

تقنيات التسريع بمقدار 100 ضعف في استدلال النماذج اللغوية الكبيرة. استكشف الأسرار وراء تقنيات LLM-Pruner، مضاعفة سرعة الاستدلال للحصول على نتائج أسرع.
مقدمة
من المعروف أن هناك ثلاثة عوامل أساسية تؤثر على أداء النماذج اللغوية الكبيرة (LLM) على وحدات معالجة الرسوميات (GPU): (1) قوة الحوسبة لوحدة GPU، (2) الإدخال/الإخراج (I/O) لوحدة GPU، (3) حجم ذاكرة GPU. الجدير بالذكر أنه بالنسبة لنماذج LLM الحالية، فإن العامل (2) هو الاختناق الرئيسي خلال مرحلة الاستدلال.
تركز هذه المدونة على جدوى تسريع استدلال LLM على بطاقات الرسوميات الاستهلاكية من خلال التقليم أو التشتت، استنادًا إلى أحدث الأوراق البحثية والممارسات الهندسية.
أولاً، بالإشارة إلى تحليل مقاييس زمن استجابة استدلال LLM في [1]، تم استخلاص الاستنتاجات الثلاثة التالية:
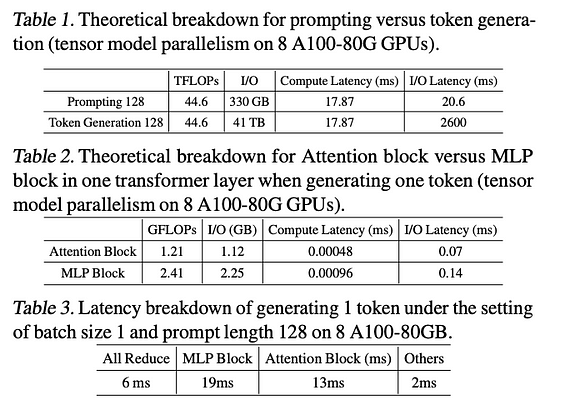
- في مرحلتي التوجيه وتوليد الرموز في LLM، تستغرق مرحلة توليد الرموز وقتًا أطول بكثير بسبب زمن انتقال I/O الناتج عن تحميل معلمات النموذج.
- في استدلال LLM، تعتبر كل من وحدات الانتباه (Attention) وMLP اختناقات، حيث تمثل وحدة MLP حوالي ثلثي زمن انتقال I/O.
- نسبة الاتصال الشامل (All Reduce) (التواصل بين وحدات GPU) منخفضة نسبيًا، مما يشير إلى أن اتجاه التحسين الرئيسي يكمن في بنية المحول (Transformer) نفسها.
للحصول على بيانات مفصلة، يرجى الرجوع إلى الشكل أدناه:
لتحسين كفاءة الاستدلال، تم استكشاف تقنيات مختلفة، بما في ذلك التكميم، وفك تشفير الاستدلال، والتقطير، والتشتت. تركز هذه المدونة على التشتت وتقدم مقدمة متعمقة.
مقدمة عن التشتت.
تقليم النموذج، المعروف أيضًا باسم تشتت النموذج، يختلف عن تكميم النموذج حيث بدلاً من ضغط كل معلمة وزن، تحاول طرق التشتت “إزالة” بعض معلمات الوزن مباشرة. مبدأ تقليم النموذج هو تقليل عدد المعلمات والحمل الحسابي في النموذج عن طريق إزالة الأوزان “غير المهمة” مع محاولة الحفاظ على دقة النموذج.
تقدم الورقة [17] أولاً طريقة تقليم الوزن: يتم تقليم جميع الأوزان التي تقل عن حد معين، ثم يتم الضبط الدقيق حتى تصل الدقة إلى المستوى المطلوب. قام مؤلفو هذه الورقة بإجراء تجارب على LeNet وAlexNet وVGGNet للتحقق من فعالية التقليم.
استنتاج آخر بخصوص التنظيم L1 وL2 يشير إلى أن تنظيم L1 يعمل بشكل أفضل بدون ضبط دقيق، بينما يعمل تنظيم L2 بشكل أفضل مع الضبط الدقيق. بالإضافة إلى ذلك، فإن الطبقات السابقة في الشبكة أكثر حساسية للتقليم، مما يجعل نهج التقليم التكراري مفضلًا. علاوة على ذلك، بناءً على التجارب، يقترح المؤلفون فرضية تذكرة اليانصيب (Lottery Ticket).
