

النقاط الرئيسية
أداء متقدم
تم بناء Qwen 2-7B على بنية قائمة على المحولات مع ميزات متقدمة مثل تنشيط SwiGLU و انحياز QKV للانتباه و انتباه الاستعلام الجماعي (GQA) للاستدلال الأسرع وتقليل استخدام الذاكرة. يدعم طول سياق يصل إلى 131,072 رمزًا، مما يجعله مثاليًا للمهام ذات السياق الطويل.
كيفية الوصول إلى Qwen 2-7B محليًا
يتطلب الوصول المحلي وحدات معالجة رسومية عالية الأداء (مثل NVIDIA RTX 4080 Super) بذاكرة VRAM لا تقل عن 15.4 جيجابايت.
كيفية الوصول إلى Qwen 2-7B عبر API
توفر منصات مثل Novita AI إعدادًا بسيطًا، مما يلغي الحاجة إلى الأجهزة.
توصيات الاستخدام
الوصول المحلي مناسب للباحثين الذين يحتاجون إلى تحكم كامل، بينما الوصول عبر API مثالي للمطورين والشركات التي تسعى إلى نشر سريع وسهولة الاستخدام.
Qwen 2-7B هو نموذج لغة فعال من حيث التكلفة محسّن للأداء، مثالي لتطبيقات مثل فهم اللغة الطبيعية وتوليد الأكواد.
ما هو Qwen 2 7B؟
Qwen 2 - 7B هو نموذج متطور في سلسلة Qwen، مبني على بنية قائمة على المحولات. وهو جزء من سلسلة نماذج لغوية تتراوح من 0.5 إلى 72 مليار معامل، مع Qwen 2-7B-Instruct كمتغير مضبوط ومحسّن للتعليمات.
الميزات الرئيسية
- بنية المحولات: تتضمن تنشيط SwiGLU، وانحياز QKV للانتباه، وانتباه الاستعلام الجماعي.
- المُرمِّز (Tokenizer): مُرمِّز محسّن قادر على التعامل مع لغات طبيعية متعددة وأكواد برمجية.
- التدريب: تم التدريب المسبق على مجموعات بيانات واسعة النطاق وتم تنقيحه من خلال الضبط الدقيق الخاضع للإشراف وتحسين التفضيل المباشر.
- طول السياق: يدعم ما يصل إلى 131,072 رمزًا للمهام ذات السياق الطويل.
- دعم اللغة: يتفوق في اللغتين الإنجليزية والصينية، مع دعم إضافي للغات أخرى.
المعايير
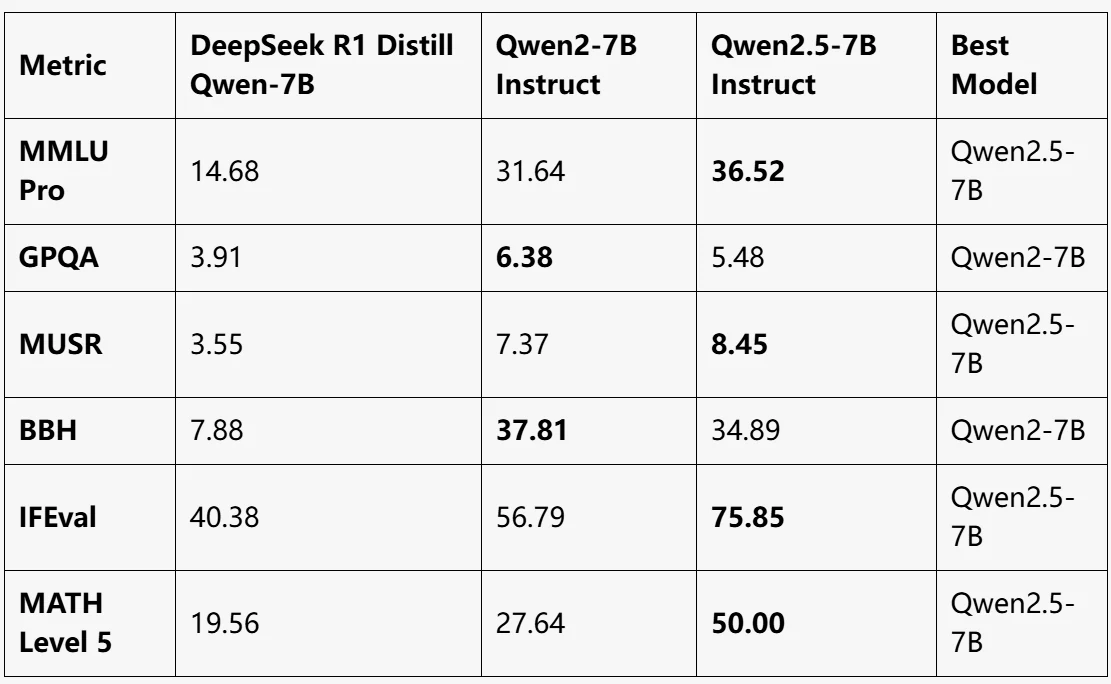
المصدر من LLM EXPLORER
Qwen2.5-7B Instruct:
- أفضل أداء إجمالي، يتصدر في MMLU Pro وMUSR وIFEval وMATH Level 5.
