

Entwickler haben heute Schwierigkeiten, Geschwindigkeit, Kosten und Leistung bei der Auswahl eines LLM für reale Programmier- und Agentensysteme in Einklang zu bringen. Dieser Artikel erklärt, wie Minimax M2.1 diese Probleme löst, indem er seine Architektur, Benchmarks, Hardwareprofile und Bereitstellungspfade analysiert, sodass Teams das praktischste Modell für hochfrequente Entwicklungs-Workflows auswählen und integrieren können.
Architektur von Minimax M2.1
| Spezifikation | Wert |
|---|---|
| Modell-ID | MiniMaxAI/MiniMax-M2.1 |
| Gesamtparameter | 230B |
| Aktive Parameter | 10B (MoE) |
| Kontextfenster | 204.800 Token |
| Maximale Ausgabe | 131.072 Token |
| Präzision | FP8 |
| Lizenz | Modifizierte MIT-Lizenz |
| Gewichte | https://huggingface.co/MiniMaxAI/MiniMax-M2.1 |
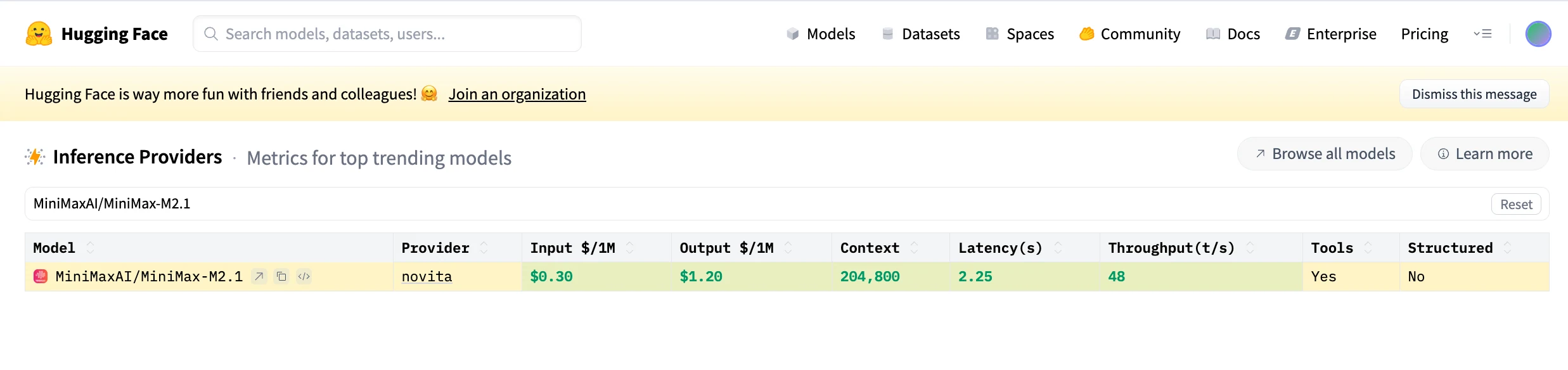
Programmieragenten-Fähigkeiten von Minimax M2.1
Im Vergleich zu Claude, das in allgemeiner Argumentation und konversationeller Kohärenz glänzt, legt MiniMax M2.1 den Schwerpunkt auf ingenieurtechnische Vollständigkeit: schnelleres Agent-Loop-Verhalten, stärkere Mehrsprachen-Orchestrierung und bessere Ausrichtung an echten IDE-Workflows, wodurch es sich besser für kontinuierliches Programmieren, mobile Entwicklung und langlaufende Agentensysteme eignet.
