

Разреженные техники для 100-кратного ускорения инференса больших языковых моделей. Изучите секреты методов LLM-Pruner, удваивающих скорость инференса для более быстрых результатов.
Введение
Хорошо известно, что на производительность больших языковых моделей (LLM) на GPU влияют три основных фактора: (1) вычислительная мощность GPU, (2) ввод/вывод (I/O) GPU и (3) объем памяти GPU. Стоит отметить, что для современных LLM фактор (2) является основным узким местом на этапе инференса.
Этот блог посвящен возможности ускорения инференса LLM на потребительских видеокартах с помощью прореживания или разреженности, основанной на последних научных исследованиях и инженерных практиках.
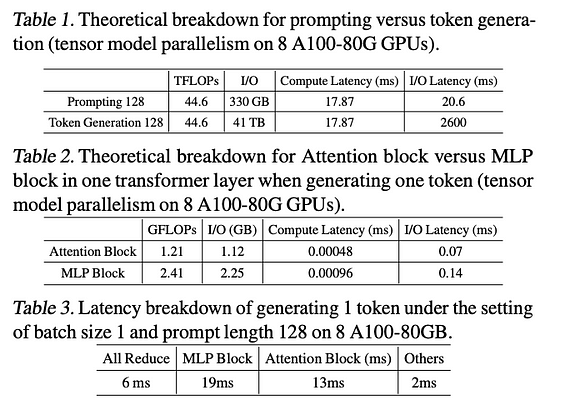
Во-первых, обращаясь к анализу метрик задержки инференса LLM в [1], можно сделать следующие три вывода:
- На этапах промптинга и генерации токенов LLM этап генерации токенов занимает гораздо больше времени из-за задержек I/O, связанных с загрузкой параметров модели.
- В инференсе LLM модули Attention и MLP являются узкими местами, причем модуль MLP составляет около двух третей задержки I/O.
- Доля All Reduce (связь между GPU) относительно невелика, что указывает на то, что основное направление оптимизации лежит в самой архитектуре трансформера.
Подробные данные представлены на рисунке ниже:
Для повышения эффективности инференса были исследованы различные техники, включая квантизацию, декодирование инференса, дистилляцию и разреженность. Этот блог фокусируется на разреженности и дает подробное введение.
Введение в разреженность.
Прореживание модели, также известное как разреженность модели, отличается от квантизации модели тем, что вместо сжатия каждого весового параметра методы разреженности пытаются напрямую «удалить» некоторые весовые параметры. Принцип прореживания модели заключается в уменьшении количества параметров и вычислительной нагрузки в модели путем устранения «неважных» весов, при этом сохраняя точность модели.
В статье [17] впервые представлен метод прореживания весов: все веса ниже определенного порога отсекаются, после чего следует дообучение до достижения желаемой точности. Авторы этой статьи провели эксперименты на LeNet, AlexNet и VGGNet для проверки эффективности прореживания.
Еще один вывод относительно L1- и L2-регуляризации: L1-регуляризация показывает лучшие результаты без дообучения, тогда как L2-регуляризация лучше работает с дообучением. Кроме того, ранние слои сети более чувствительны к прореживанию, что делает итеративный подход к прореживанию предпочтительным. На основе экспериментов авторы выдвигают гипотезу лотерейного билета.
Гипотеза лотерейного билета гласит: для предобученной сети существует подсеть, которая может достичь точности, сопоставимой с исходной сетью, не превышая количество эпох обучения исходной сети. Эта подсеть подобна выигрышному лотерейному билету.
Для восстановления точности модели обычно требуется переобучение модели после прореживания. Типичный трехэтапный конвейер прореживания модели состоит из этапов обучения, прореживания и дообучения, при этом сетевая связность меняется до и после прореживания, как показано на рисунке ниже.
Между тем, согласно объектам, которые могут быть разрежены в моделях глубокого обучения, разреженность в глубоких нейронных сетях в основном включает разреженность весов, разреженность активаций и разреженность градиентов.
Выше представлено краткое введение в разреженность. Далее мы поделимся в трех частях ключевым утверждением «Как LLM ускоряет инференс с помощью разреженности». Первая часть, «Как прореживаются большие модели», будет рассмотрена. Вторая часть охватит «Как ускорить инференс с помощью разреженности активаций», а третья часть углубится в «Влияние компиляторов разреженности на инференс LLM».