تنص فرضية تذكرة اليانصيب على أنه بالنسبة لشبكة مدربة مسبقًا، يوجد شبكة فرعية يمكنها تحقيق دقة مماثلة للشبكة الأصلية دون تجاوز جولات التدريب الخاصة بالشبكة الأصلية. هذه الشبكة الفرعية تشبه الفوز بتذكرة يانصيب.
لاستعادة دقة النموذج، من الضروري عادةً إعادة تدريب النموذج بعد التقليم. يتكون المسار النموذجي ثلاثي المراحل لتقليم النموذج من خطوات التدريب والتقليم والضبط الدقيق، مع تغييرات في اتصال الشبكة قبل وبعد التقليم، كما هو موضح في الشكل أدناه.
وفي الوقت نفسه، وفقًا للأشياء التي يمكن تشتيتها في نماذج التعلم العميق، فإن التشتت في الشبكات العصبية العميقة يشمل بشكل أساسي تشتت الوزن، وتشتت التنشيط، وتشتت التدرج.
ما سبق هو مقدمة موجزة عن التشتت. بعد ذلك، سنشارك في ثلاثة أجزاء الاقتراح الرئيسي “كيف يسرع LLM الاستدلال من خلال التشتت”. سيتم مناقشة الجزء الأول، “كيف تقوم النماذج الكبيرة بالتقليم”. سيغطي الجزء الثاني “كيفية تسريع الاستدلال باستخدام تشتت التنشيط”، وسيتناول الجزء الثالث “تأثير مترجمات التشتت على استدلال LLM”.
في هذا الدليل الشامل، سنستكشف الجزء الأول، “كشف تقنيات LLM-Pruner: مضاعفة سرعة الاستدلال”، من تأليف Zachary من فريق novita.ai.
كيف يتم تقليم LLM
غالبًا ما تحتوي نماذج LLM على مقاييس تصل إلى مئات المليارات من المعلمات، مما يجعل طرق إعادة التدريب التقليدية أو التقليم التكراري غير عملية. لذلك، يمكن تطبيق طرق مثل التقليم التكراري وفرضية اليانصيب [2,3] فقط على النماذج صغيرة الحجم.
يمكن تطبيق التقليم بفعالية على نماذج الرؤية والنماذج اللغوية صغيرة الحجم والمهام. ومع ذلك، تتطلب طرق التقليم المثلى إعادة تدريب مكثفة للنموذج لاستعادة فقدان الدقة الناتج عن إزالة العناصر المقلمة. لذلك، عند التعامل مع نماذج بحجم GPT، تصبح التكلفة أيضًا مرتفعة بشكل غير مقبول. بينما توجد بعض طرق التقليم لمرة واحدة (one-shot) التي تضغط النماذج دون الحاجة إلى إعادة التدريب، إلا أن تكلفتها الحسابية مرتفعة جدًا بحيث لا يمكن تطبيقها على نماذج تحتوي على مليارات من المعلمات.
مؤخرًا، حدثت تطورات في تقنيات التقليم لنماذج LLM، والتي سيتم مناقشتها بدورها في هذه المدونة.
SparseGPT
SparseGPT[12] هي أول تقنية تقليم دقيقة لمرة واحدة في سيناريو LLM يمكنها العمل بفعالية على نماذج بمقاييس 100-1000 مليار معلمة. مبدأ عمل SparseGPT يبسط مشكلة التقليم إلى مثال انحدار متفرق على نطاق واسع. يعتمد على محللات انحدار متفرقة تقريبية جديدة لحل مشكلات الضغط الهرمي، وكفاءتها كافية لتشغيلها على أكبر نموذج GPT (175 مليار معلمة) باستخدام GPU واحد في غضون ساعات. بالإضافة إلى ذلك، تحقق SparseGPT دقة عالية دون الحاجة إلى أي ضبط دقيق، ويمكن أن يكون فقدان الدقة بعد التقليم ضئيلًا. على سبيل المثال، عند تنفيذها على أكبر نماذج اللغة التوليدية المتاحة للجمهور (OPT-175B وBLOOM-176B)، تحقق SparseGPT تشتتًا بنسبة 50-60٪ في اختبار لمرة واحدة، مع فقدان ضئيل في الدقة يُقاس بالحيرة (perplexity) أو دقة اختبار الصفر-shot.