- يحقق تحسنًا كبيرًا في التفكير الرياضي (MATH Level 5: 50).
Qwen2-7B Instruct:
- أفضل أداء في GPQA وBBH.
- نموذج متوازن، لكنه متأخر قليلاً عن Qwen2.5-7B في معظم المقاييس الأخرى.
DeepSeek R1 Distill Qwen-7B:
- أقل أداء عبر جميع المعايير.
- مناسب للمهام خفيفة الوزن لكنه متخلف كثيرًا عن نماذج Qwen2 في المعايير المعقدة.
مقارنة مع نماذج Qwen الأخرى
تتضمن سلسلة Qwen 2 نماذج أساسية ومحسّنة للتعليمات في خمسة أحجام: Qwen2-0.5B وQwen2-1.5B وQwen2-7B وQwen2-57B-A14B وQwen2-72B. فيما يلي ملخص للمعلومات الرئيسية لهذه النماذج:
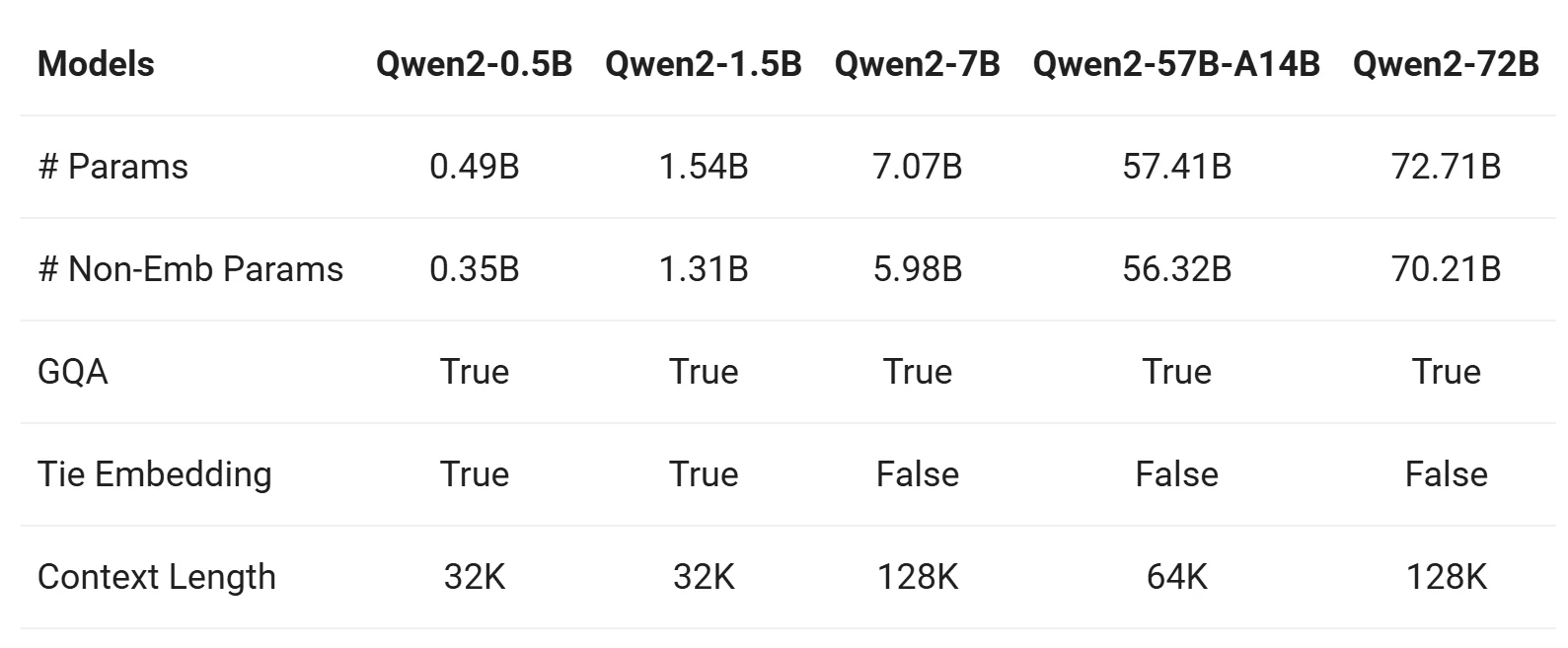
من Qwen
1. انتباه الاستعلام الجماعي (GQA)
- تتبنى جميع النماذج (Qwen2-0.5B وQwen2-7B وQwen2-57B وQwen2-72B) تقنية GQA، مما يوفر:
- سرعة استدلال أسرع.
- تقليل استخدام الذاكرة.
- هذا تحسن كبير مقارنة بـ Qwen1.5، حيث كانت النماذج الكبيرة فقط (32B و110B) تستخدم GQA.
2. طول السياق
-
النماذج الأساسية (Qwen2-0.5B وQwen2-7B وQwen2-57B وQwen2-72B):
- تم التدريب المسبق بطول سياق 32 ألف رمز.
- تُظهر قدرات استقراء قوية تصل إلى 128 ألف رمز بناءً على تقييم الحيرة (PPL).
-
النماذج المحسّنة للتعليمات (Qwen2-7B-Instruct وQwen2-72B-Instruct):
- تم تقييمها باستخدام مهام مثل “Needle in a Haystack”.
- تؤدي أداءً استثنائيًا في المهام ذات السياق الطويل، مع قدرات تمتد حتى 128 ألف رمز، خاصة عند تعزيزها بـ YARN.
3. القدرات متعددة اللغات
-
جميع النماذج (Qwen2-0.5B وQwen2-7B وQwen2-57B وQwen2-72B):
- تستفيد من مجموعات بيانات التدريب المسبق المحسّنة التي تتضمن 27 لغة إضافية إلى جانب الإنجليزية والصينية.
