

Wichtige Highlights
Fortschrittliche Leistung
Qwen 2-7B basiert auf einer transformerbasierten Architektur mit fortschrittlichen Funktionen wie SwiGLU-Aktivierung, Attention QKV-Bias und Group Query Attention (GQA) für schnellere Inferenz und reduzierten Speicherverbrauch. Es unterstützt eine Kontextlänge von bis zu 131.072 Token, was es ideal für Aufgaben mit langen Kontexten macht.
So greifen Sie lokal auf Qwen 2-7B zu
Lokaler Zugriff erfordert leistungsstarke GPUs (z. B. NVIDIA RTX 4080 Super) mit mindestens 15,4 GB VRAM.
So greifen Sie über die API auf Qwen 2-7B zu
Plattformen wie Novita AI bieten eine einfache Einrichtung und machen Hardware überflüssig.
Nutzungsempfehlungen
Lokaler Zugriff eignet sich für Forscher, die volle Kontrolle benötigen, während API-Zugriff ideal für Entwickler und Unternehmen ist, die schnelle Bereitstellung und einfache Nutzung suchen.
Qwen 2-7B ist ein kosteneffizientes Sprachmodell, das für Leistung optimiert ist und sich ideal für Anwendungen wie natürliches Sprachverständnis und Codegenerierung eignet.
Was ist Qwen 2 7B?
Qwen 2-7B ist ein hochmodernes Modell der Qwen-Reihe, das auf einer transformerbasierten Architektur aufbaut. Es ist Teil einer Serie von Sprachmodellen mit 0,5 bis 72 Milliarden Parametern, wobei Qwen 2-7B-Instruct eine feinabgestimmte, anweisungsoptimierte Variante ist.
Hauptmerkmale
- Transformer-Architektur: Enthält SwiGLU-Aktivierung, Attention QKV-Bias und Group Query Attention.
- Tokenizer: Verbesserter Tokenizer, der mehrere natürliche Sprachen und Programmcode verarbeiten kann.
- Training: Vortraining auf umfangreichen Datensätzen und Verfeinerung durch überwachte Feinabstimmung und direkte Präferenzoptimierung.
- Kontextlänge: Unterstützt bis zu 131.072 Token für Aufgaben mit langen Kontexten.
- Sprachunterstützung: Hervorragend in Englisch und Chinesisch, mit zusätzlicher Unterstützung für andere Sprachen.
Benchmark
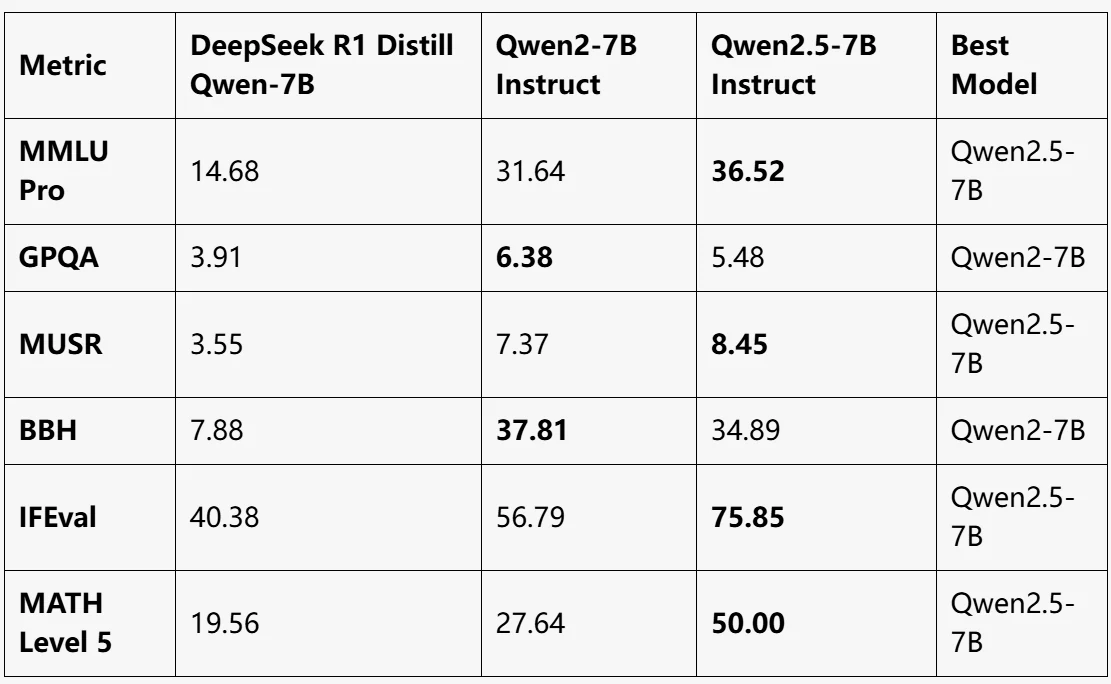
Quelle: LLM EXPLORER
Qwen2.5-7B Instruct:
- Insgesamt beste Leistung, führend in MMLU Pro, MUSR, IFEval und MATH Level 5.
