

主なポイント
高度なパフォーマンス
Qwen 2-7Bはトランスフォーマーベースのアーキテクチャを採用し、**SwiGLU活性化 、 アテンションQKVバイアス **、Group Query Attention (GQA) などの高度な機能により、推論速度の向上とメモリ使用量の削減を実現します。最大 131,072トークン のコンテキスト長をサポートし、長文タスクに最適です。
Qwen 2-7Bをローカルで利用する方法
ローカルアクセスには高性能GPU(例:NVIDIA RTX 4080 Super)と最低 15.4 GBのVRAM が必要です。
Qwen 2-7BをAPI経由で利用する方法
Novita AI のようなプラットフォームは簡単なセットアップで済み、ハードウェアの準備が不要です。
利用推奨
ローカルアクセスは完全な制御が必要な研究者向け、APIアクセスは迅速なデプロイと簡単さを求める開発者や企業向けです。
Qwen 2-7Bはパフォーマンスに最適化されたコスト効率の高い言語モデルで、自然言語理解やコード生成などのアプリケーションに最適です。
Qwen 2 7Bとは?
Qwen 2-7Bは、Qwenシリーズの最先端モデルであり、トランスフォーマーベースのアーキテクチャを採用しています。パラメータ数は0.5から720億の範囲で構成される言語モデルシリーズの一部であり、Qwen 2-7B-Instructはファインチューニングされ、指示に最適化されたバリアントです。
主な特徴
- トランスフォーマーアーキテクチャ:SwiGLU活性化、アテンションQKVバイアス、group query attentionを採用。
- トークナイザー:複数の自然言語とプログラミングコードを処理可能な強化トークナイザー。
- 学習:大規模データセットで事前学習され、教師ありファインチューニングと直接選好最適化によって洗練。
- コンテキスト長:長文タスク向けに最大131,072トークンをサポート。
- 言語サポート:英語と中国語に優れ、その他の言語も追加サポート。
ベンチマーク
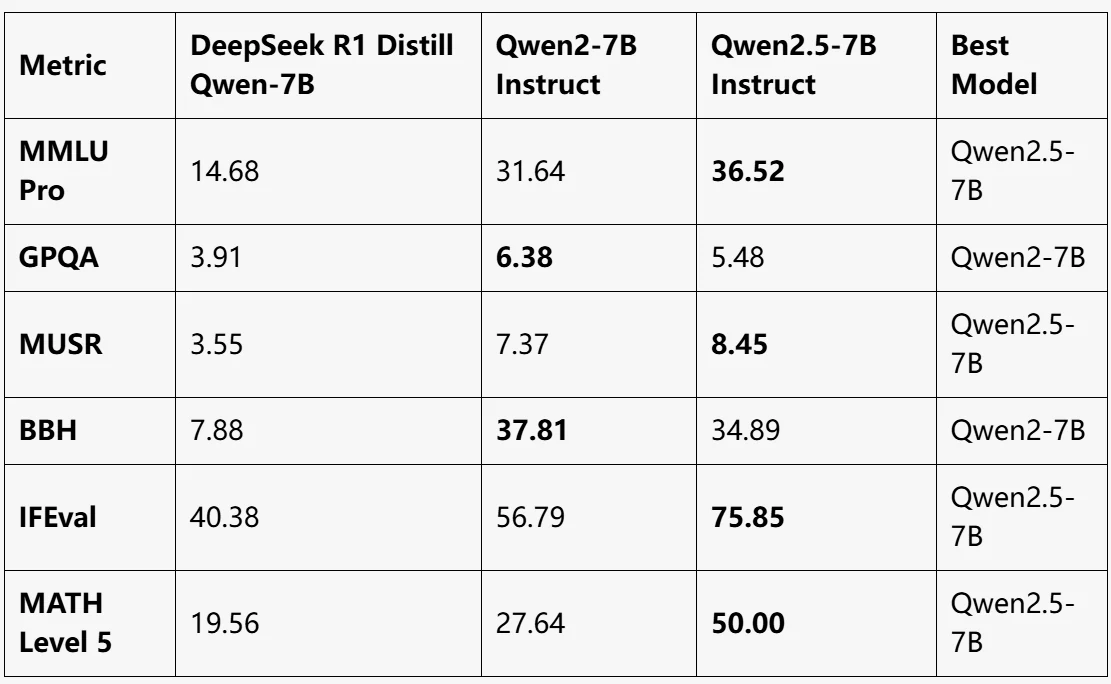
出典:LLM EXPLORER
Qwen2.5-7B Instruct:
- 全体的に最高のパフォーマンス。MMLU Pro、MUSR、IFEval、MATH Level 5 でトップ。
- 数学的推論が大幅に向上(MATH Level 5: 50)。
Qwen2-7B Instruct:
- GPQA と BBH で最高のパフォーマンス。
- バランスの取れたモデルだが、他のほとんどの指標ではQwen2.5-7Bにやや劣る。
DeepSeek R1 Distill Qwen-7B:
- すべてのベンチマークで最低のパフォーマンス。
- 軽量タスクには適しているが、複雑なベンチマークではQwen2モデルに大きく劣る。
他のQwenモデルとの比較
Qwen 2シリーズには、ベースモデルと指示チューニングモデルが5つのサイズで用意されています:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B、Qwen2-72B。以下にこれらのモデルの主な情報をまとめます。
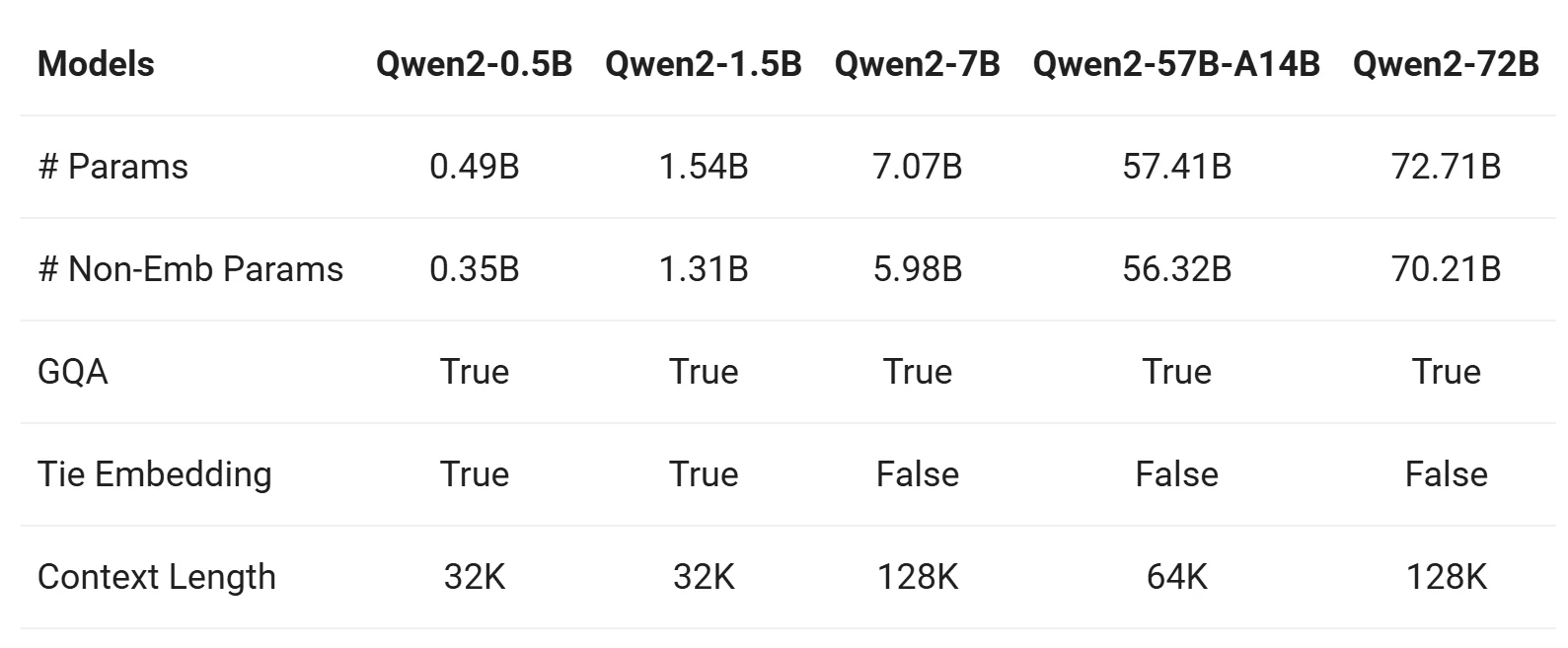
出典:Qwen
1. Group Query Attention (GQA)
- すべてのモデル(Qwen2-0.5B、Qwen2-7B、Qwen2-57B、Qwen2-72B)がGQAを採用し、以下を実現:
- 推論速度の高速化
- メモリ使用量の削減
- これはQwen1.5からの大幅な改善であり、Qwen1.5では大規模モデル(32Bと110B)のみGQAを使用していた。
2. コンテキスト長
- ベースモデル(Qwen2-0.5B、Qwen2-7B、Qwen2-57B、Qwen2-72B):
- 32Kトークンのコンテキスト長で事前学習。
- パープレキシティ(PPL)評価に基づき、最大128Kトークンまでの強い外挿能力を示す。
- 指示チューニングモデル(Qwen2-7B-Instruct、Qwen2-72B-Instruct):
- 「針山探し」などのタスクで評価。
- 長文タスクで非常に優れたパフォーマンスを発揮し、特にYARNで拡張した場合、最大128Kトークンまで能力を発揮。
3. 多言語対応
- すべてのモデル(Qwen2-0.5B、Qwen2-7B、Qwen2-57B、Qwen2-72B):
- 英語と中国語に加えて27言語を含む、改善された事前学習データセットの恩恵を受ける。
- 多言語パフォーマンスはモデルサイズとともに向上し、大規模モデル(Qwen2-57B、Qwen2-72B)はより複雑な多言語タスクで優れる。
Qwen 2.5 72Bなどの他のモデルとのより詳細なパラメータ比較については、以下の記事をご覧ください:Qwen 2.5 72b vs Llama 3.3 70b: あなたのニーズに合うモデルは? ; Qwen 2.5 vs Llama 3.2 90B: コード生成と画像推論能力の比較分析。
Qwen 2 7Bをローカルで利用する方法
GPU推奨
| **モデル ** | **VRAM容量 ** | ** メモリタイプ ** | ** 相対性能 ** | ** 価格帯** |
|---|---|---|---|---|
| NVIDIA RTX 4080 Super | 16 GB | GDDR6X | 高 | ⭐⭐⭐⭐⭐(ハイエンド) |
| AMD RX 7900 XTX | 24 GB | GDDR6 | 高 | ⭐⭐⭐⭐⭐(ハイエンド) |
| NVIDIA RTX 4070 Ti Super | 16 GB | GDDR6X | 中〜高 | ⭐⭐⭐⭐(アッパーミッド) |
| AMD RX 7600 XT | 16 GB | GDDR6 | 中 | ⭐⭐⭐(ミッド) |
| NVIDIA RTX 4060 Ti (16GB) | 16 GB | GDDR6 | 中 | ⭐⭐⭐(ミッド) |
クイックスタート
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # モデルをロードするデバイス
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Novita AI経由でQwen 2 7Bにアクセスする方法
ステップバイステップガイド
Novita AIは、シンプルなAPIを使ってAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドを開発者に提供します。
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションを閲覧し、ニーズに合ったモデルを選択します。
ステップ3:無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに移動し、画像のようにAPIキーをコピーします。