للاطلاع على الكود الهندسي، راجع المشروع: https://github.com/IST-DASLab/sparsegpt
يعرض الشكل 1 النتائج التجريبية، مسلطًا الضوء على نقطتين رئيسيتين: أولاً، كما هو موضح في الشكل 1 (يسار)، فإن SparseGPT قادرة على تقليم ما يصل إلى 60٪ من التشتت المنتظم لكل طبقة في متغيرات 175 مليار معلمة من عائلة OPT، مع فقدان ضئيل في الدقة. في المقابل، فإن خط الأساس الوحيد المعروف الذي يعمل بهذا المقياس - تقليم المقدار (Magnitude Pruning) - يحافظ على الدقة فقط حتى تشتت بنسبة 10٪ وينهار تمامًا بعد تشتت بنسبة 30٪.
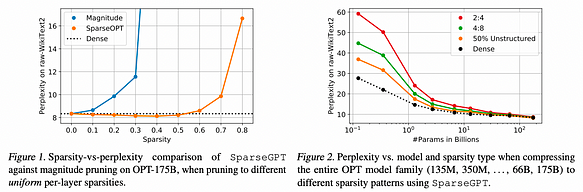
ثانيًا، كما هو موضح في الشكل 2 (يمين)، يمكن لـ SparseGPT أيضًا فرض التشتت بدقة في أنماط التشتت شبه المنظمة 2:4 و4:8 الأكثر صرامة ولكنها صديقة للأجهزة. في حين أن هذه الأنماط غالبًا ما تستلزم فقدانًا إضافيًا في الدقة مقارنة بخطوط الأساس الكثيفة، خاصة بالنسبة للنماذج الأصغر، يمكن استنتاج التسريعات الحسابية مباشرة من هذه الأنماط المتفرقة. بالإضافة إلى ذلك، يمكن أن يمتزج التشتت الناتج عن هذه التقنية جيدًا مع الضغط الإضافي الذي يتم الحصول عليه من خلال التكميم.
LLM-Pruner
LLM-Pruner[13] هي طريقة تقليم مهيكلة تزيل بشكل انتقائي الهياكل المزدوجة غير الأساسية بناءً على معلومات التدرج، مما يزيد من التشتت إلى أقصى حد مع الاحتفاظ بمعظم وظائف LLM. LLM-Pruner، من خلال LoRA، يستعيد بكفاءة أداء النماذج المقلمة في 3 ساعات فقط و 50 ألف بيانات.
LLM-Pruner هو أول إطار عمل مصمم خصيصًا للتقليم المهيكل لنماذج LLM، مع المزايا الملخصة على النحو التالي: (i) ضغط غير مرتبط بالمهمة، حيث تحتفظ نماذج اللغة المضغوطة بقدرتها كحلول متعددة المهام. (ii) تقليل الطلب على مجموعات التدريب الأصلية، حيث يتطلب الضغط فقط 50,000 عينة متاحة للجمهور، مما يقلل بشكل كبير من ميزانية الحصول على بيانات التدريب. (iii) ضغط سريع، حيث تكتمل عملية الضغط في غضون ثلاث ساعات. (iv) إطار تقليم هيكلي تلقائي، حيث يتم تجميع جميع التبعيات الهيكلية دون الحاجة إلى أي تصميم يدوي.
لتقييم فعالية LLM-Pruner، تم إجراء تجارب موسعة على ثلاثة نماذج لغوية كبيرة: LLaMA-7B وVicuna-7B وChatGLM-6B. تم تقييم النماذج المضغوطة باستخدام تسع مجموعات بيانات لتقييم جودة التوليد وأداء التصنيف صفر-shot للنماذج المقلمة.
بالرجوع إلى الجدول أدناه، أدى تقليم LLaMA-7B بنسبة 20٪ باستخدام LLM-Pruner مع 2.59 مليون عينة إلى انخفاض طفيف في أداء النموذج ولكن زيادة ملحوظة بنسبة 18٪ في سرعة الاستدلال.