- Mehrsprachenbeherrschung
Branchenführende Leistung in Rust, Java, Go, C++, Kotlin, Objective-C, TypeScript und JavaScript, die den gesamten Stack von Systemen bis zu Anwendungen abdeckt.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 74.0 | 69.4 | 77.2 | 80.9 | 78.0 | 80.0 | 73.1 |
| Multi-SWE-bench | 49.4 | 36.2 | 44.3 | 50.0 | 42.7 | x | 37.4 |
| SWE-bench Multilingual | 72.5 | 56.5 | 68 | 77.5 | 65.0 | 72.0 | 70.2 |
| Terminal-bench 2.0 | 47.9 | 30.0 | 50.0 | 57.8 | 54.2 | 54.0 | 46.4 |
- Web- und App-Entwicklung
Starke native Android- und iOS-Unterstützung mit fortgeschrittenen Fähigkeiten in komplexen Interaktionen, 3D-Simulationen und hochwertiger Visualisierung.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (thinking) | DeepSeek V3.2 |
|---|---|---|---|---|---|---|---|
| SWE-bench Verified (Droid) | 71.3 | 68.1 | 72.3 | 75.2 | x | x | 67.0 |
| SWE-bench Verified (mini-swe-agent) | 67.0 | 61.0 | 70.6 | 74.4 | 71.8 | 74.2 | 60.0 |
| SWT-bench | 69.3 | 32.8 | 69.5 | 80.2 | 79.7 | 80.7 | 62.0 |
| SWE-Perf | 3.1 | 1.4 | 3.0 | 4.7 | 6.5 | 3.6 | 0.9 |
| SWE-Review | 8.9 | 3.4 | 10.5 | 16.2 | x | x | 6.4 |
| OctoCodingbench | 26.1 | 13.3 | 22.8 | 36.2 | 22.9 | x | 26.0 |
Beispiel:
