

- Concepts clés derrière DistilBERT
- Spécifications techniques de DistilBERT
- Amélioration de la classification de textes avec DistilBERT
- Exploiter DistilBERT pour l'analyse des sentiments
- Optimisation de DistilBERT pour la vitesse et l'utilisation de la mémoire
- Bonnes pratiques pour l'entraînement de DistilBERT sur des ensembles de données personnalisés
- Recherche en cours et limites
Introduction
DistilBERT est un modèle de langage révolutionnaire qui vise à rendre le traitement du langage naturel à grande échelle plus efficace et économique. Développé par Hugging Face, DistilBERT est une version distillée de BERT, un modèle de langage largement utilisé qui a considérablement amélioré l’état de l’art dans les tâches de NLP (traitement automatique du langage naturel).
Les modèles de langage comme BERT n’ont cessé de croître en taille et en complexité, avec des modèles comme la dernière version de Nvidia qui compte 8,3 milliards de paramètres, soit 24 fois plus que BERT-large. Bien que ces modèles plus grands aient conduit à de meilleures performances, ils ont un coût environnemental et financier.
Comprendre le besoin de modèles compacts
Les modèles plus petits comme DistilBERT offrent également des avantages pratiques. Ils peuvent être déployés sur des appareils aux ressources limitées, comme les smartphones, sans compromettre les performances. Cela permet de développer des applications réelles qui fonctionnent directement sur l’appareil, réduisant ainsi le besoin de serveurs GPU coûteux et garantissant la confidentialité des données.
La taille réduite de DistilBERT entraîne également des temps d’inférence plus rapides sur CPU, ce qui le rend idéal pour les applications nécessitant une faible latence et une grande réactivité, comme les chatbots ou les assistants vocaux. Cela est particulièrement important dans le domaine de l’apprentissage automatique, où les modèles compacts comme DistilBERT deviennent de plus en plus nécessaires pour un traitement efficace sur l’appareil.
Qu’est-ce que DistilBERT
DistilBERT est une version distillée de BERT, le modèle de langage original basé sur les transformeurs qui a révolutionné le NLP. Bien que BERT ait atteint des performances remarquables sur diverses tâches de NLP, sa grande taille et ses exigences informatiques le rendent difficile à utiliser dans des environnements aux ressources limitées.
Concepts clés derrière DistilBERT
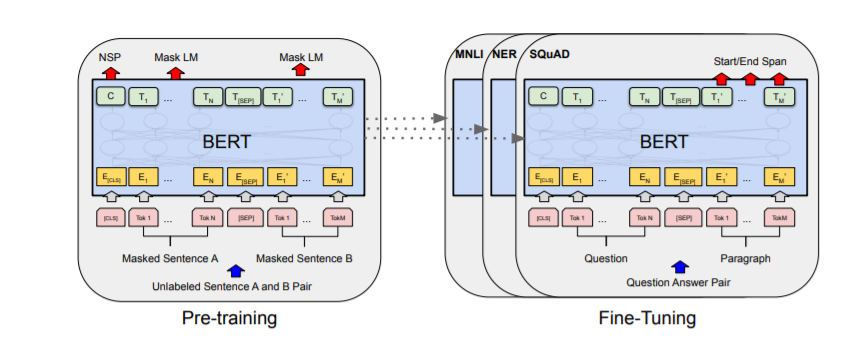
Les concepts clés derrière DistilBERT sont la distillation des connaissances, les biais inductifs et l’architecture des transformeurs. La distillation des connaissances est la technique utilisée pour compresser un modèle plus grand, comme BERT, en un modèle plus petit, comme DistilBERT. Elle consiste à entraîner le plus petit modèle à imiter le comportement du plus grand.
Les biais inductifs font référence aux hypothèses ou connaissances préalables intégrées dans l’architecture et le processus d’entraînement d’un modèle. DistilBERT bénéficie des biais inductifs appris par BERT lors du pré-entraînement, ce qui lui permet de bien généraliser sur diverses tâches de NLP.
L’architecture des transformeurs, initialement introduite par Vaswani et al., constitue la base de BERT et de DistilBERT. Elle comprend des mécanismes d’auto-attention qui capturent le contexte et les relations entre les mots dans une phrase, permettant aux modèles de comprendre et de générer le langage naturel.
Le mécanisme de distillation des connaissances dans DistilBERT
Le mécanisme de distillation des connaissances dans DistilBERT implique l’entraînement du modèle élève à imiter la distribution de sortie du modèle enseignant. Pendant l’entraînement, le modèle élève apprend à produire des probabilités similaires pour chaque classe que le modèle enseignant.
