罚等参数,以获得定制化结果。
- 流式与批处理: 选择您偏好的响应模式。
步骤 1:登录并访问模型库
登录您的账户,点击 模型库 按钮。

步骤 2:选择模型
浏览可用选项,选择适合您需求的模型。

步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。
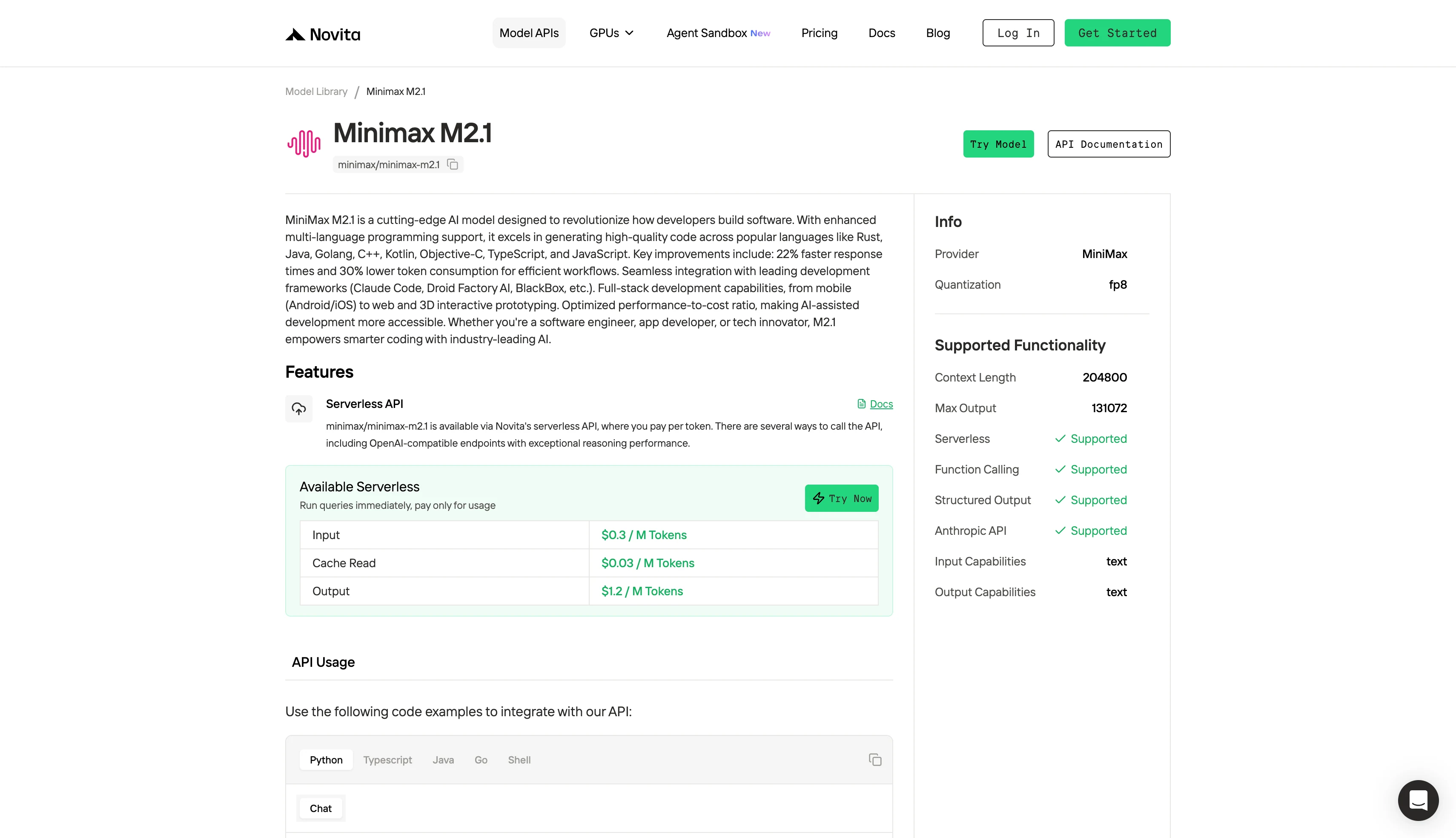
步骤 4:获取 API Key
为了通过 API 进行身份验证,我们将为您提供一个新的 API Key。进入“设置”页面,您可以复制 API Key,如下图所示。

from openai import OpenAI
client = OpenAI(
api_key="<您的 API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "你好,最近怎么样?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
选项 2:使用 OpenAI Agents SDK 构建多智能体工作流
通过将 Novita AI 与 OpenAI Agents SDK 集成,构建高级多智能体系统:
- 即插即用: 在任何 OpenAI Agents 工作流中使用 Novita AI 的 LLM。
- 支持移交、路由和工具使用: 设计能够委派、分类或运行函数的智能体,全部由 Novita AI 的模型提供支持。
- Python 集成: 只需将 SDK 指向 Novita 的端点(
https://api.novita.ai/v3/openai)并使用您的 API Key 即可。
选项 3:在第三方平台上连接 Minimax M2.1 Flash API
- Hugging Face:通过 Novita AI 端点,在 Spaces、pipeline 或 Transformers 库中使用 Minimax M2.1。
- 智能体与编排框架: 通过官方连接器和逐步集成指南,轻松将 Novita AI 与 Continue、AnythingLLM、LangChain、Dify 和 Langflow 等平台连接。
- OpenAI 兼容 API: 享受与 Cline 和 Cursor 等工具的无缝迁移与集成,这些工具专为 OpenAI API 标准设计。
此外,基于 Reddit 的推荐,将 Minimax M2.1 与 GLM 4.7 一起使用效果尤其出色。Novita AI 也提供 GLM 4.7 的 API,您可以点击下方按钮进行探索。
Minimax M2.1 提供了前卫规模的上下文、MoE 效率和智能体循环速度的罕见组合,使其成为持续编码和多智能体系统的生产级选择。它将优化重点从峰值智能转向真正的开发吞吐量。
为什么 Minimax M2.1 适合长上下文编码?
Minimax M2.1 支持 204,800 token 的上下文窗口,允许在单次执行中完成整个仓库的推理和多文件重构。
对于编码智能体,Minimax M2.1 比 Claude 更好吗?
对于持续开发和智能体循环,Minimax M2.1 相比 Claude 更强调快速迭代和类似 IDE 的响应性。
使用 Minimax M2.1 最具成本效益的方式是什么?
通过 Novita AI 的 OpenAI 兼容 API 或 Spot GPU 模式使用 Minimax M2.1,可以显著降低生产工作负载的运营成本。
Novita AI 是一个 AI 云平台,为开发者提供简单 API 便捷部署 AI 模型,同时也提供经济实惠且可靠的 GPU 云,用于构建和扩展 AI 应用。



