

Principais Destaques
Desempenho Avançado
O Qwen 2-7B é construído sobre uma arquitetura baseada em transformer com recursos avançados como SwiGLU activation, attention QKV bias e Group Query Attention (GQA) para inferência mais rápida e menor uso de memória. Ele suporta um comprimento de contexto de até 131.072 tokens, tornando-o ideal para tarefas de contexto longo.
Como Acessar o Qwen 2-7B Localmente
O acesso local requer GPUs de alto desempenho (por exemplo, NVIDIA RTX 4080 Super) com um mínimo de 15,4 GB de VRAM.
Como Acessar o Qwen 2-7B via API
Plataformas como a Novita AI oferecem uma configuração simples, eliminando a necessidade de hardware.
Recomendações de Uso
O acesso local é adequado para pesquisadores que precisam de controle total, enquanto o acesso via API é ideal para desenvolvedores e empresas que buscam implantação rápida e facilidade de uso.
O Qwen 2-7B é um modelo de linguagem econômico e otimizado para desempenho, ideal para aplicações como compreensão de linguagem natural e geração de código.
O que é o Qwen 2 7B ?
O Qwen 2 - 7B é um modelo de ponta na série Qwen, construído sobre arquitetura baseada em transformer. Ele faz parte de uma série de modelos de linguagem que variam de 0,5 a 72 bilhões de parâmetros, sendo o Qwen 2-7B-Instruct uma variante ajustada e otimizada para instruções.
Principais Recursos
- Arquitetura Transformer: Incorpora ativação SwiGLU, bias QKV de atenção e atenção de consulta em grupo.
- Tokenizer: Tokenizador aprimorado capaz de lidar com múltiplas linguagens naturais e código de programação.
- Treinamento: Pré-treinado em conjuntos de dados extensos e refinado por meio de ajuste fino supervisionado e otimização direta de preferências.
- Comprimento de Contexto: Suporta até 131.072 tokens para tarefas de contexto longo.
- Suporte a Idiomas: Excelente em inglês e chinês, com suporte adicional para outros idiomas.
Benchmark
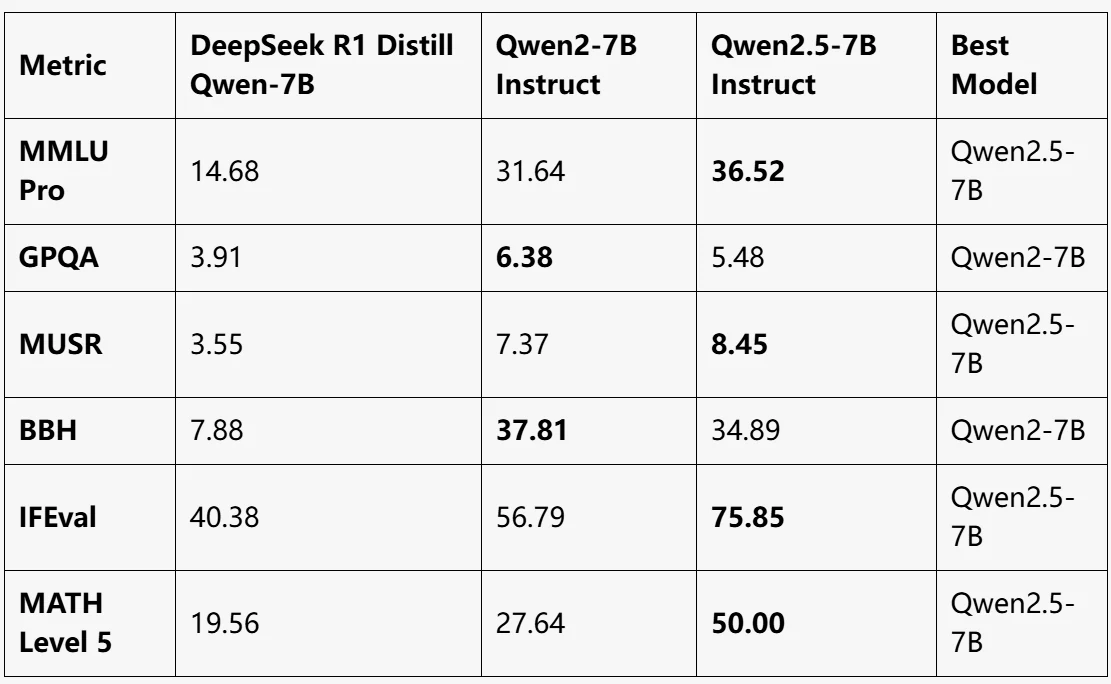
fonte: LLM EXPLORER
Qwen2.5-7B Instruct:
- Melhor desempenho geral, liderando em MMLU Pro, MUSR, IFEval e MATH Level 5.
- Alcança uma melhoria significativa no raciocínio matemático (MATH Level 5: 50).