Hochfrequenz-Agentenfähigkeiten von Minimax M2.1
- Bürotaugliche Argumentation
Interleaved Thinking und zusammengesetzte Befehlsausführung ermöglichen die zuverlässige Verarbeitung von multizieligen, realen Workflows.
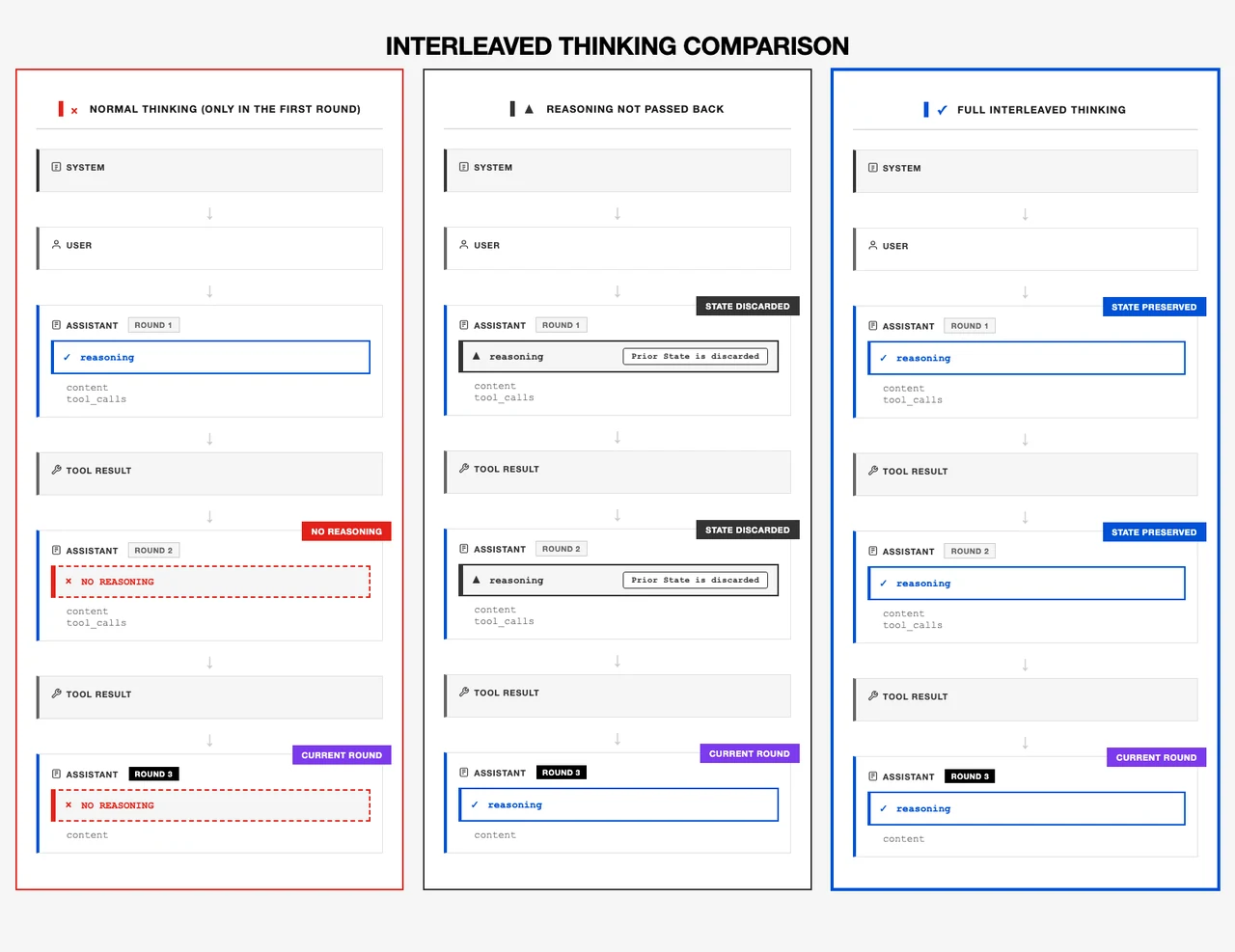
Von Minimax
- Höhere Effizienz
Kürzere Antworten, geringere Token-Nutzung und schnellere Interaktion, optimiert für kontinuierliches Programmieren und langlaufende Aufgaben.
Beispiel:
Von Mimimax
Hardware von Minimax M2.1 und wie man es lokal ausführt?
Für die überwiegende Mehrheit der Programmier- und Agenten-Workflows bewältigen vier GPUs der 80–96 GB-Klasse ein 200K-Kontextfenster problemlos. Die 8-GPU-Konfiguration ist nur bei Betrieb im erweiterten Kontextbereich mit mehreren Millionen Token erforderlich.
| Konfiguration | Maximaler Kontext | Anwendungsfall |
|---|---|---|
| 4× A100 oder A800 (80 GB) | 400K Token | Standardbereitstellungen |
| 4× H200 oder H20 (96 GB+) | 400K Token | Standardbereitstellungen |
| 8× H200 (141 GB) | 3M Token | Erweiterte Kontext-Workloads |
Novita bietet die niedrigsten On-Demand-H100-Preise von 1,45 $/Stunde, bis zu 30 % günstiger als andere Anbieter mit identischer GPU-Leistung.
Probieren Sie jetzt günstige GPUs aus!
