

Points clés
Performances avancées
Qwen 2-7B repose sur une architecture basée sur des transformeurs avec des fonctionnalités avancées telles que l’activation SwiGLU, le biais d’attention QKV et l’attention par groupe de requêtes (GQA) pour une inférence plus rapide et une utilisation mémoire réduite. Il prend en charge une longueur de contexte allant jusqu’à 131 072 tokens, ce qui le rend idéal pour les tâches longues.
Comment accéder à Qwen 2-7B localement
L’accès local nécessite des GPU hautes performances (par exemple, NVIDIA RTX 4080 Super) avec un minimum de 15,4 Go de VRAM.
Comment accéder à Qwen 2-7B via une API
Des plateformes comme Novita AI proposent une configuration simple, éliminant le besoin de matériel.
Recommandations d’utilisation
L’accès local convient aux chercheurs ayant besoin d’un contrôle total, tandis que l’accès via API est idéal pour les développeurs et les entreprises cherchant un déploiement rapide et une simplicité d’utilisation.
Qwen 2-7B est un modèle de langage économique optimisé pour les performances, idéal pour des applications telles que la compréhension du langage naturel et la génération de code.
Qu’est-ce que Qwen 2 7B ?
Qwen 2 - 7B est un modèle de pointe de la série Qwen, basé sur une architecture transformeur. Il fait partie d’une série de modèles de langage allant de 0,5 à 72 milliards de paramètres, Qwen 2-7B-Instruct étant une variante affinée et optimisée pour les instructions.
Fonctionnalités clés
- Architecture transformeur : Intègre l’activation SwiGLU, le biais d’attention QKV et l’attention par groupe de requêtes.
- Tokeniseur : Tokeniseur amélioré capable de gérer plusieurs langues naturelles et du code de programmation.
- Entraînement : Pré-entraîné sur de vastes ensembles de données et affiné par supervision et optimisation directe des préférences.
- Longueur de contexte : Prend en charge jusqu’à 131 072 tokens pour les tâches longues.
- Support linguistique : Excelle en anglais et en chinois, avec un support supplémentaire pour d’autres langues.
Benchmark
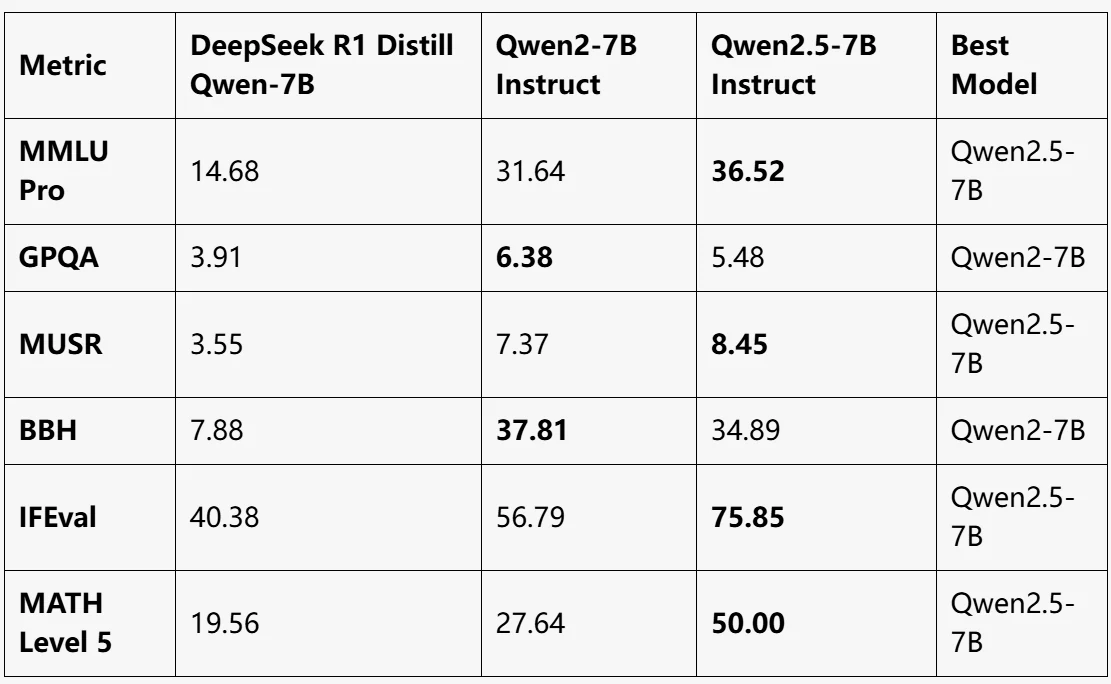
source de LLM EXPLORER
Qwen2.5-7B Instruct :
- Meilleure performance globale, en tête dans MMLU Pro, MUSR, IFEval et MATH Level 5.
- Amélioration significative du raisonnement mathématique (MATH Level 5 : 50).
Qwen2-7B Instruct :
- Meilleure performance dans GPQA et BBH.