Qwen2-7B Instruct:
- Melhor desempenho em GPQA e BBH.
- Um modelo equilibrado, mas ligeiramente atrás do Qwen2.5-7B na maioria das outras métricas.
DeepSeek R1 Distill Qwen-7B:
- Menor desempenho em todos os benchmarks.
- Adequado para tarefas leves, mas fica muito atrás dos modelos Qwen2 em benchmarks complexos.
Comparação com outros modelos Qwen
A série Qwen 2 inclui modelos base e ajustados para instrução em cinco tamanhos: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B e Qwen2-72B. Abaixo está um resumo das principais informações para esses modelos:
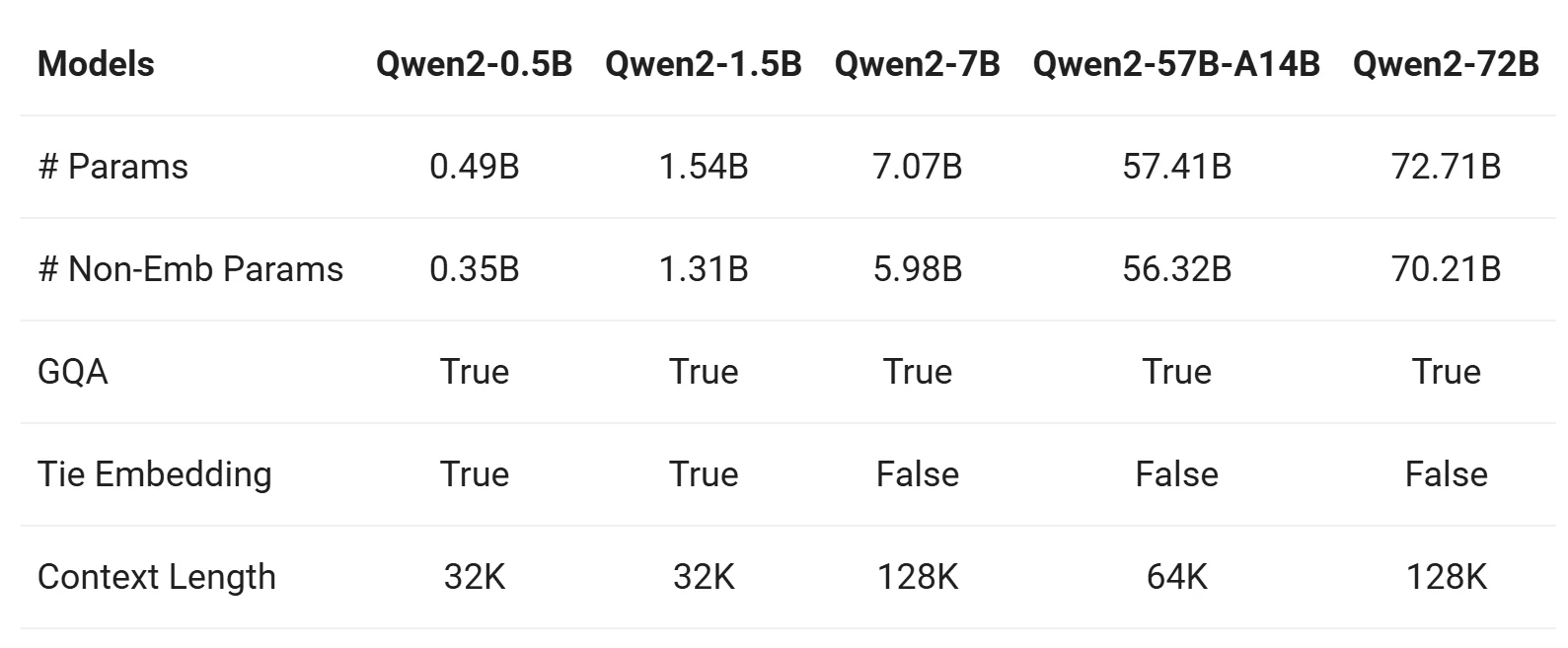
De Qwen
1. Atenção de Consulta em Grupo (GQA)
- Todos os modelos (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B) adotam GQA, oferecendo:
- Velocidade de inferência mais rápida.
- Menor uso de memória.
- Esta é uma melhoria significativa em comparação com o Qwen1.5, onde apenas modelos grandes (32B e 110B) usavam GQA.
2. Comprimento de Contexto
- Modelos Base (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B):
- Pré-treinados com um comprimento de contexto de 32K tokens.
- Demonstram fortes capacidades de extrapolação de até 128K tokens com base na avaliação de perplexidade (PPL).
- Modelos Ajustados para Instrução (Qwen2-7B-Instruct, Qwen2-72B-Instruct):
- Avaliados usando tarefas como “Needle in a Haystack.”
- Têm desempenho excepcionalmente bom em tarefas de contexto longo, com capacidades que se estendem até 128K tokens, especialmente quando aumentados com YARN.