В этом всеобъемлющем руководстве мы рассмотрим первую часть, «Раскрываем техники LLM-Pruner: удвоение скорости инференса», автором которой является Захари из команды novita.ai.
Как прореживаются LLM
LLM часто имеют масштабы в сотни миллиардов параметров, что делает традиционные методы переобучения или итеративного прореживания непрактичными. Поэтому такие методы, как итеративное прореживание и гипотеза лотерейного билета [2,3], могут применяться только к моделям меньшего масштаба.
Прореживание может быть эффективно применено к задачам компьютерного зрения и моделям языка меньшего масштаба. Однако оптимальные методы прореживания требуют обширного переобучения модели для восстановления точности, потерянной из-за удаления прореженных элементов. Поэтому при работе с моделями масштаба GPT стоимость также становится непомерно высокой. Хотя существуют некоторые одношаговые методы прореживания, которые сжимают модели без необходимости переобучения, их вычислительная стоимость слишком высока для применения к моделям с миллиардами параметров.
Недавно были достигнуты прорывы в техниках прореживания для LLM, которые будут последовательно рассмотрены в этом блоге.
SparseGPT
SparseGPT[12] — это первая одношаговая точная техника прореживания в сценарии LLM, которая может эффективно работать с моделями масштаба 100–1000 миллиардов параметров. Принцип работы SparseGPT сводит задачу прореживания к крупномасштабному разреженному регрессионному экземпляру. Он основан на новых приближенных решателях разреженной регрессии для решения иерархических задач сжатия, и его эффективность достаточна для выполнения на самой большой модели GPT (175B параметров) с использованием одного GPU в течение нескольких часов. Кроме того, SparseGPT достигает высокой точности без необходимости дообучения, и потеря точности после прореживания может быть незначительной. Например, при выполнении на самых больших публично доступных генеративных языковых моделях (OPT-175B и BLOOM-176B) SparseGPT достигает разреженности 50–60% в одношаговом тестировании с минимальной потерей точности, измеряемой по перплексии или точности в zero-shot тестах.
Для инженерного кода обращайтесь к проекту: https://github.com/IST-DASLab/sparsegpt
На рисунке 1 представлены результаты экспериментов, подчеркивающие два ключевых момента: во-первых, как показано на рисунке 1 (слева), SparseGPT способен проредить до 60% равномерной разреженности по слоям в вариантах семейства OPT с 175B параметров с минимальной потерей точности. В отличие от этого, единственный известный одношаговый базовый метод, работающий в этом масштабе — Magnitude Pruning — сохраняет точность только до 10% разреженности и полностью рушится при превышении 30% разреженности.
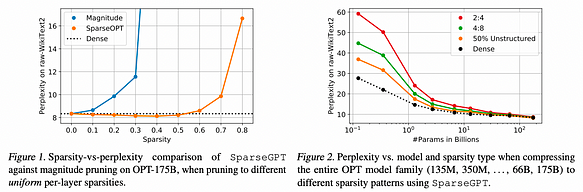
Во-вторых, как показано на рисунке 2 (справа), SparseGPT также может точно обеспечивать разреженность в более строгих, но аппаратно-дружественных полуструктурированных разреженных шаблонах 2:4 и 4:8. Хотя эти шаблоны часто связаны с дополнительной потерей точности по сравнению с плотными базовыми линиями, особенно для меньших моделей, вычислительное ускорение может быть непосредственно получено из этих разреженных шаблонов. Кроме того, разреженность, создаваемая этой техникой, хорошо сочетается с дополнительным сжатием, получаемым через квантизацию.
LLM-Pruner
LLM-Pruner[13] — это структурированный метод прореживания, который выборочно удаляет несущественные связующие структуры на основе градиентной информации, максимизируя разреженность при сохранении большей части функциональности LLM. LLM-Pruner с помощью LoRA эффективно восстанавливает производительность прореженных моделей всего за 3 часа и 50K данных.
LLM-Pruner — это первый фреймворк, разработанный специально для структурированного прореживания LLM, с преимуществами, обобщенными следующим образом: (i) Независимое от задачи сжатие: сжатые языковые модели сохраняют способность решать множество задач. (ii) Снижение потребности в исходном обучающем корпусе: для сжатия требуется всего 50 000 публично доступных образцов, что значительно снижает бюджет на получение обучающих данных. (iii) Быстрое сжатие: процесс сжатия завершается в течение трех часов. (iv) Автоматический фреймворк структурированного прореживания: все структурные зависимости группируются без необходимости какого-либо ручного проектирования.