نتائج LLM-Pruner مع 2.59M عينة
Wanda
Wanda[14]، طريقة تقليم تعتمد على الأوزان والتنشيطات، هي نهج جديد وبسيط وفعال يهدف إلى إحداث التشتت في نماذج LLM المدربة مسبقًا. مستوحاة من الملاحظات الأخيرة لميزات القيمة الكبيرة في نماذج LLM، تقوم Wanda بتقليم الأوزان عن طريق ضرب كل مخرج مع التنشيط المدخل المقابل بالقيمة الكمية الدنيا.值得注意的是، لا تتطلب Wanda إعادة التدريب أو تحديثات الوزن، ويمكن استخدام نماذج LLM المقلمة كما هي. يؤكد تقييم Wanda على LLaMA وLLaMA-2 تفوقها على خطوط الأساس لتقليم المقدار المعمول بها، مما يدل على القدرة التنافسية مقارنة بالطرق الحديثة التي تتضمن تحديثات الوزن الكثيفة.
للاطلاع على الكود الهندسي، راجع المشروع: https://github.com/locuslab/wanda
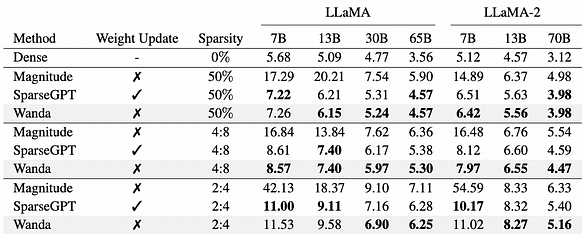
حيرة WikiText لنماذج LLaMA وLLaMA-2 المقلمة. تؤدي Wanda أداءً تنافسيًا مقارنة بأفضل طريقة سابقة SparseGPT، دون إدخال أي تحديث للوزن.
بالرجوع إلى الشكل أعلاه، تُظهر Wanda وSparseGPT أداءً مشابهًا في تقليم النموذج.
عيوب طرق التقليم التقليدية:
- دعم الأجهزة: تحقيق التسريع في وقت الساعة من خلال التشتت غير المهيكل أمر صعب بسبب الصعوبات المعروفة مع الأجهزة الحديثة. على سبيل المثال، حققت التطورات الأخيرة مثل SparseGPT تشتتًا غير مهيكل بنسبة 60٪ من خلال التقليم لمرة واحدة، لكنها لم تسفر عن أي تأثيرات تسريع كبيرة في وقت الساعة.
- تحديات النشر: تلبية متطلبات محددة من خلال تشتت النموذج في سياقات مثل التعلم السياقي (In-Context Learning) يمثل تحديات. في حين أظهرت العديد من الأعمال فعالية التقليم الخاص بمهمة معينة، فإن الحفاظ على نماذج مختلفة لكل مهمة يتعارض مع وضع LLM نفسه، مما يشكل عقبات أمام النشر.
الخلاصة:
باختصار، تقدم طرق التقليم المبتكرة مثل SparseGPT وLLM-Pruner وWanda وجهات نظر ووسائل تقنية جديدة لتقليم النماذج الكبيرة مع الحفاظ على الأداء العالي. ومع ذلك، لا تزال هناك حاجة إلى مزيد من البحث والاستكشاف لمعالجة التحديات في دعم الأجهزة والتطبيقات العملية. في منشور المدونة التالي، سنستكشف الجزء الثاني: “كيفية تسريع الاستدلال باستخدام تشتت التنشيط.”
الأوراق البحثية المرجعية
[1]Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
[4]The Hardware Lottery
[6]Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale
[12]SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot
[13]LLM-Pruner: On the Structural Pruning of Large Language Models
[14]A Simple and Effective Pruning Approach for Large Language Models
[17]Learning both Weights and Connections for Efficient Neural Networks
novita.ai توفر واجهة برمجة تطبيقات Stable Diffusion ومئات من واجهات برمجة التطبيقات السريعة والأقل تكلفة لتوليد الصور بالذكاء الاصطناعي لأكثر من 10,000 نموذج. 🎯 أسرع توليد في 2 ثانية فقط، الدفع حسب الاستخدام، بحد أدنى 0.0015 دولار لكل صورة قياسية، يمكنك إضافة نماذجك الخاصة وتجنب صيانة GPU. مجانًا لمشاركة الامتدادات مفتوحة المصدر.
قراءات موصى بها



