

大语言模型推理中实现100倍加速的稀疏技术。探索LLM剪枝技术背后的奥秘,将推理速度提升一倍以获得更快的结果。
引言
众所周知,影响大语言模型(LLM)在GPU上性能的核心因素有三个:(1) GPU计算能力,(2) GPU输入/输出 (I/O),(3) GPU内存大小。值得注意的是,对于当今的LLM而言,在推理阶段,因素(2)是主要瓶颈。
本篇博客基于最新的研究论文和工程实践,重点探讨在消费级显卡上通过剪枝或稀疏性来加速LLM推理的可行性。
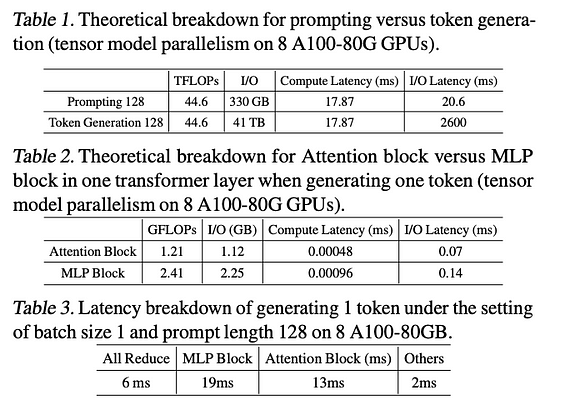
首先,参考 [1] 中对LLM推理延迟指标的分析,得出以下三个结论:
- 在LLM的提示(Prompting)和令牌生成(Token Generation)阶段,由于加载模型参数而产生的I/O延迟,令牌生成阶段耗时更长。
- 在LLM推理中,Attention和MLP模块都是瓶颈,其中MLP模块约占I/O延迟的三分之二。
- All Reduce(GPU间通信)的占比相对较低,说明主要优化方向在于Transformer架构本身。
详细数据请参考下图:
为了提高推理效率,研究人员探索了多种技术,包括量化、推理解码、知识蒸馏和稀疏化。本篇博客专注于稀疏化,并进行深入介绍。
稀疏化简介
模型剪枝,也称为模型稀疏化,与模型量化的不同之处在于,它并非压缩每个权重参数,而是尝试直接“移除”某些权重参数。模型剪枝的原理是通过消除“不重要”的权重来减少模型中的参数数量和计算量,同时尽量保持模型的准确率。
论文 [17] 首次介绍了权重剪枝的方法:将所有低于某个阈值的权重剪掉,然后进行微调,直到准确率达到预期水平。该论文的作者在LeNet、AlexNet和VGGNet上进行了实验,验证了剪枝的有效性。
关于L1和L2正则化的另一个结论是:在不进行微调的情况下,L1正则化表现更好;而在进行微调的情况下,L2正则化表现更好。此外,网络中较早的层对剪枝更敏感,因此采用迭代剪枝方法更为合适。基于实验,作者还提出了“彩票假设”(Lottery Ticket Hypothesis)。
彩票假设指出:对于一个预训练网络,存在一个子网络,能够在不超过原始网络训练轮次的情况下达到与原始网络相似的准确率。这个子网络就像是中了彩票一样。
为了恢复模型准确率,通常需要在剪枝后重新训练模型。模型剪枝的典型三阶段流程包括训练、剪枝和微调步骤,剪枝前后网络连接的变化如下图所示。
同时,根据深度学习模型中可以被稀疏化的对象,深度神经网络中的稀疏化主要包括权重稀疏化、激活稀疏化和梯度稀疏化。
以上是对稀疏化的简要介绍。接下来,我们将分三个部分来分享核心命题“LLM如何通过稀疏化加速推理”。第一部分将讨论“大模型如何剪枝”。第二部分将涵盖“如何利用激活稀疏化加速推理”,第三部分将深入探讨“稀疏化编译器对LLM推理的影响”。
在本综合指南中,我们将探索第一部分——“揭秘LLM剪枝技术:推理速度翻倍”,由novita.ai团队的Zachary撰写。
大语言模型如何剪枝
LLM通常具有数千亿参数的规模,这使得传统的重新训练或迭代剪枝方法变得不切实际。因此,迭代剪枝和彩票假设 [2,3] 等方法只能应用于较小规模的模型。
剪枝可以有效地应用于视觉和较小规模的语言模型及任务。然而,最优的剪枝方法需要对模型进行大量重新训练,以恢复因移除剪枝元素而造成的准确率损失。因此,当处理GPT规模级别的模型时,成本也变得高得令人望而却步。虽然存在一些一次性剪枝方法可以在无需重新训练的情况下压缩模型,但其计算成本过高,无法应用于数十亿参数的模型。
最近,针对LLM的剪枝技术取得了突破性进展,本篇博客将逐一讨论。
SparseGPT
SparseGPT [12] 是LLM场景中第一个一次性精确剪枝技术,能够有效地处理1000亿到10000亿参数规模的模型。SparseGPT的工作原理是将剪枝问题简化为一个大规模稀疏回归实例。它基于新的近似稀疏回归求解器来解决层次压缩问题,其效率足以在单个GPU上几小时内执行最大的GPT模型(175B参数)。此外,SparseGPT无需任何微调即可实现高准确率,剪枝后的准确率损失可以忽略不计。例如,在最大的公开可用生成式语言模型(OPT-175B和BLOOM-176B)上执行时,SparseGPT在一次测试中实现了50-60%的稀疏度,而通过困惑度或零样本测试准确率衡量的准确率损失极小。
工程代码请参考项目:https://github.com/IST-DASLab/sparsegpt
图1展示了实验结果,突出了两个关键点:首先,如图1(左)所示,SparseGPT能够在OPT系列的175B参数变体上剪枝高达60%的均匀层稀疏度,且准确率损失极小。相比之下,唯一已知的在此规模下有效的一次性基线方法——幅度剪枝(Magnitude Pruning)——仅在稀疏度达到10%时能保持准确率,超过30%稀疏度时则完全崩溃。