- Modèle équilibré, mais légèrement en retrait par rapport à Qwen2.5-7B dans la plupart des autres métriques.
DeepSeek R1 Distill Qwen-7B :
- Performances les plus faibles sur tous les benchmarks.
- Adapté aux tâches légères, mais loin derrière les modèles Qwen2 sur les benchmarks complexes.
Comparaison avec d’autres modèles Qwen
La série Qwen 2 comprend des modèles de base et des modèles optimisés pour les instructions en cinq tailles : Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B et Qwen2-72B. Voici un résumé des informations clés pour ces modèles :
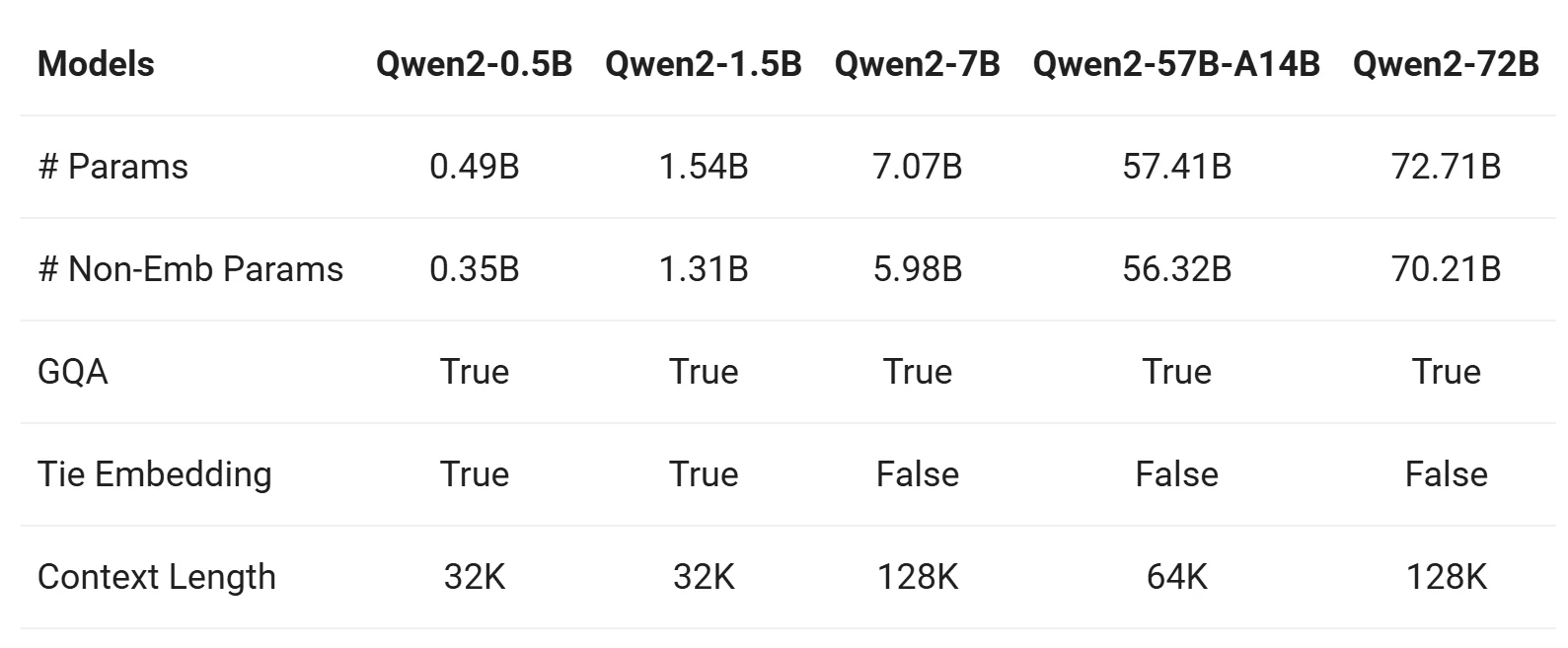
De Qwen
1. Attention par groupe de requêtes (GQA)
- Tous les modèles (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B) adoptent GQA, offrant :
- Une vitesse d’inférence plus rapide.
- Une utilisation mémoire réduite.
- Il s’agit d’une amélioration significative par rapport à Qwen1.5, où seuls les grands modèles (32B et 110B) utilisaient GQA.
2. Longueur de contexte
-
Modèles de base (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B) :
- Pré-entraînés avec une longueur de contexte de 32K tokens.
- Démontrent de fortes capacités d’extrapolation jusqu’à 128K tokens selon l’évaluation de la perplexité (PPL).
-
Modèles optimisés pour les instructions (Qwen2-7B-Instruct, Qwen2-72B-Instruct) :
- Évalués avec des tâches comme “Needle in a Haystack”.
- Performances exceptionnelles dans les tâches à long contexte, avec des capacités allant jusqu’à 128K tokens, surtout lorsqu’ils sont augmentés avec YARN.
3. Capacités multilingues
-
Tous les modèles (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B) :
- Bénéficient d’ensembles de données de pré-entraînement améliorés incluant 27 langues supplémentaires au-delà de l’anglais et du chinois.