Le processus de distillation consiste à minimiser la différence entre les logits (scores de sortie avant l’application de softmax) du modèle élève et du modèle enseignant. Le modèle élève est entraîné à prédire les mêmes hautes probabilités pour les classes correctes que le modèle enseignant.
En incorporant les connaissances du modèle enseignant, le modèle élève peut approximer le comportement du modèle plus grand et atteindre des performances similaires sur les tâches en aval. Ce processus de distillation permet la compression des connaissances apprises par le modèle enseignant en un modèle plus petit et plus efficace comme DistilBERT.
Spécifications techniques de DistilBERT
DistilBERT possède plusieurs spécifications techniques qui en font un modèle plus compact et plus efficace que BERT. Il a environ 40 % de paramètres en moins que BERT, ce qui le rend plus léger et mieux adapté aux calculs sur l’appareil.
En termes d’inférence, DistilBERT est nettement plus rapide que BERT, avec une réduction de 60 % du temps d’inférence. Cela permet un traitement plus efficace des données textuelles et permet des applications en temps réel.
DistilBERT atteint ces améliorations en efficacité et en vitesse en utilisant la distillation des connaissances et en incorporant les biais inductifs appris par le modèle plus grand. Ces spécifications techniques font de DistilBERT un outil précieux pour les tâches de NLP nécessitant un traitement du langage rapide et efficace.
DistilBERT vs. BERT : une analyse comparative
Une analyse comparative entre DistilBERT et BERT révèle des différences clés en termes de performances, de taille de modèle et de temps d’entraînement. Bien que DistilBERT soit une version compressée de BERT, il conserve 97 % des performances de BERT sur diverses tâches de NLP.

La taille plus petite de DistilBERT le rend plus efficace en termes d’utilisation de la mémoire et de besoins de stockage. Cela permet des temps d’entraînement et d’inférence plus rapides par rapport à BERT.
Malgré la réduction de la taille du modèle, DistilBERT maintient des performances élevées sur un large éventail de tâches de NLP, ce qui en fait une alternative appropriée pour les applications avec des ressources limitées ou des contraintes informatiques plus strictes.

Métriques de performance : efficacité et précision de DistilBERT
Les performances de DistilBERT peuvent être évaluées en fonction de son efficacité et de sa précision sur diverses tâches en aval. Par rapport à BERT, DistilBERT démontre des performances comparables, voire meilleures, tout en étant un modèle plus efficace et plus léger.
DistilBERT obtient de bons résultats sur le benchmark GLUE (General Language Understanding Evaluation), qui comprend plusieurs tâches de NLP en aval. Il atteint des scores élevés en précision et en F1 sur des tâches telles que l’analyse des sentiments, la classification de textes et la réponse aux questions.
L’efficacité de DistilBERT se reflète dans sa taille de modèle plus petite et ses temps d’inférence plus rapides. Cela le rend plus adapté aux applications en temps réel, où une faible latence et une grande réactivité sont cruciales. De plus, les besoins informatiques réduits de DistilBERT contribuent à un impact environnemental moindre, ce qui en fait un choix plus durable pour les tâches de NLP.
Comment implémenter DistilBERT
La bibliothèque Transformers de Huggingface propose une gamme de modèles DistilBERT en différentes versions et tailles. Dans ce guide, nous allons montrer comment charger un modèle et effectuer une classification à une seule étiquette.
Tout d’abord, nous installerons et importerons les packages nécessaires. Ensuite, nous chargerons le modèle “distilbert-base-uncased-finetuned-sst-2-english” ainsi que son tokenizer en utilisant respectivement DistilBertForSequenceClassification et DistilBertTokenizer. Ensuite, nous tokeniserons les données d’entrée et utiliserons la sortie tokenisée pour prédire l’étiquette, qui dans cet exemple est l’analyse des sentiments.
!pip install -q transformers
import torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
inputs = tokenizer("Wow! What a surprise!", return_tensors="pt")
with torch.inference_mode():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
DistilBERT en action : études de cas
DistilBERT a été appliqué avec succès dans diverses études de cas, démontrant son efficacité dans différentes tâches de NLP. Deux exemples notables sont l’analyse des sentiments et la classification de textes.