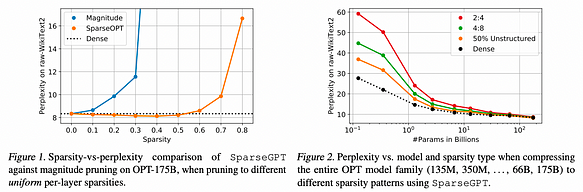
其次,如图2(右)所示,SparseGPT也能在更严格但硬件友好的2:4和4:8半结构化稀疏模式下精确地施加稀疏性。虽然这些模式相比于密集基线通常会导致额外的准确率损失(尤其是对于较小的模型),但计算加速可以直接从这些稀疏模式中推断出来。此外,该技术产生的稀疏性可以与通过量化获得的额外压缩很好地结合。
LLM-Pruner
LLM-Pruner [13] 是一种结构化剪枝方法,它基于梯度信息选择性地移除非必要的耦合结构,在最大化稀疏度的同时保留LLM的大部分功能。LLM-Pruner通过LoRA,仅需3小时和50K数据即可高效恢复剪枝模型的性能。
LLM-Pruner是首个专门为LLM结构化剪枝设计的框架,其优势总结如下:(i) 任务无关压缩,压缩后的语言模型保留了作为多任务求解器的能力。(ii) 对原始训练语料库的需求降低,压缩仅需5万个公开可用样本,显著减少了获取训练数据的预算。(iii) 快速压缩,压缩过程在三小时内完成。(iv) 自动结构化剪枝框架,所有结构依赖关系自动分组,无需任何手动设计。
为了评估LLM-Pruner的有效性,在三个大规模语言模型(LLaMA-7B、Vicuna-7B和ChatGLM-6B)上进行了大量实验。使用九个数据集评估压缩模型的生成质量和零样本分类性能。
参考下表,使用LLM-Pruner对LLaMA-7B进行20%剪枝,使用259万个样本,模型性能下降极小,但推理速度显著提升了18%。

使用259万样本的LLM-Pruner结果
Wanda
Wanda [14],一种基于权重和激活的剪枝方法,是一种新颖、简单且有效的方法,旨在为预训练LLM引入稀疏性。受近期关于LLM中显著特征值观察的启发,Wanda通过将每个输出与对应的输入激活乘以最小量化值来剪枝权重。值得注意的是,Wanda不需要重新训练或权重更新,剪枝后的LLM可以直接使用。在LLaMA和LLaMA-2上对Wanda的评估验证了其相对于已有幅度剪枝基线的优越性,并显示出与最近涉及密集权重更新的方法相比具有竞争力。
工程代码请参考项目:https://github.com/locuslab/wanda
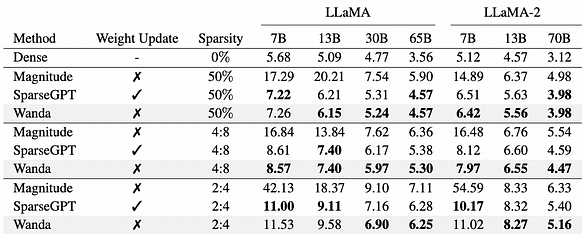
剪枝后的LLaMA和LLaMA-2模型在WikiText上的困惑度。Wanda与先前最佳方法SparseGPT相比表现出色,且无需任何权重更新。
参考上图,Wanda和SparseGPT在模型剪枝方面表现出相当的性能。
传统剪枝方法的缺点
- 硬件支持:由于现代硬件存在已知困难,通过非结构化稀疏性实现时钟时间加速颇具挑战。例如,最近的进展如SparseGPT已通过一次性剪枝实现了60%的非结构化稀疏性,但并未带来任何显著的时钟时间加速效果。
- 部署挑战:在上下文学习等场景中通过模型稀疏性满足特定要求存在困难。虽然许多工作已证明任务特定剪枝的有效性,但为每个任务维护不同的模型与LLM本身的定位相冲突,带来了部署障碍。
结论
总之,创新的剪枝方法如SparseGPT、LLM-Pruner和Wanda为在保持高性能的同时剪枝大模型提供了新的视角和技术手段。然而,在硬件支持和实际应用方面仍需进一步研究和探索。在下一篇博文中,我们将探讨第二部分:“如何利用激活稀疏化加速推理”。
参考文献
[1] Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
[4] The Hardware Lottery
[6] Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale
[12] SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot
[13] LLM-Pruner: On the Structural Pruning of Large Language Models
[14] A Simple and Effective Pruning Approach for Large Language Models
[17] Learning both Weights and Connections for Efficient Neural Networks
novita.ai 提供Stable Diffusion API以及数百种快速且成本最低的AI图像生成API,涵盖10,000个模型。🎯 最快2秒生成,按量付费,每张标准图像最低0.0015美元,您还可以添加自己的模型并免去GPU维护。免费分享开源扩展。
推荐阅读