- Les performances multilingues s’améliorent avec la taille du modèle, les plus grands modèles (Qwen2-57B, Qwen2-72B) excellant dans des tâches multilingues plus complexes.
Si vous souhaitez voir une comparaison plus détaillée des paramètres avec d’autres modèles comme Qwen 2.5 72B, vous pouvez consulter cet article : Qwen 2.5 72b vs Llama 3.3 70b : Quel modèle correspond à vos besoins ? ; Qwen 2.5 vs Llama 3.2 90B : Analyse comparative des capacités de codage et de raisonnement visuel.
Comment accéder à Qwen 2 7B localement
Recommandations GPU
| Modèle | Capacité VRAM | Type de mémoire | Performances relatives | Fourchette de prix |
|---|---|---|---|---|
| NVIDIA RTX 4080 Super | 16 Go | GDDR6X | Élevées | ⭐⭐⭐⭐⭐ (Haut de gamme) |
| AMD RX 7900 XTX | 24 Go | GDDR6 | Élevées | ⭐⭐⭐⭐⭐ (Haut de gamme) |
| NVIDIA RTX 4070 Ti Super | 16 Go | GDDR6X | Moyennes à élevées | ⭐⭐⭐⭐ (Milieu-haut de gamme) |
| AMD RX 7600 XT | 16 Go | GDDR6 | Moyennes | ⭐⭐⭐ (Milieu de gamme) |
| NVIDIA RTX 4060 Ti (16 Go) | 16 Go | GDDR6 | Moyennes | ⭐⭐⭐ (Milieu de gamme) |
Démarrage rapide
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Comment accéder à Qwen 2 7B via Novita AI
Guide étape par étape
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA grâce à notre API simple, tout en fournissant également un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Essayez la démo de Qwen 2 7B maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page « Settings », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE Clé API Novita AI>",
)
model = "qwen/qwen-2-7b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Lors de l’inscription, Novita AI offre un crédit de 0,5 $ pour vous lancer !
Si le crédit gratuit est épuisé, vous pouvez payer pour continuer à l’utiliser.
Quelles méthodes vous conviennent ?
Comparaison de l’accès local vs API
Accès local
Avantages :
- Offre plus de contrôle sur le modèle et sa configuration.
- Adapté au traitement de longs textes en utilisant YARN pour améliorer l’extrapolation de la longueur du modèle.
- Pas de coûts récurrents.
Inconvénients :
- Nécessite des ressources matérielles importantes, notamment 15,4 Go de VRAM.
- Configuration et paramétrage complexes.
Accès via API (ex. Novita AI)
Avantages :
- Facile à configurer et à utiliser, avec des guides étape par étape fournis.
- Pas besoin de ressources matérielles locales.
Inconvénients :
- Nécessite une connexion Internet.
- Implique des coûts par token : 0,054 $ par million de tokens d’entrée et 0,054 $ par million de tokens de sortie.
- Contrôle limité sur la personnalisation et la configuration du modèle.
Recommandations pour différents groupes d’utilisateurs
-
Chercheurs : L’accès local est généralement préféré pour la flexibilité et le contrôle des expériences.
-
Développeurs :
- L’accès via API convient pour créer des applications et du prototypage rapide.
- L’accès local est meilleur pour le réglage fin et les workflows personnalisés.
-
Entreprises : L’accès via API est bénéfique pour une intégration rapide dans les services sans coûts initiaux élevés. Le déploiement local peut convenir aux équipes ayant des besoins constants et la capacité d’investir dans l’infrastructure.
-
Petites équipes/Individus : L’accès via API est généralement plus pratique en raison de coûts de démarrage plus faibles.
-
Utilisateurs ayant des compétences techniques limitées : L’accès via API est préférable car il élimine le besoin de connaissances techniques approfondies.
Qwen 2 - 7B est un modèle polyvalent et puissant conçu pour une large gamme d’applications. Il prend en charge à la fois l’accès local et via API, permettant aux utilisateurs de choisir l’option qui correspond le mieux à leurs besoins spécifiques, ressources disponibles et expertise technique.
Questions fréquentes
Quelles sont les principales caractéristiques architecturales des modèles Qwen2 ?
Les modèles Qwen2 utilisent une architecture basée sur des transformeurs avec des fonctionnalités comme l’activation SwiGLU, le biais d’attention QKV et l’attention par groupe de requêtes (GQA). Les modèles utilisent une architecture basée sur des transformeurs avec des fonctionnalités comme l’activation SwiGLU, le biais d’attention QKV et l’attention par groupe de requêtes (GQA).
Quelles longueurs de contexte les modèles Qwen2 prennent-ils en charge ?
Les modèles de langage de base sont pré-entraînés sur des longueurs de contexte de 32K tokens, et certains modèles démontrent des capacités d’extrapolation jusqu’à 128K tokens lors de l’évaluation PPL.
Novita AI est la plateforme cloud tout-en-un qui alimente vos ambitions en IA. API intégrées, serverless, GPU Instance — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



