

Ключевые моменты
Продвинутая производительность
Qwen 2‑7B построена на архитектуре на основе трансформеров с расширенными функциями, такими как активация SwiGLU, смещение QKV в механизме внимания и групповое запросное внимание (GQA), что обеспечивает более быстрый вывод и снижение использования памяти. Она поддерживает длину контекста до 131 072 токенов, что делает её идеальной для задач с длинным контекстом.
Как получить доступ к Qwen 2‑7B локально
Локальный доступ требует высокопроизводительных GPU (например, NVIDIA RTX 4080 Super) с минимум 15,4 ГБ видеопамяти.
Как получить доступ к Qwen 2‑7B через API
Платформы, такие как Novita AI, предлагают простую настройку, устраняя необходимость в собственном оборудовании.
Рекомендации по использованию
Локальный доступ подходит исследователям, которым нужен полный контроль, а доступ через API — разработчикам и компаниям, стремящимся к быстрому развёртыванию и простоте использования.
Qwen 2‑7B — это экономичная языковая модель, оптимизированная для производительности, идеальная для таких приложений, как понимание естественного языка и генерация кода.
Что такое Qwen 2 7B?
Qwen 2‑7B — это современная модель серии Qwen, построенная на архитектуре трансформеров. Она входит в серию языковых моделей от 0,5 до 72 миллиардов параметров, причём Qwen 2‑7B‑Instruct является точно настроенным вариантом, оптимизированным для инструкций.
Ключевые особенности
- Архитектура трансформеров: включает активацию SwiGLU, смещение QKV в внимании и групповое запросное внимание.
- Токенизатор: улучшенный токенизатор, способный обрабатывать множество естественных языков и программный код.
- Обучение: предварительное обучение на обширных наборах данных и последующая доработка с помощью контролируемой точной настройки и прямой оптимизации предпочтений.
- Длина контекста: поддержка до 131 072 токенов для задач с длинным контекстом.
- Поддержка языков: отличные результаты на английском и китайском, с дополнительной поддержкой других языков.
Бенчмарк
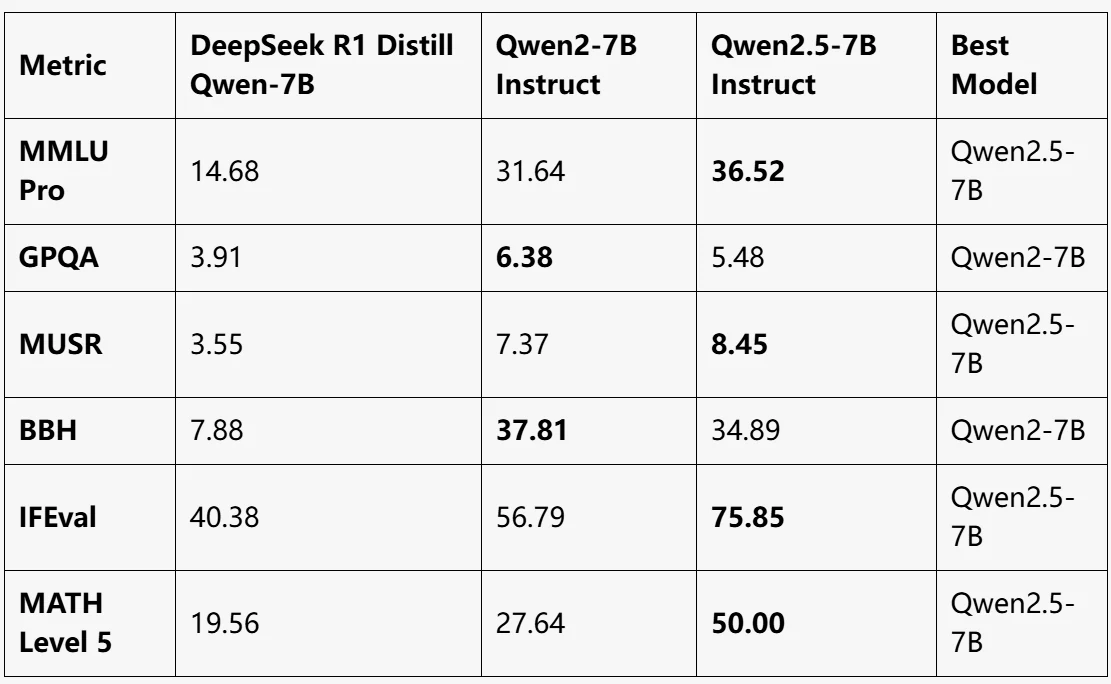
источник: LLM EXPLORER
Qwen2.5-7B Instruct:
- Лучшая общая производительность, лидирует в MMLU Pro, MUSR, IFEval и MATH Level 5.
- Значительное улучшение математических рассуждений (MATH Level 5: 50).
Qwen2-7B Instruct:
- Лучшая производительность в GPQA и BBH.
- Сбалансированная модель, но немного уступает Qwen2.5-7B по большинству других показателей.
DeepSeek R1 Distill Qwen-7B:
- Самая низкая производительность во всех бенчмарках.
