

Techniques de parcimonie pour un gain de vitesse de 100x dans l’inférence des grands modèles de langage. Découvrez les secrets des techniques LLM-Pruner, qui doublent la vitesse d’inférence pour des résultats plus rapides.
Introduction
Il est bien connu que trois facteurs principaux affectent les performances des grands modèles de langage (LLM) sur GPU : (1) la puissance de calcul du GPU, (2) les entrées/sorties (E/S) du GPU, et (3) la taille de la mémoire GPU. Il est à noter que pour les LLM actuels, le facteur (2) est le principal goulot d’étranglement lors de la phase d’inférence.
Ce blog se concentre sur la faisabilité d’accélérer l’inférence des LLM sur des cartes graphiques grand public grâce à l’élagage (pruning) ou à la parcimonie (sparsity), en se basant sur les dernières recherches et pratiques d’ingénierie.
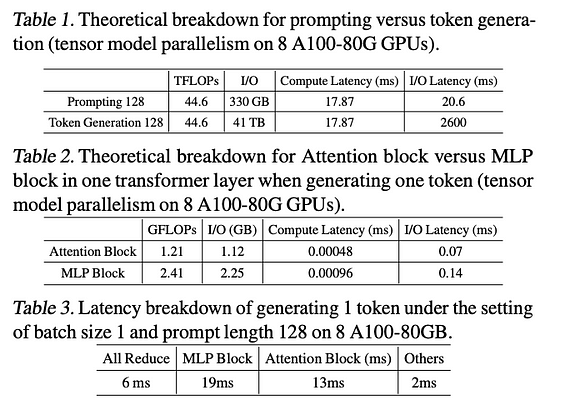
Tout d’abord, en se référant à l’analyse des métriques de latence d’inférence des LLM dans [1], les trois conclusions suivantes sont tirées :
- Dans les phases de prompting et de génération de tokens des LLM, la phase de génération de tokens prend beaucoup plus de temps en raison de la latence des E/S liée au chargement des paramètres du modèle.
- Dans l’inférence des LLM, les modules Attention et MLP sont tous deux des goulots d’étranglement, le module MLP représentant environ les deux tiers de la latence des E/S.
- La proportion d’All Reduce (communication entre GPU) est relativement faible, ce qui indique que la principale direction d’optimisation se situe dans l’architecture du transformer elle-même.
Pour des données détaillées, veuillez vous référer à la figure ci-dessous :
Pour améliorer l’efficacité de l’inférence, diverses techniques ont été explorées, notamment la quantification, le décodage d’inférence, la distillation et la parcimonie. Ce blog se concentre sur la parcimonie et en propose une introduction approfondie.
Introduction à la parcimonie
L’élagage de modèle, également connu sous le nom de parcimonie de modèle, diffère de la quantification de modèle : au lieu de compresser chaque paramètre de poids, les méthodes de parcimonie tentent de « supprimer » directement certains paramètres de poids. Le principe de l’élagage de modèle est de réduire le nombre de paramètres et la charge de calcul du modèle en éliminant les poids « non importants » tout en essayant de maintenir la précision du modèle.
L’article [17] introduit pour la première fois la méthode d’élagage des poids : tous les poids en dessous d’un certain seuil sont élagués, suivis d’un fine-tuning jusqu’à ce que la précision atteigne le niveau souhaité. Les auteurs de cet article ont mené des expériences sur LeNet, AlexNet et VGGNet pour vérifier l’efficacité de l’élagage.
Une autre conclusion concernant les régularisations L1 et L2 suggère que la régularisation L1 est plus performante sans fine-tuning, tandis que la régularisation L2 est plus performante avec fine-tuning. De plus, les couches antérieures du réseau sont plus sensibles à l’élagage, ce qui rend une approche d’élagage itérative préférable. Par ailleurs, sur la base d’expériences, les auteurs proposent l’hypothèse du ticket gagnant (Lottery Ticket).
L’hypothèse du ticket gagnant stipule que pour un réseau pré-entraîné, il existe un sous-réseau capable d’atteindre une précision similaire à celle du réseau original sans dépasser le nombre d’itérations d’entraînement du réseau original. Ce sous-réseau est comparable à un ticket gagnant.
Pour restaurer la précision du modèle, il est généralement nécessaire de ré-entraîner le modèle après l’élagage. Le pipeline typique en trois étapes pour l’élagage de modèle comprend les étapes d’entraînement, d’élagage et de fine-tuning, avec des changements dans la connectivité du réseau avant et après l’élagage, comme illustré dans la figure ci-dessous.
Par ailleurs, selon les objets pouvant être rendus parcimonieux dans les modèles d’apprentissage profond, la parcimonie dans les réseaux de neurones profonds inclut principalement la parcimonie des poids, la parcimonie des activations et la parcimonie des gradients.
