

주요 하이라이트
고급 성능
Qwen 2-7B는 SwiGLU 활성화, attention QKV bias, 그룹 쿼리 어텐션(GQA)과 같은 고급 기능을 갖춘 transformer 기반 아키텍처로 구축되어 더 빠른 추론과 메모리 사용량 감소를 제공합니다. 최대 131,072 토큰 의 컨텍스트 길이를 지원하여 긴 컨텍스트 작업에 이상적입니다.
로컬에서 Qwen 2-7B에 액세스하는 방법
로컬 액세스는 고성능 GPU(예: NVIDIA RTX 4080 Super)가 필요하며 최소 15.4 GB VRAM 이 필요합니다.
API를 통해 Qwen 2-7B에 액세스하는 방법
Novita AI 와 같은 플랫폼은 간단한 설정을 제공하여 하드웨어 필요성을 없앱니다.
사용 추천 사항
로컬 액세스는 완전한 제어가 필요한 연구자에게 적합하며, API 액세스는 빠른 배포와 사용 편의성을 원하는 개발자와 비즈니스에 이상적입니다.
Qwen 2-7B는 성능에 최적화된 비용 효율적인 언어 모델로, 자연어 이해 및 코드 생성과 같은 애플리케이션에 이상적입니다.
Qwen 2 7B란 무엇인가?
Qwen 2 - 7B는 Qwen 시리즈의 최신 모델로, transformer 기반 아키텍처로 구축되었습니다. 이는 0.5에서 720억 파라미터 범위의 언어 모델 시리즈의 일부이며, Qwen 2-7B-Instruct는 미세 조정된 명령어 최적화 변형입니다.
주요 기능
- Transformer 아키텍처 : SwiGLU 활성화, attention QKV bias, 그룹 쿼리 어텐션을 포함합니다.
- 토크나이저 : 여러 자연어와 프로그래밍 코드를 처리할 수 있는 향상된 토크나이저.
- 학습 : 광범위한 데이터셋으로 사전 학습되었으며, 지도 미세 조정 및 직접 선호 최적화를 통해 정제됨.
- 컨텍스트 길이 : 긴 컨텍스트 작업을 위해 최대 131,072 토큰 지원.
- 언어 지원 : 영어와 중국어에 탁월하며, 추가로 다른 언어도 지원함.
벤치마크
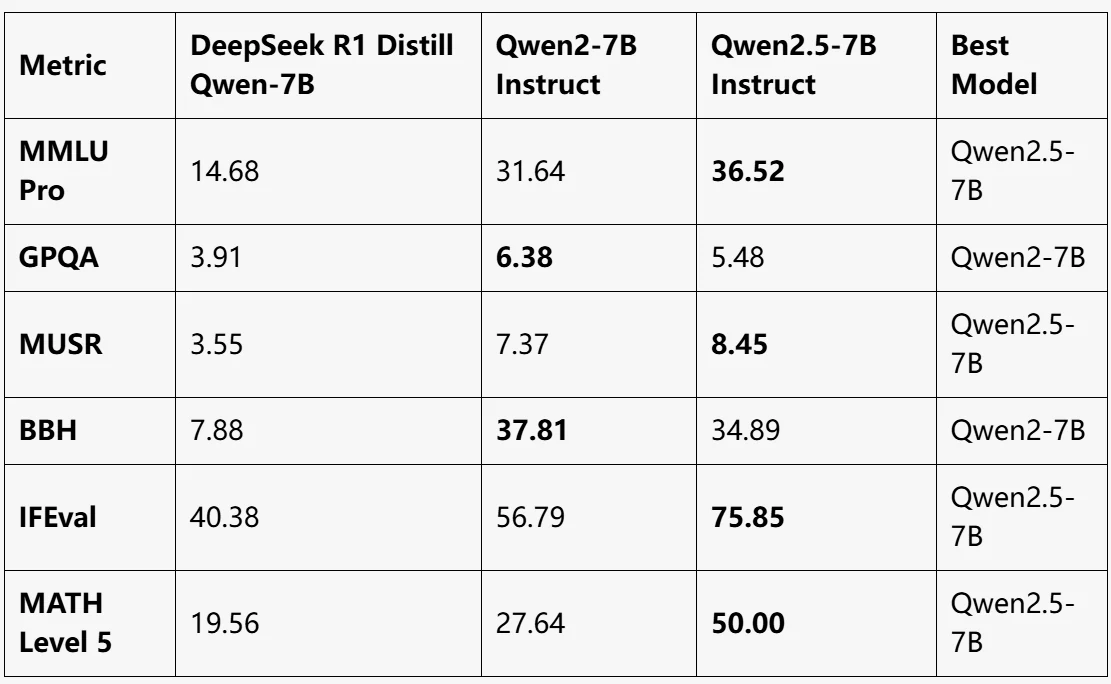
출처: LLM EXPLORER
Qwen2.5-7B Instruct:
- 전반적으로 가장 뛰어난 성능, MMLU Pro, MUSR, IFEval, MATH Level 5 에서 선두.