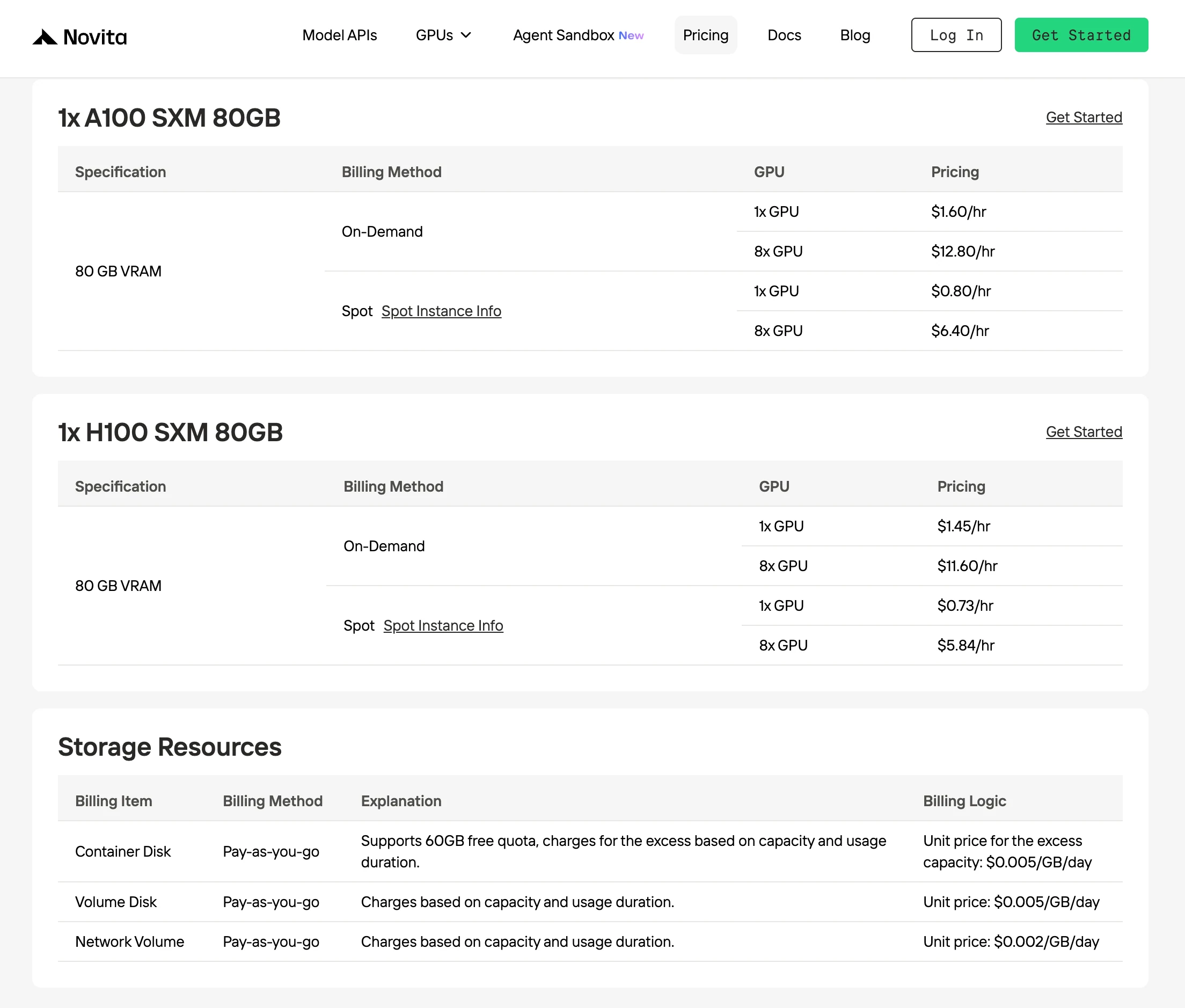
Der Spotmode von Novita AI ist eine kostenoptimierte GPU-Mietoption, die die ungenutzte oder Leerlauf-GPU-Kapazität der Plattform nutzt. Im Gegensatz zu On-Demand-Instanzen, die dedizierte Hardware für garantierte kontinuierliche Nutzung reservieren, sind Spot-Instanzen unterbrechbar und werden zu deutlich niedrigeren Preisen angeboten, typischerweise 40–60 % günstiger.
Dieses Preismodell funktioniert, weil Novita ungenutzte GPUs dynamisch an Kurzzeitnutzer neu zuweist, anstatt sie ungenutzt zu lassen. Dadurch verbessert die Plattform die Gesamteffizienz der Infrastrukturauslastung, während Entwickler von deutlich niedrigeren Rechenkosten für flexible Workflows profitieren.