Ce qui précède est une brève introduction à la parcimonie. Ensuite, nous partagerons en trois parties la proposition clé « Comment les LLM accélèrent l’inférence grâce à la parcimonie ». La première partie, « Comment les grands modèles élaguent », sera discutée. La deuxième partie couvrira « Comment accélérer l’inférence en utilisant la parcimonie des activations », et la troisième partie approfondira « L’impact des compilateurs de parcimonie sur l’inférence des LLM ».
Dans ce guide complet, nous explorerons la première partie, « Dévoilement des techniques LLM-Pruner : doubler la vitesse d’inférence », rédigée par Zachary de l’équipe novita.ai.
Comment les LLM sont élagués
Les LLM ont souvent des échelles de plusieurs centaines de milliards de paramètres, ce qui rend les méthodes conventionnelles de ré-entraînement ou d’élagage itératif impraticables. Par conséquent, des méthodes telles que l’élagage itératif et l’hypothèse du ticket gagnant [2,3] ne peuvent être appliquées qu’à des modèles de plus petite échelle.
L’élagage peut être efficacement appliqué aux tâches de vision et aux modèles de langage de plus petite échelle. Cependant, les méthodes d’élagage optimales nécessitent un ré-entraînement intensif du modèle pour récupérer la perte de précision causée par la suppression des éléments élagués. Par conséquent, lorsqu’on traite des modèles de l’échelle de GPT, le coût devient également prohibitif. Bien qu’il existe certaines méthodes d’élagage en un coup (one-shot) qui compressent les modèles sans nécessiter de ré-entraînement, leur coût de calcul est trop élevé pour être appliqué à des modèles avec des milliards de paramètres.
Récemment, des percées dans les techniques d’élagage pour les LLM ont eu lieu, qui seront discutées tour à tour dans ce blog.
SparseGPT
SparseGPT[12] est la première technique d’élagage précise en un coup dans le scénario des LLM qui peut fonctionner efficacement sur des modèles avec des échelles de 100 à 1000 milliards de paramètres. Le principe de fonctionnement de SparseGPT simplifie le problème d’élagage en une instance de régression parcimonieuse à grande échelle. Il repose sur de nouveaux solveurs de régression parcimonieuse approchée pour résoudre les problèmes de compression hiérarchique, et son efficacité est suffisante pour être exécutée sur le plus grand modèle GPT (175B paramètres) en utilisant un seul GPU en quelques heures. De plus, SparseGPT atteint une grande précision sans nécessiter de fine-tuning, et la perte de précision après élagage peut être négligeable. Par exemple, lorsqu’il est exécuté sur les plus grands modèles de langage génératif disponibles publiquement (OPT-175B et BLOOM-176B), SparseGPT atteint 50 à 60 % de parcimonie en test en un coup, avec une perte minimale de précision mesurée par la perplexité ou la précision des tests zero-shot.
Pour le code d’ingénierie, référez-vous au projet : https://github.com/IST-DASLab/sparsegpt
La figure 1 présente les résultats expérimentaux, mettant en évidence deux points clés : premièrement, comme le montre la figure 1 (gauche), SparseGPT est capable d’élaguer jusqu’à 60 % de parcimonie uniforme par couche dans les variantes de 175B paramètres de la famille OPT, avec une perte minimale de précision. En revanche, la seule référence en un coup connue fonctionnant à cette échelle — l’élagage par magnitude — ne maintient la précision qu’ jusqu’à 10 % de parcimonie et s’effondre complètement au-delà de 30 % de parcimonie.
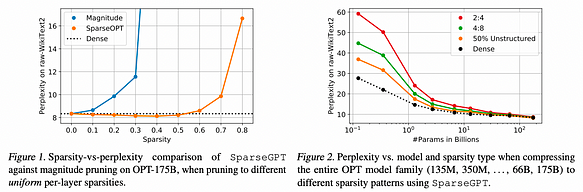
Deuxièmement, comme illustré dans la figure 2 (droite), SparseGPT peut également imposer avec précision la parcimonie dans des motifs de parcimonie semi-structurés 2:4 et 4:8 plus contraignants mais favorables au matériel. Bien que ces motifs entraînent souvent une perte de précision supplémentaire par rapport aux références denses, en particulier pour les petits modèles, les accélérations de calcul peuvent être directement déduites de ces motifs parcimonieux. De plus, la parcimonie induite par la technique peut bien se combiner avec une compression supplémentaire obtenue par quantification.
LLM-Pruner
LLM-Pruner[13] est une méthode d’élagage structuré qui supprime sélectivement les structures de couplage non essentielles en se basant sur les informations de gradient, maximisant la parcimonie tout en conservant la majeure partie de la fonctionnalité du LLM. LLM-Pruner, via LoRA, restaure efficacement les performances des modèles élagués avec seulement 3 heures et 50 000 données.