- 수학적 추론에서 상당한 개선 (MATH Level 5: 50).
Qwen2-7B Instruct:
- GPQA 및 BBH 에서 최고 성능.
- 균형 잡힌 모델이지만 다른 대부분의 지표에서 Qwen2.5-7B에 약간 뒤쳐짐.
DeepSeek R1 Distill Qwen-7B:
- 모든 벤치마크에서 가장 낮은 성능.
- 경량 작업에 적합하지만 복잡한 벤치마크에서 Qwen2 모델에 크게 뒤쳐짐.
다른 Qwen 모델과 비교
Qwen 2 시리즈는 다섯 가지 크기(Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, Qwen2-72B)의 기본 모델과 명령어 튜닝 모델을 포함합니다. 다음은 이러한 모델의 주요 정보 요약입니다.
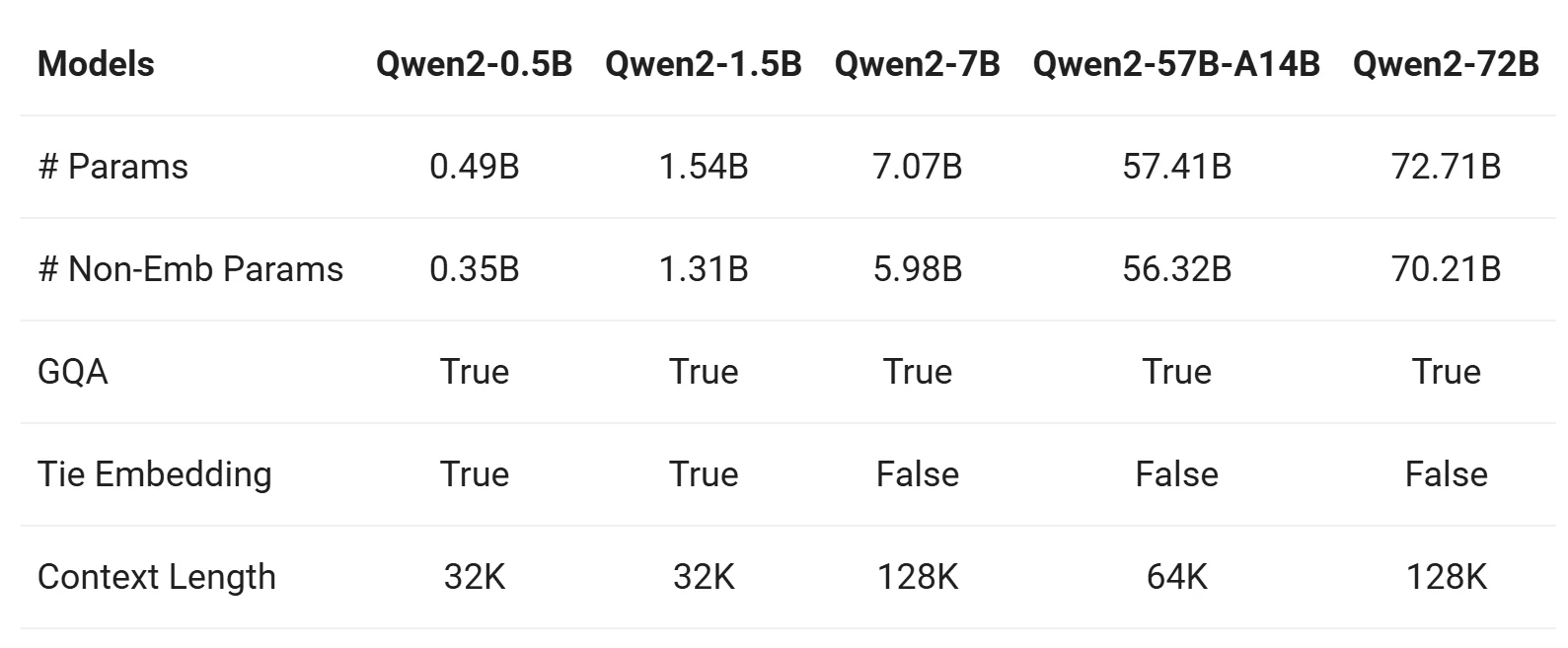
출처: Qwen
1. 그룹 쿼리 어텐션 (GQA)
- 모든 모델 (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B)이 GQA를 채택하여 다음을 제공합니다.
- 더 빠른 추론 속도.
- 메모리 사용량 감소.
- 이는 Qwen1.5와 비교하여 큰 개선으로, Qwen1.5에서는 대형 모델(32B 및 110B)만 GQA를 사용했습니다.
2. 컨텍스트 길이
- 기본 모델 (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B):
- 32K 토큰 컨텍스트 길이로 사전 학습됨.
- 혼란도(PPL) 평가에서 최대 128K 토큰까지 강력한 외삽 능력 입증.
- 명령어 튜닝 모델 (Qwen2-7B-Instruct, Qwen2-72B-Instruct):
- "바늘 찾기"와 같은 작업으로 평가됨.
- 긴 컨텍스트 작업에서 매우 뛰어난 성능을 보이며, 특히 YARN으로 강화할 때 최대 128K 토큰까지 확장 가능.
3. 다국어 기능