Для оценки эффективности LLM-Pruner были проведены обширные эксперименты на трех крупномасштабных языковых моделях: LLaMA-7B, Vicuna-7B и ChatGLM-6B. Сжатые модели оценивались на девяти наборах данных для оценки качества генерации и производительности zero-shot классификации прореженных моделей.
Ссылаясь на таблицу ниже, прореживание LLaMA-7B на 20% с помощью LLM-Pruner с использованием 2,59 миллионов образцов привело к минимальному снижению производительности модели, но заметному увеличению скорости инференса на 18%.

Результаты LLM-Pruner с 2,59M образцов
Wanda
Wanda[14], метод прореживания на основе весов и активаций, представляет собой новый, простой и эффективный подход, направленный на обеспечение разреженности в предобученных LLM. Вдохновленный недавними наблюдениями значительных по значению признаков в LLM, Wanda прореживает веса путем умножения каждого выхода на соответствующий входной активационный минимум квантизованного значения. Примечательно, что Wanda не требует переобучения или обновления весов, и прореженные LLM могут использоваться как есть. Оценка Wanda на LLaMA и LLaMA-2 подтверждает ее превосходство над установленными базовыми методами прореживания по величине, демонстрируя конкурентоспособность по сравнению с недавними методами, включающими плотные обновления весов.
Для инженерного кода обращайтесь к проекту: https://github.com/locuslab/wanda
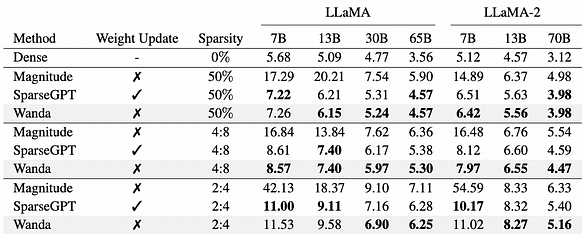
Перплексия WikiText прореженных моделей LLaMA и LLaMA-2. Wanda показывает конкурентоспособные результаты по сравнению с предыдущим лучшим методом SparseGPT, не вводя никаких обновлений весов.
Ссылаясь на рисунок выше, Wanda и SparseGPT демонстрируют сопоставимую производительность в прореживании моделей.
Недостатки обычных методов прореживания:
- Аппаратная поддержка: Достижение ускорения по тактовому времени через неструктурированную разреженность затруднительно из-за известных проблем с современным оборудованием. Например, недавние разработки, такие как SparseGPT, достигли 60% неструктурированной разреженности через одношаговое прореживание, но не привели к значительным эффектам ускорения по тактовому времени.
- Проблемы развертывания: Удовлетворение конкретных требований через разреженность модели в контекстах, таких как In-Context Learning, представляет собой вызовы. Хотя многие работы продемонстрировали эффективность прореживания под конкретные задачи, поддержание разных моделей для каждой задачи противоречит позиционированию самой LLM, создавая препятствия для развертывания.
Заключение:
Таким образом, инновационные методы прореживания, такие как SparseGPT, LLM-Pruner и Wanda, предлагают новые перспективы и технические средства для прореживания больших моделей при сохранении высокой производительности. Однако для решения проблем аппаратной поддержки и практического применения все еще необходимы дальнейшие исследования и изыскания. В следующей записи блога мы рассмотрим вторую часть: «Как ускорить инференс с помощью разреженности активаций».
Справочные статьи
[1] Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
[4] The Hardware Lottery
[6] Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale
[12] SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot
[13] LLM-Pruner: On the Structural Pruning of Large Language Models
[14] A Simple and Effective Pruning Approach for Large Language Models
[17] Learning both Weights and Connections for Efficient Neural Networks
novita.ai предоставляет API Stable Diffusion и сотни быстрых и самых дешевых API генерации изображений на основе ИИ для 10 000 моделей. 🎯 Самая быстрая генерация всего за 2 секунды, оплата по мере использования, минимум $0,0015 за каждое стандартное изображение, вы можете добавлять свои модели и избегать обслуживания GPU. Бесплатно делитесь расширениями с открытым исходным кодом.
Рекомендуемое чтение