Wie nutzt man Minimax M2.1 zu einem guten Preis?
Verbinden Sie Minimax M2.1 Falsh nahtlos mit Ihren Anwendungen, Workflows oder Chatbots über die einheitliche REST-API von Novita AI – ohne Modellgewichte oder Infrastruktur verwalten zu müssen. Novita AI bietet mehrsprachige SDKs (Python, Node.js, cURL und mehr) und erweiterte Parametersteuerungen für Power-User.
Option 1: Direkte API-Integration (Python-Beispiel)
Hauptmerkmale:
- Einheitlicher Endpunkt:
/v3/openaiunterstützt das Format der Chat-Completions-API von OpenAI. - Flexible Steuerung: Passen Sie temperature, top-p, penalties und weitere Parameter an, um maßgeschneiderte Ergebnisse zu erhalten.
- Streaming & Batch-Verarbeitung: Wählen Sie Ihren bevorzugten Antwortmodus.
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Loggen Sie sich in Ihrem Konto ein und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Probieren Sie Minimax M2.1 jetzt aus!
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells kennenzulernen.
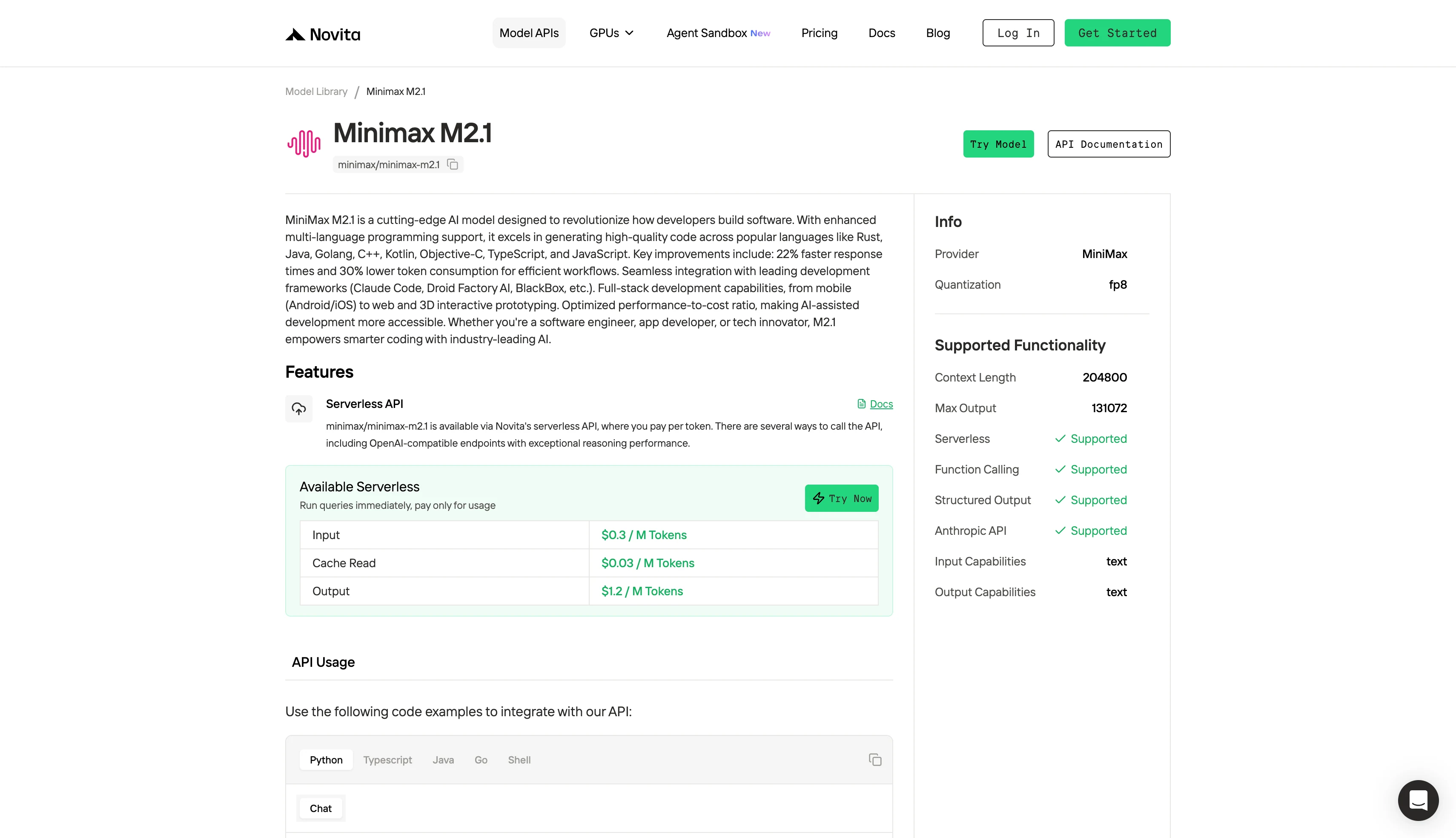
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Wenn Sie die Seite „Einstellungen“ aufrufen, können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2: Multi-Agenten-Workflows mit dem OpenAI Agents SDK
Erstellen Sie fortschrittliche Multi-Agenten-Systeme, indem Sie Novita AI mit dem OpenAI Agents SDK integrieren:
- Plug-and-Play: Nutzen Sie die LLMs von Novita AI in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwerfen Sie Agenten, die delegieren, triagieren oder Funktionen ausführen können, alle angetrieben von den Modellen von Novita AI.
- Python-Integration: Zeigen Sie das SDK einfach auf Novitas Endpunkt (
https://api.novita.ai/v3/openai) und verwenden Sie Ihren API-Schlüssel.
Option 3:Verbinden Sie die GLM 4.7 Flash API auf Drittanbieter-Plattformen