- يتحسن الأداء متعدد اللغات مع حجم النموذج، حيث تتفوق النماذج الأكبر (Qwen2-57B وQwen2-72B) في المهام متعددة اللغات الأكثر تعقيدًا.
إذا كنت تريد رؤية مقارنة معاملات أكثر تفصيلاً مع نماذج أخرى مثل Qwen 2.5 72B، يمكنك الاطلاع على هذه المقالة: Qwen 2.5 72b vs Llama 3.3 70b: أي نموذج يناسب احتياجاتك؟ ; Qwen 2.5 vs Llama 3.2 90B: تحليل مقارن لقدرات البرمجة واستدلال الصور.
كيفية الوصول إلى Qwen 2 7B محليًا
توصيات وحدة معالجة الرسوميات (GPU)
| النموذج | سعة VRAM | نوع الذاكرة | الأداء النسبي | النطاق السعري |
|---|---|---|---|---|
| NVIDIA RTX 4080 Super | 16 جيجابايت | GDDR6X | عالي | ⭐⭐⭐⭐⭐ (فئة عالية) |
| AMD RX 7900 XTX | 24 جيجابايت | GDDR6 | عالي | ⭐⭐⭐⭐⭐ (فئة عالية) |
| NVIDIA RTX 4070 Ti Super | 16 جيجابايت | GDDR6X | متوسط-عالي | ⭐⭐⭐⭐ (فئة وسط-عالية) |
| AMD RX 7600 XT | 16 جيجابايت | GDDR6 | متوسط | ⭐⭐⭐ (فئة وسط) |
| NVIDIA RTX 4060 Ti (16GB) | 16 جيجابايت | GDDR6 | متوسط | ⭐⭐⭐ (فئة وسط) |
بداية سريعة
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
كيفية الوصول إلى Qwen 2 7B عبر Novita AI
دليل خطوة بخطوة
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة لدينا، مع توفير سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
قم بتسجيل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة وحدد النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ نسختك التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف إمكانيات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنزودك بمفتاح API جديد. بالدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة المستخدمة.