- Erhebliche Verbesserung im mathematischen Denken (MATH Level 5: 50).
Qwen2-7B Instruct:
- Beste Leistung in GPQA und BBH.
- Ein ausgewogenes Modell, aber in den meisten anderen Metriken leicht hinter Qwen2.5-7B zurück.
DeepSeek R1 Distill Qwen-7B:
- Geringste Leistung in allen Benchmarks.
- Geeignet für leichte Aufgaben, liegt aber weit hinter den Qwen2-Modellen bei komplexen Benchmarks.
Vergleich mit anderen Qwen-Modellen
Die Qwen-2-Reihe umfasst Basis- und anweisungsoptimierte Modelle in fünf Größen: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B und Qwen2-72B. Nachfolgend eine Zusammenfassung der wichtigsten Informationen zu diesen Modellen:
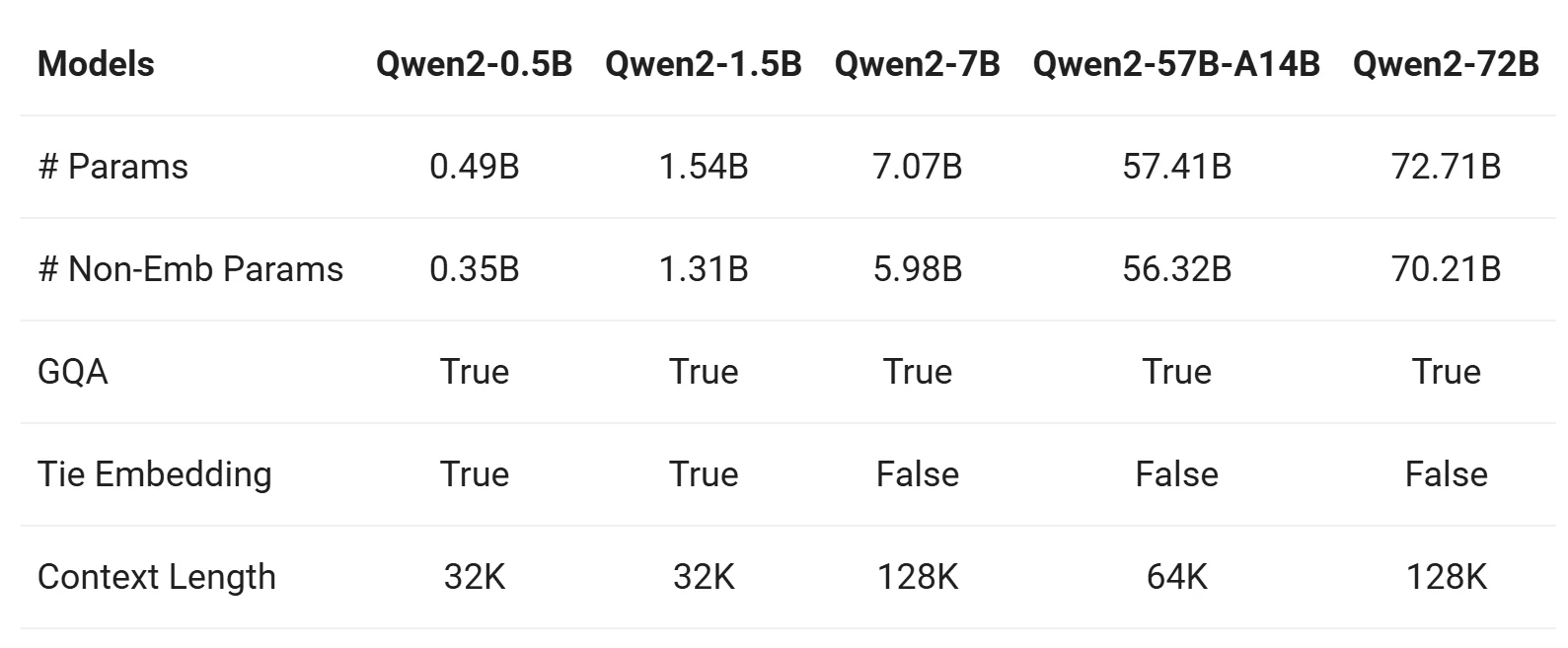
Von Qwen
1. Group Query Attention (GQA)
- Alle Modelle (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B) verwenden GQA, was Folgendes bietet:
- Schnellere Inferenzgeschwindigkeit.
- Reduzierter Speicherverbrauch.
- Dies ist eine wesentliche Verbesserung gegenüber Qwen1.5, bei dem nur große Modelle (32B und 110B) GQA verwendeten.
2. Kontextlänge
-
Basis-Modelle (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B):
- Vortraining mit einer Kontextlänge von 32K Token.
- Zeigen starke Extrapolationsfähigkeiten bis zu 128K Token basierend auf der Perplexität (PPL)-Bewertung.
-
Anweisungsoptimierte Modelle (Qwen2-7B-Instruct, Qwen2-72B-Instruct):
- Bewertet mit Aufgaben wie „Needle in a Haystack“.
- Absolut hervorragende Leistung bei Aufgaben mit langen Kontexten, mit Fähigkeiten, die bis zu 128K Token reichen, insbesondere wenn sie mit YARN erweitert werden.