3. Capacidades Multilíngues
- Todos os Modelos (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B):
- Beneficiam-se de conjuntos de dados de pré-treinamento melhorados que incluem 27 idiomas adicionais além do inglês e chinês.
- O desempenho multilíngue melhora com o tamanho do modelo, com modelos maiores (Qwen2-57B, Qwen2-72B) se destacando em tarefas multilíngues mais complexas.
Se você quiser ver uma comparação mais detalhada de parâmetros com outros modelos como Qwen 2.5 72B, confira este artigo: Qwen 2.5 72b vs Llama 3.3 70b: Qual modelo atende às suas necessidades? ; Qwen 2.5 vs Llama 3.2 90B: Uma análise comparativa das capacidades de codificação e raciocínio de imagem.
Como Acessar o Qwen 2 7B Localmente
Recomendações de GPU
| Modelo | Capacidade de VRAM | Tipo de Memória | Desempenho Relativo | Faixa de Preço |
|---|---|---|---|---|
| NVIDIA RTX 4080 Super | 16 GB | GDDR6X | Alto | ⭐⭐⭐⭐⭐ (Alto Nível) |
| AMD RX 7900 XTX | 24 GB | GDDR6 | Alto | ⭐⭐⭐⭐⭐ (Alto Nível) |
| NVIDIA RTX 4070 Ti Super | 16 GB | GDDR6X | Médio-Alto | ⭐⭐⭐⭐ (Médio-Alto) |
| AMD RX 7600 XT | 16 GB | GDDR6 | Médio | ⭐⭐⭐ (Médio) |
| NVIDIA RTX 4060 Ti (16GB) | 16 GB | GDDR6 | Médio | ⭐⭐⭐ (Médio) |
Início Rápido
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Como Acessar o Qwen 2 7B via Novita AI
Guia Passo a Passo
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Experimente o Demo do Qwen 2 7B Agora!
Passo 2: Escolha seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie seu Teste Gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha sua Chave de API
Para autenticar com a API, forneceremos a você uma nova chave de API. Entrando na página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen-2-7b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Após o registro, a Novita AI oferece um crédito de $0,5 para você começar!
Se os créditos gratuitos acabarem, você pode pagar para continuar usando.
Quais Métodos são Adequados para Você?
Comparação entre Acesso Local e via API
Acesso Local
Vantagens:
- Oferece mais controle sobre o modelo e sua configuração.
- Adequado para lidar com textos longos utilizando YARN para melhorar a extrapolação de comprimento do modelo.
- Sem custos recorrentes.
Desvantagens:
- Requer recursos de hardware significativos, incluindo 15,4 GB de VRAM.
- Configuração complexa.
Acesso via API (ex.: Novita AI)
Vantagens:
- Fácil de configurar e usar, com guias passo a passo fornecidos.
- Sem necessidade de recursos de hardware locais.
Desvantagens:
- Requer conexão com a internet.
- Envolve custos por token: $0,054 por milhão de tokens de entrada e $0,054 por milhão de tokens de saída.
- Controle limitado sobre personalização e configuração do modelo.
Recomendações para Diferentes Grupos de Usuários
- Pesquisadores: O acesso local é geralmente preferido pela flexibilidade e controle sobre experimentos.
- Desenvolvedores:
- O acesso via API é adequado para construir aplicações e prototipagem rápida.
- O acesso local é melhor para ajuste fino e fluxos de trabalho personalizados.
- Empresas: O acesso via API é benéfico para integração rápida em serviços sem altos custos iniciais. A implantação local pode ser adequada para equipes com requisitos consistentes e capacidade de investir em infraestrutura.
- Pequenas Equipes/Indivíduos: O acesso via API é geralmente mais prático devido aos menores custos iniciais.
- Usuários com Habilidades Técnicas Limitadas: O acesso via API é preferível, pois elimina a necessidade de conhecimento técnico aprofundado.
Qwen 2 - 7B é um modelo versátil e poderoso projetado para uma ampla gama de aplicações. Ele suporta acesso local e via API, permitindo que os usuários escolham a opção que melhor se alinha às suas necessidades específicas, recursos disponíveis e conhecimentos técnicos.
Perguntas Frequentes
Quais são as principais características arquitetônicas dos modelos Qwen2?
Os modelos Qwen2 empregam uma arquitetura baseada em transformer com recursos como ativação SwiGLU, bias QKV de atenção e Grouped Query Attention (GQA).
Quais comprimentos de contexto os modelos Qwen2 suportam?
Os modelos de linguagem base são pré-treinados em comprimentos de contexto de 32K tokens, e alguns modelos demonstram capacidades de extrapolação de até 128K tokens na avaliação PPL.
Novita AI é a plataforma de nuvem all-in-one que impulsiona suas ambições de IA. APIs integradas, serverless, GPU Instance — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece de graça e torne sua visão de IA realidade.