- Подходит для лёгких задач, но сильно отстаёт от моделей Qwen2 в сложных тестах.
Сравнение с другими моделями Qwen
Серия Qwen 2 включает базовые и доработанные под инструкции модели пяти размеров: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B и Qwen2-72B. Ниже представлена сводка ключевой информации об этих моделях:
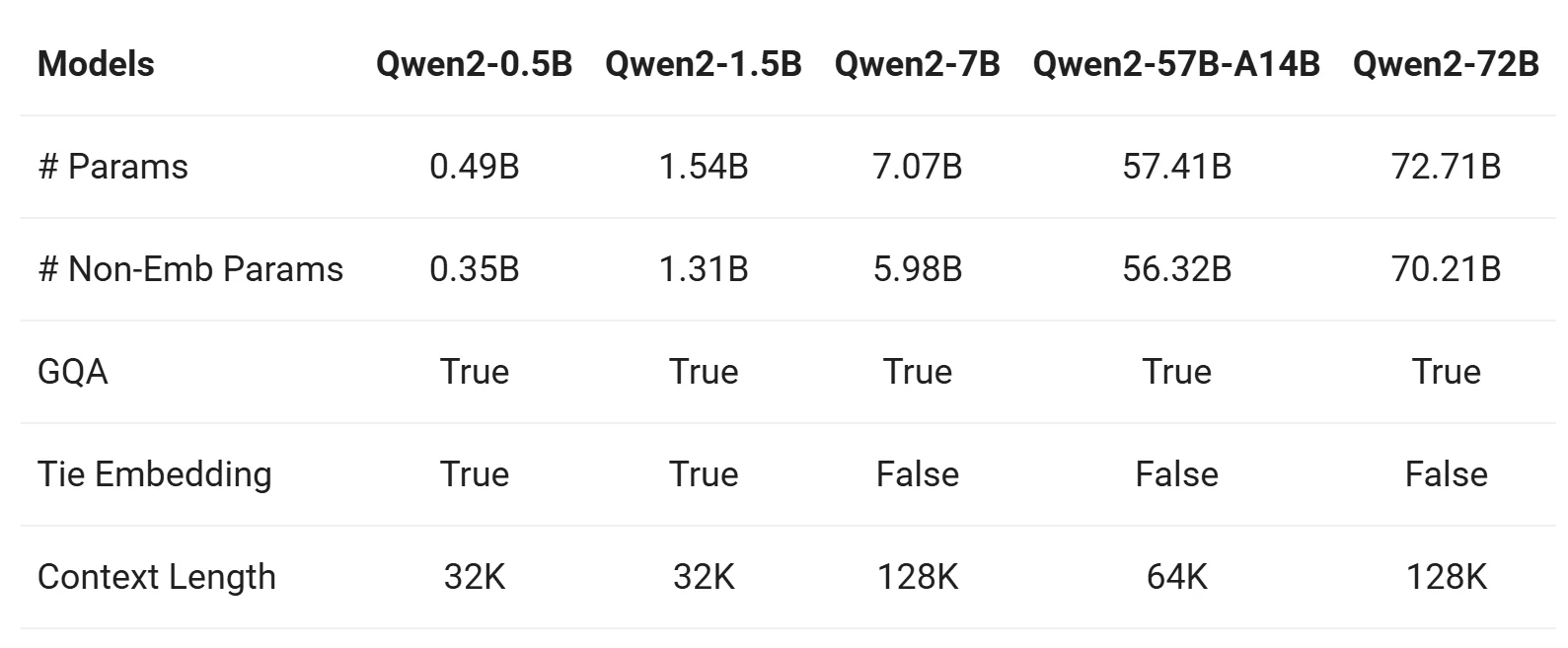
Из Qwen
1. Групповое запросное внимание (GQA)
- Все модели (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B) используют GQA, что обеспечивает:
- Более высокую скорость вывода.
- Снижение использования памяти.
- Это значительное улучшение по сравнению с Qwen1.5, где GQA использовали только большие модели (32B и 110B).
2. Длина контекста
- Базовые модели (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B):
- Предварительно обучены с длиной контекста 32K токенов.
- Демонстрируют сильную способность к экстраполяции до 128K токенов на основе оценки перплексии (PPL).
- Инструкционные модели (Qwen2-7B-Instruct, Qwen2-72B-Instruct):
- Оцениваются с помощью задач типа «Иголка в стоге сена».
- Превосходно справляются с задачами на длинный контекст, их возможности простираются до 128K токенов, особенно при дополнении YARN.
3. Многоязычные возможности
- Все модели (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B):
- Выигрывают от улучшенных наборов данных предобучения, которые включают 27 дополнительных языков помимо английского и китайского.
- Многоязычная производительность улучшается с размером модели, причём большие модели (Qwen2-57B, Qwen2-72B) преуспевают в более сложных многоязычных задачах.
Если вы хотите увидеть более детальное сравнение параметров с другими моделями, такими как Qwen 2.5 72B, ознакомьтесь с этой статьёй: Qwen 2.5 72b vs Llama 3.3 70b: Which Model Suits Your Needs? ; Qwen 2.5 vs Llama 3.2 90B: A Comparative Analysis of Coding and Image Reasoning Capabilities.