ステップ5:APIをインストール
使用するプログラミング言語に対応したパッケージマネージャーを使用してAPIをインストールします。

インストール後、開発環境に必要なライブラリをインポートします。APIキーを使ってAPIを初期化し、Novita AI LLMとの対話を開始します。以下は、Pythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen-2-7b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
登録時に、Novita AIは $0.5のクレジット を提供します!
無料クレジットを使い切った場合は、支払いをして継続利用できます。
あなたに適した方法は?
ローカル vs APIアクセスの比較
ローカルアクセス
利点:
- モデルとその設定をより細かく制御できる。
- YARN を活用してモデルの長さ外挿機能を強化し、長文の処理に適している。
- 継続的なコストがかからない。
欠点:
- 15.4 GBのVRAM を含む、かなりのハードウェアリソースが必要。
- セットアップと設定が複雑。
APIアクセス(例:Novita AI)
利点:
- ステップバイステップのガイドが提供され、セットアップと使用が簡単。
- ローカルのハードウェアリソースが不要。
欠点:
- インターネット接続が必要。
- トークンごとにコストがかかる:入力100万トークンあたり$0.054、** 出力100万トークンあたり$0.054**。
- モデルのカスタマイズと設定の制御が限られる。
異なるユーザーグループへの推奨
- 研究者: 実験の柔軟性と制御のために、一般的にローカルアクセスが好まれる。
- 開発者:
- APIアクセスは、アプリケーションの構築や迅速なプロトタイピングに適している。
- ローカルアクセスは、ファインチューニングやカスタムワークフローに適している。
- 企業: APIアクセスは、高い初期費用なしにサービスに迅速に統合できるため有益。一貫した要件がありインフラに投資できるチームには、ローカルデプロイが適している場合もある。
- 小規模チーム/個人: 初期費用が低いため、一般的にAPIアクセスの方が現実的。
- 技術スキルが限られているユーザー: APIアクセスは深い技術知識を必要としないため、好ましい。
Qwen 2-7B は、幅広いアプリケーション向けに設計された多用途で強力なモデルです。ローカルアクセスとAPIアクセスの両方をサポートしており、ユーザーは自分の特定のニーズ、利用可能なリソース、技術的専門知識に最も合ったオプションを選択できます。
よくある質問
Qwen2モデルの主なアーキテクチャ上の特徴は何ですか?
Qwen2モデルはトランスフォーマーベースのアーキテクチャを採用し、SwiGLU活性化、アテンションQKVバイアス、Grouped Query Attention (GQA) などの機能を備えています。
Qwen2モデルはどのようなコンテキスト長をサポートしていますか?
ベース言語モデルは32Kトークンのコンテキスト長で事前学習されており、一部のモデルはPPL評価で最大128Kトークンまでの外挿能力を示します。
Novita AI は、AIの野心を強化するオールインワンクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — コスト効率の高いツールを提供します。インフラストラクチャを排除し、無料で始めて、AIビジョンを現実にしましょう。