LLM-Pruner est le premier cadre conçu spécifiquement pour l’élagage structuré des LLM, avec les avantages résumés comme suit : (i) Compression indépendante de la tâche, où les modèles de langage compressés conservent leur capacité en tant que solveurs multitâches. (ii) Demande réduite en corpus d’entraînement originaux, la compression ne nécessitant que 50 000 échantillons disponibles publiquement, réduisant considérablement le budget pour l’acquisition de données d’entraînement. (iii) Compression rapide, le processus de compression étant achevé en trois heures. (iv) Cadre d’élagage structurel automatique, où toutes les dépendances structurelles sont regroupées sans nécessiter de conception manuelle.
Pour évaluer l’efficacité de LLM-Pruner, des expériences approfondies ont été menées sur trois grands modèles de langage : LLaMA-7B, Vicuna-7B et ChatGLM-6B. Les modèles compressés ont été évalués à l’aide de neuf ensembles de données pour évaluer la qualité de génération et les performances de classification zero-shot des modèles élagués.
En se référant au tableau ci-dessous, l’élagage de LLaMA-7B de 20 % à l’aide de LLM-Pruner avec 2,59 millions d’échantillons a entraîné une diminution minimale des performances du modèle mais une augmentation notable de 18 % de la vitesse d’inférence.

Résultats de LLM-Pruner avec 2,59 millions d’échantillons
Wanda
Wanda[14], une méthode d’élagage basée sur les poids et les activations, est une approche nouvelle, simple et efficace visant à induire de la parcimonie dans les LLM pré-entraînés. Inspirée par des observations récentes de caractéristiques de grande valeur dans les LLM, Wanda élagage les poids en multipliant chaque sortie par l’activation d’entrée correspondante par la valeur quantifiée minimale. Notamment, Wanda ne nécessite pas de ré-entraînement ni de mise à jour des poids, et les LLM élagués peuvent être utilisés tels quels. L’évaluation de Wanda sur LLaMA et LLaMA-2 valide sa supériorité par rapport aux références établies d’élagage par magnitude, démontrant sa compétitivité par rapport aux méthodes récentes impliquant des mises à jour denses des poids.
Pour le code d’ingénierie, référez-vous au projet : https://github.com/locuslab/wanda
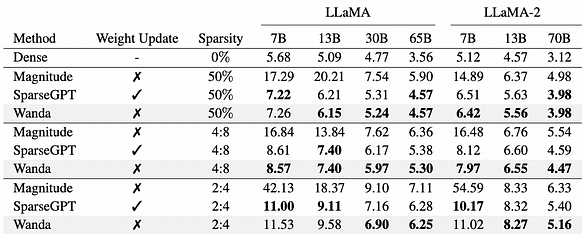
Perplexité Wikitext des modèles LLaMA et LLaMA-2 élagués. Wanda obtient des performances compétitives par rapport à la meilleure méthode antérieure SparseGPT, sans introduire de mise à jour de poids.
En se référant à la figure ci-dessus, Wanda et SparseGPT démontrent des performances comparables dans l’élagage de modèles.
Inconvénients des méthodes d’élagage conventionnelles
- Support matériel : Il est difficile d’obtenir une accélération du temps d’horloge grâce à la parcimonie non structurée en raison des difficultés connues avec le matériel moderne. Par exemple, des développements récents comme SparseGPT ont atteint 60 % de parcimonie non structurée grâce à un élagage en un coup, mais n’ont entraîné aucun effet d’accélération significatif du temps d’horloge.
- Défis de déploiement : Répondre à des exigences spécifiques grâce à la parcimonie de modèle dans des contextes comme l’apprentissage en contexte (In-Context Learning) présente des défis. Bien que de nombreux travaux aient démontré l’efficacité d’un élagage spécifique à une tâche, maintenir différents modèles pour chaque tâche entre en conflit avec le positionnement même du LLM, posant des obstacles au déploiement.
Conclusion
En résumé, des méthodes d’élagage innovantes telles que SparseGPT, LLM-Pruner et Wanda offrent de nouvelles perspectives et moyens techniques pour élaguer les grands modèles tout en maintenant des performances élevées. Cependant, des recherches et explorations supplémentaires sont encore nécessaires pour relever les défis du support matériel et des applications pratiques. Dans le prochain article de blog, nous explorerons la deuxième partie : « Comment accélérer l’inférence en utilisant la parcimonie des activations. »
Références
[1]Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
[4]The Hardware Lottery
[6]Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale
[12]SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot
[13]LLM-Pruner: On the Structural Pruning of Large Language Models
[14]A Simple and Effective Pruning Approach for Large Language Models
[17]Learning both Weights and Connections for Efficient Neural Networks
novita.ai fournit une API Stable Diffusion et des centaines d’API de génération d’images IA rapides et économiques pour 10 000 modèles. 🎯 Génération la plus rapide en seulement 2s, paiement à l’utilisation, à partir de 0,0015 $ par image standard, vous pouvez ajouter vos propres modèles et éviter la maintenance GPU. Partage gratuit des extensions open source.
Lectures recommandées