بعد التثبيت، قم باستيراد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام API لإكمال المحادثة لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen-2-7b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
عند التسجيل، تقدم Novita AI رصيدًا بقيمة $0.5 لتبدأ!
إذا نفد الرصيد المجاني، يمكنك الدفع لمواصلة الاستخدام.
أي الطرق مناسبة لك؟
مقارنة بين الوصول المحلي وعبر API
الوصول المحلي
الإيجابيات:
- يمنح تحكمًا أكبر في النموذج وتكوينه.
- مناسب للتعامل مع النصوص الطويلة من خلال الاستفادة من YARN لتعزيز استقراء طول النموذج.
- لا توجد تكاليف متكررة.
السلبيات:
- يتطلب موارد أجهزة كبيرة، بما في ذلك 15.4 جيجابايت من VRAM.
- إعداد وتكوين معقدان.
الوصول عبر API (مثل Novita AI)
الإيجابيات:
- سهل الإعداد والاستخدام، مع توفير أدلة خطوة بخطوة.
- لا حاجة لموارد أجهزة محلية.
السلبيات:
- يتطلب اتصالاً بالإنترنت.
- يتضمن تكاليف لكل رمز: 0.054 دولار لكل مليون رمز إدخال و 0.054 دولار لكل مليون رمز إخراج.
- تحكم محدود في تخصيص النموذج وتكوينه.
توصيات لمجموعات المستخدمين المختلفة
-
الباحثون: الوصول المحلي هو المفضل عمومًا للمرونة والتحكم في التجارب.
-
المطورون:
- الوصول عبر API مناسب لبناء التطبيقات والنماذج الأولية السريعة.
- الوصول المحلي أفضل للضبط الدقيق وسير العمل المخصص.
-
الشركات: الوصول عبر API مفيد للتكامل السريع في الخدمات دون تكاليف أولية عالية. قد يكون النشر المحلي مناسبًا للفرق ذات المتطلبات الثابتة والقدرة على الاستثمار في البنية التحتية.
-
الفرق الصغيرة / الأفراد: الوصول عبر API أكثر عملية عمومًا بسبب انخفاض تكاليف البدء.
-
المستخدمون ذوو المهارات التقنية المحدودة: الوصول عبر API هو الأفضل لأنه يزيل الحاجة إلى معرفة تقنية عميقة.
Qwen 2 - 7B هو نموذج متعدد الاستخدامات وقوي مصمم لمجموعة واسعة من التطبيقات. يدعم كلاً من الوصول المحلي وعبر API، مما يسمح للمستخدمين باختيار الخيار الذي يتوافق بشكل أفضل مع احتياجاتهم الخاصة والموارد المتاحة وخبراتهم التقنية.
الأسئلة الشائعة
ما هي السمات المعمارية الرئيسية لنماذج Qwen2؟
تستخدم نماذج Qwen2 بنية قائمة على المحولات مع ميزات مثل تنشيط SwiGLU وانحياز QKV للانتباه وانتباه الاستعلام الجماعي (GQA).
ما أطوال السياق التي تدعمها نماذج Qwen2؟
يتم التدريب المسبق لنماذج اللغة الأساسية على أطوال سياق تبلغ 32 ألف رمز، وتظهر بعض النماذج قدرات استقراء تصل إلى 128 ألف رمز في تقييم PPL.
Novita AI هي المنصة السحابية الشاملة التي تمكن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خادم، مثيل GPU — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، وابدأ مجانًا، وحقق رؤيتك في الذكاء الاصطناعي.