3. Mehrsprachige Fähigkeiten
-
Alle Modelle (Qwen2-0.5B, Qwen2-7B, Qwen2-57B, Qwen2-72B):
- Profitieren von verbesserten Vortrainingsdatensätzen, die 27 zusätzliche Sprachen über Englisch und Chinesisch hinaus enthalten.
- Mehrsprachige Leistung verbessert sich mit der Modellgröße, wobei größere Modelle (Qwen2-57B, Qwen2-72B) bei komplexeren mehrsprachigen Aufgaben hervorragende Ergebnisse erzielen.
Wenn Sie einen detaillierteren Parametervergleich mit anderen Modellen wie Qwen 2.5 72B sehen möchten, lesen Sie diesen Artikel: Qwen 2.5 72b vs. Llama 3.3 70b: Welches Modell passt zu Ihren Anforderungen? ; Qwen 2.5 vs. Llama 3.2 90B: Eine vergleichende Analyse der Programmier- und Bildverständnisfähigkeiten.
So greifen Sie lokal auf Qwen 2 7B zu
GPU-Empfehlungen
| Modell | VRAM-Kapazität | Speichertyp | Relative Leistung | Preisspanne |
|---|---|---|---|---|
| NVIDIA RTX 4080 Super | 16 GB | GDDR6X | Hoch | ⭐⭐⭐⭐⭐ (High-End) |
| AMD RX 7900 XTX | 24 GB | GDDR6 | Hoch | ⭐⭐⭐⭐⭐ (High-End) |
| NVIDIA RTX 4070 Ti Super | 16 GB | GDDR6X | Mittel-Hoch | ⭐⭐⭐⭐ (Oberes Mittelklasse) |
| AMD RX 7600 XT | 16 GB | GDDR6 | Mittel | ⭐⭐⭐ (Mittelklasse) |
| NVIDIA RTX 4060 Ti (16GB) | 16 GB | GDDR6 | Mittel | ⭐⭐⭐ (Mittelklasse) |
Schnellstart
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
So greifen Sie über Novita AI auf Qwen 2 7B zu
Schritt-für-Schritt-Anleitung
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bereitstellt.