- Hugging Face: Nutzen Sie MInimax M2.1 in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
- Agenten- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM,LangChain, Dify und Langflow über offizielle Connectors und Schritt-für-Schritt-Integrationsanleitungen.
- OpenAI-kompatible API: Genießen Sie problemlose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI-API-Standard entwickelt wurden.
Zusätzlich funktioniert die Kombination von Minimax M2.1 mit GLM 4.7 laut Empfehlungen aus Reddit besonders gut. Novita AI bietet zudem eine API für GLM 4.7 an, die Sie über die Schaltfläche unten erkunden können.
Probieren Sie jetzt die API für diverse Modelle aus!
Minimax M2.1 bietet eine seltene Kombination aus kontextreichster Skalierung, MoE-Effizienz und Agent-Loop-Geschwindigkeit, was es zu einer produktionsreifen Wahl für kontinuierliches Programmieren und Multi-Agenten-Systeme macht. Es verlagert die Optimierung von Spitzenintelligenz auf den tatsächlichen Entwickler-Durchsatz.
Warum ist Minimax M2.1 für langkontextiges Programmieren geeignet? Minimax M2.1 unterstützt ein Kontextfenster von 204.800 Token, sodass ganzes Repository-übergreifende Argumentation und Multi-Datei-Refactorings in einem einzigen Durchlauf möglich sind.
Ist Minimax M2.1 für Programmieragenten besser als Claude? Für kontinuierliche Entwicklung und Agent-Loops legt Minimax M2.1 im Vergleich zu Claude den Schwerpunkt auf schnellere Iterationen und IDE-ähnliche Reaktionsfähigkeit.
Was ist die kosteneffizienteste Methode zur Nutzung von Minimax M2.1? Die Nutzung von Minimax M2.1 über die OpenAI-kompatible API von Novita AI oder den Spot-GPU-Modus führt zu deutlich niedrigeren Betriebskosten für Produktions-Workloads.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.