- 모든 모델 (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B):
- 영어와 중국어 외에 27개 언어를 추가로 포함하는 개선된 사전 학습 데이터셋의 혜택을 누림.
- 다국어 성능은 모델 크기에 따라 향상되며, 대형 모델 (Qwen2-57B, Qwen2-72B)이 더 복잡한 다국어 작업에서 탁월함.
더 자세한 파라미터 비교를 원하신다면 Qwen 2.5 72B 등 다른 모델과의 비교를 확인하세요: Qwen 2.5 72b vs Llama 3.3 70b: 어떤 모델이 당신의 필요에 맞나요? ; Qwen 2.5 vs Llama 3.2 90B: 코딩 및 이미지 추론 능력 비교 분석.
로컬에서 Qwen 2 7B에 액세스하는 방법
GPU 권장 사항
| 모델 | VRAM 용량 | 메모리 유형 | 상대적 성능 | 가격대 |
|---|---|---|---|---|
| NVIDIA RTX 4080 Super | 16 GB | GDDR6X | 높음 | ⭐⭐⭐⭐⭐ (고급형) |
| AMD RX 7900 XTX | 24 GB | GDDR6 | 높음 | ⭐⭐⭐⭐⭐ (고급형) |
| NVIDIA RTX 4070 Ti Super | 16 GB | GDDR6X | 중간-높음 | ⭐⭐⭐⭐ (중상급) |
| AMD RX 7600 XT | 16 GB | GDDR6 | 중간 | ⭐⭐⭐ (중급) |
| NVIDIA RTX 4060 Ti (16GB) | 16 GB | GDDR6 | 중간 | ⭐⭐⭐ (중급) |
빠른 시작
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Novita AI를 통해 Qwen 2 7B에 액세스하는 방법
단계별 가이드
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있는 AI 클라우드 플랫폼으로, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드도 제공합니다.