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Model Library.

Testen Sie Qwen 2 7B Demo jetzt!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite Settings auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem Paketmanager Ihrer Programmiersprache.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen-2-7b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Bei der Registrierung stellt Novita AI ein Guthaben von 0,50 $ zur Verfügung, damit Sie loslegen können!
Wenn das kostenlose Guthaben aufgebraucht ist, können Sie bezahlen, um die Nutzung fortzusetzen.
Welche Methoden sind für Sie geeignet?
Vergleich von lokalem und API-Zugriff
Lokaler Zugriff
Vorteile:
- Bietet mehr Kontrolle über das Modell und seine Konfiguration.
- Geeignet für die Verarbeitung langer Texte durch Nutzung von YARN zur Verbesserung der Längenextrapolation des Modells.
- Keine wiederkehrenden Kosten.
Nachteile:
- Erfordert erhebliche Hardware-Ressourcen, darunter 15,4 GB VRAM.
- Komplexe Einrichtung und Konfiguration.
API-Zugriff (z. B. Novita AI)
Vorteile:
- Einfach einzurichten und zu verwenden, mit Schritt-für-Schritt-Anleitungen.
- Keine lokalen Hardware-Ressourcen erforderlich.
Nachteile:
- Erfordert eine Internetverbindung.
- Kosten pro Token: 0,054 $ pro Million Eingabe-Token und 0,054 $ pro Million Ausgabe-Token.
- Eingeschränkte Kontrolle über Modellanpassung und Konfiguration.
Empfehlungen für verschiedene Benutzergruppen
-
Forscher: Lokaler Zugriff wird in der Regel bevorzugt für Flexibilität und Kontrolle über Experimente.
-
Entwickler:
- API-Zugriff eignet sich für die Entwicklung von Anwendungen und schnelles Prototyping.
- Lokaler Zugriff ist besser für Feinabstimmung und benutzerdefinierte Workflows.
-
Unternehmen: API-Zugriff ist vorteilhaft für die schnelle Integration in Dienste ohne hohe Anfangskosten. Lokale Bereitstellung eignet sich für Teams mit konstanten Anforderungen und der Möglichkeit, in Infrastruktur zu investieren.
-
Kleine Teams/Einzelpersonen: API-Zugriff ist in der Regel praktischer aufgrund geringerer Startkosten.
-
Benutzer mit eingeschränkten technischen Fähigkeiten: API-Zugriff ist vorzuziehen, da er kein tiefes technisches Wissen voraussetzt.
Qwen 2-7B ist ein vielseitiges und leistungsstarkes Modell, das für eine Vielzahl von Anwendungen entwickelt wurde. Es unterstützt sowohl lokalen als auch API-Zugriff, sodass Benutzer die Option wählen können, die ihren spezifischen Anforderungen, verfügbaren Ressourcen und technischen Kenntnissen am besten entspricht.
Häufig gestellte Fragen
Was sind die wichtigsten architektonischen Merkmale der Qwen2-Modelle?
Qwen2-Modelle verwenden eine transformerbasierte Architektur mit Funktionen wie SwiGLU-Aktivierung, Attention QKV-Bias und Grouped Query Attention (GQA).
Welche Kontextlängen unterstützen die Qwen2-Modelle?
Die Basis-Sprachmodelle sind auf Kontextlängen von 32K Token vortrainiert, und einige Modelle zeigen Extrapolationsfähigkeiten bis zu 128K Token in der PPL-Bewertung.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen beflügelt. Integrierte APIs, serverlos, GPU-Instanz – die kostengünstigen Tools, die Sie brauchen. Infrastruktur überflüssig, kostenlos starten und Ihre KI-Vision verwirklichen.