Как получить доступ к Qwen 2 7B локально
Рекомендации по GPU
| Модель | Объём видеопамяти | Тип памяти | Относительная производительность | Ценовой диапазон |
|---|---|---|---|---|
| NVIDIA RTX 4080 Super | 16 ГБ | GDDR6X | Высокая | ⭐⭐⭐⭐⭐ (Высокий уровень) |
| AMD RX 7900 XTX | 24 ГБ | GDDR6 | Высокая | ⭐⭐⭐⭐⭐ (Высокий уровень) |
| NVIDIA RTX 4070 Ti Super | 16 ГБ | GDDR6X | Средне-высокая | ⭐⭐⭐⭐ (Выше среднего) |
| AMD RX 7600 XT | 16 ГБ | GDDR6 | Средняя | ⭐⭐⭐ (Средний уровень) |
| NVIDIA RTX 4060 Ti (16GB) | 16 ГБ | GDDR6 | Средняя | ⭐⭐⭐ (Средний уровень) |
Быстрый старт
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Как получить доступ к Qwen 2 7B через Novita AI
Пошаговое руководство
Novita AI — это облачная платформа искусственного интеллекта, которая предоставляет разработчикам простой способ развёртывания моделей ИИ через наш простой API, а также предлагает доступный и надёжный GPU-кластер для создания и масштабирования.
Шаг 1: Войдите в систему и откройте библиотеку моделей
Войдите в свою учётную запись и нажмите на кнопку Model Library.

Попробовать Qwen 2 7B Demo сейчас!
Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите модель, соответствующую вашим потребностям.
Шаг 3: Начните бесплатную пробную версию
Начните бесплатную пробную версию, чтобы изучить возможности выбранной модели.
Шаг 4: Получите ваш API-ключ
Для аутентификации с помощью API мы предоставим вам новый API-ключ. Перейдя на страницу Settings, вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.

После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с помощью вашего API-ключа, чтобы начать взаимодействие с Novita AI LLM. Это пример использования API chat completions для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen-2-7b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
После регистрации Novita AI предоставляет $0.5 кредита для начала работы!
Если бесплатные кредиты закончатся, вы можете оплатить дальнейшее использование.
Какие методы подходят вам?
Сравнение локального доступа и доступа через API
Локальный доступ
Преимущества:
- Обеспечивает более полный контроль над моделью и её настройками.
- Подходит для обработки длинных текстов благодаря использованию YARN для улучшения экстраполяции длины модели.
- Без recurring costs.
Недостатки:
- Требует значительных аппаратных ресурсов, в том числе 15,4 ГБ видеопамяти.
- Сложная настройка и конфигурация.
Доступ через API (например, Novita AI)
Преимущества:
- Простота настройки и использования, предоставляются пошаговые руководства.
- Не требуется локальное аппаратное обеспечение.
Недостатки:
- Требуется подключение к интернету.
- Влечёт затраты на токен: $0.054 за миллион входных токенов и $0.054 за миллион выходных токенов.
- Ограниченный контроль над кастомизацией и конфигурацией модели.
Рекомендации для разных групп пользователей
- Исследователи: для гибкости и контроля над экспериментами обычно предпочитается локальный доступ.
- Разработчики:
- Доступ через API подходит для создания приложений и быстрого прототипирования.
- Локальный доступ лучше подходит для тонкой настройки и индивидуальных рабочих процессов.
- Бизнес: доступ через API выгоден для быстрой интеграции в сервисы без больших первоначальных затрат. Локальное развёртывание может подойти командам с постоянными требованиями и возможностью инвестировать в инфраструктуру.
- Небольшие команды / отдельные пользователи: доступ через API обычно более практичен из-за меньших начальных затрат.
- Пользователи с ограниченными техническими навыками: доступ через API предпочтительнее, так как устраняет необходимость в глубоких технических знаниях.
Qwen 2‑7B — это универсальная и мощная модель, предназначенная для широкого круга приложений. Она поддерживает как локальный доступ, так и доступ через API, позволяя пользователям выбирать вариант, который наилучшим образом соответствует их конкретным потребностям, ресурсам и техническому опыту.
Часто задаваемые вопросы
Каковы ключевые архитектурные особенности моделей Qwen2?
Модели Qwen2 используют архитектуру на основе трансформеров с такими функциями, как активация SwiGLU, смещение QKV в внимании и групповое запросное внимание (GQA). Модели используют архитектуру на основе трансформеров с такими функциями, как активация SwiGLU, смещение QKV в внимании и групповое запросное внимание (GQA).
Какую длину контекста поддерживают модели Qwen2?
Базовые языковые модели предварительно обучены на контексте длиной 32K токенов, а некоторые модели демонстрируют способность к экстраполяции до 128K токенов при оценке PPL.
Novita AI — это универсальная облачная платформа, которая помогает реализовать ваши амбиции в области ИИ. Интегрированные API, бессерверные решения, GPU-инстансы — экономически эффективные инструменты, которые вам нужны. Избавьтесь от инфраструктуры, начните бесплатно и воплотите своё видение ИИ в реальность.