1단계: 로그인 및 모델 라이브러리 액세스
계정에 로그인하고 Model Library 버튼을 클릭하세요.

2단계: 모델 선택
사용 가능한 옵션을 탐색하고 필요에 맞는 모델을 선택하세요.
3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하기 위해 무료 체험을 시작하세요.
4단계: API 키 받기
API 인증을 위해 새 API 키를 제공합니다. “Settings” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치
사용 중인 프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치하세요.

설치 후, 필요한 라이브러리를 개발 환경에 가져오세요. API 키로 API를 초기화하여 Novita AI LLM과 상호 작용을 시작하세요. 다음은 Python 사용자를 위한 채팅 완료 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen-2-7b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
가입 시 Novita AI는 시작에 도움이 되는 $0.5 크레딧을 제공합니다!
무료 크레딧이 소진되면 비용을 지불하여 계속 사용할 수 있습니다.
어떤 방법이 당신에게 적합한가요?
로컬 vs API 액세스 비교
로컬 액세스
장점:
- 모델 및 구성에 대한 더 많은 제어 제공.
- YARN 을 활용하여 모델 길이 외삽을 개선함으로써 긴 텍스트 처리에 적합.
- 반복 비용 없음.
단점:
- 15.4GB VRAM 을 포함한 상당한 하드웨어 자원 필요.
- 복잡한 설정 및 구성.
API 액세스 (예: Novita AI)
장점:
- 단계별 가이드 제공으로 설정 및 사용이 쉬움.
- 로컬 하드웨어 자원 불필요.
단점:
- 인터넷 연결 필요.
- 토큰당 비용 발생: 입력 토큰 100만 개당 $0.054 , 출력 토큰 100만 개당 $0.054 .
- 모델 사용자 정의 및 구성에 대한 제한적 제어.
다양한 사용자 그룹에 대한 추천
- 연구자: 일반적으로 실험의 유연성과 제어를 위해 로컬 액세스 선호.
- 개발자:
- API 액세스는 애플리케이션 구축 및 빠른 프로토타이핑에 적합.
- 로컬 액세스는 미세 조정 및 사용자 정의 워크플로에 더 적합.
- 비즈니스: API 액세스는 높은 초기 비용 없이 서비스에 빠르게 통합하는 데 유용. 로컬 배포는 일관된 요구 사항과 인프라 투자 능력이 있는 팀에 적합.
- 소규모 팀/개인: 일반적으로 초기 비용이 낮아 API 액세스가 더 실용적.
- 기술적 지식이 부족한 사용자: 깊은 기술 지식이 필요 없어 API 액세스가 더 바람직.
Qwen 2 - 7B 는 다양한 애플리케이션을 위해 설계된 다재다능하고 강력한 모델입니다. 로컬 및 API 액세스를 모두 지원하여 사용자가 특정 요구 사항, 가용 자원 및 기술 전문성에 가장 잘 맞는 옵션을 선택할 수 있습니다.
자주 묻는 질문
Qwen2 모델의 주요 아키텍처 특징은 무엇인가요?
Qwen2 모델은 SwiGLU 활성화, attention QKV bias, 그룹 쿼리 어텐션(GQA)과 같은 기능을 갖춘 transformer 기반 아키텍처를 사용합니다.
Qwen2 모델이 지원하는 컨텍스트 길이는 얼마인가요?
기본 언어 모델은 32K 토큰 컨텍스트 길이로 사전 학습되었으며, 일부 모델은 PPL 평가에서 최대 128K 토큰까지 외삽 능력을 보여줍니다.
Novita AI 는 당신의 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 비용 효율적인 도구입니다. 인프라를 없애고 무료로 시작하여 AI 비전을 현실로 만드세요.