Amélioration de la classification de textes avec DistilBERT
DistilBERT peut grandement améliorer les tâches de classification de textes en fournissant des prédictions précises de manière plus rapide et plus efficace. Il utilise la même architecture que BERT mais avec moins de couches et des embeddings de type de jeton et le pooler supprimés.
Malgré ces changements, DistilBERT conserve 95 % des performances de BERT sur le benchmark GLUE pour la compréhension du langage. Cela fait de DistilBERT un outil puissant pour diverses tâches de classification de textes, notamment l’analyse des sentiments, la reconnaissance d’entités nommées et la détection d’intention.
Exploiter DistilBERT pour l’analyse des sentiments
L’analyse des sentiments est une tâche courante de NLP qui consiste à déterminer le sentiment ou l’émotion exprimé dans un texte. DistilBERT, en particulier le modèle DistilBertForSequenceClassification, est bien adapté à l’analyse des sentiments car il a été entraîné sur un vaste corpus de textes et possède une solide compréhension du langage. En ajustant DistilBERT sur un ensemble de données d’analyse des sentiments, il peut classer avec précision les textes en sentiments positifs, négatifs ou neutres.
Les probabilités attribuées à chaque classe de sentiment par DistilBERT peuvent être utilisées pour évaluer la force du sentiment exprimé dans le texte. Grâce à sa taille plus petite et à son temps d’inférence plus rapide, DistilBERT est un choix idéal pour les applications d’analyse des sentiments qui nécessitent une analyse en temps réel de grandes quantités de texte, comme la surveillance des médias sociaux ou l’analyse des commentaires des clients.
Conseils avancés pour maximiser les capacités de DistilBERT
Optimisation de DistilBERT pour la vitesse et l’utilisation de la mémoire
Pour maximiser la vitesse et l’utilisation de la mémoire de DistilBERT, il est recommandé d’utiliser l’accélération GPU et d’optimiser le code pour le traitement parallèle. Cela peut réduire considérablement le temps d’inférence de DistilBERT, le rendant plus efficace pour les applications en temps réel. De plus, des techniques telles que la quantification et l’élagage peuvent réduire davantage l’utilisation de la mémoire de DistilBERT sans compromettre ses performances.
Bonnes pratiques pour l’entraînement de DistilBERT sur des ensembles de données personnalisés
Lors de l’entraînement de DistilBERT sur des ensembles de données personnalisés, il est important de suivre les bonnes pratiques pour obtenir des résultats optimaux. Cela comprend un prétraitement approprié des données, la garantie d’une distribution équilibrée des classes, et l’ajustement du modèle avec un taux d’apprentissage et un nombre d’époques appropriés. Des techniques d’augmentation des données, telles que le masquage aléatoire de mots ou le mélange, peuvent également être appliquées pour augmenter la diversité des données d’entraînement et améliorer les capacités de généralisation du modèle.
Optimisation de DistilBERT pour la vitesse et l’utilisation de la mémoire
Pour optimiser DistilBERT en termes de vitesse et d’utilisation de la mémoire, plusieurs techniques peuvent être appliquées.
Tout d’abord, l’utilisation d’accélérations matérielles telles que les GPU peut grandement améliorer la vitesse d’inférence de DistilBERT.
De plus, l’optimisation du code pour le traitement parallèle et l’exploitation du traitement par lots, comme l’entraînement sur de très grands lots, peuvent encore améliorer la vitesse des calculs de DistilBERT. Pour réduire l’utilisation de la mémoire, des techniques telles que la quantification (approximation des poids d’un réseau avec une précision plus faible) et l’élagage des poids (suppression de certaines connexions dans le réseau) peuvent être utilisées.
L’avenir des modèles compacts comme DistilBERT
Les modèles compacts comme DistilBERT représentent l’avenir du NLP car ils offrent une solution plus efficace et plus économique par rapport aux modèles plus grands. La demande de capacités de traitement du langage sur l’appareil augmente, et les modèles compacts fournissent une solution viable qui peut fonctionner sur des appareils aux ressources limitées.
Alors que la recherche sur les techniques de compression de modèles continue de progresser, nous pouvons nous attendre à des modèles encore plus petits et plus rapides avec des performances améliorées ces dernières années. De plus, la disponibilité de modèles compacts pré-entraînés comme DistilBERT permet aux développeurs de déployer rapidement des applications de NLP sans avoir besoin de ressources informatiques étendues. L’avenir du NLP verra l’adoption et le développement généralisés de modèles compacts, tels que DistilBERT, pour répondre aux exigences du traitement du langage en temps réel en utilisant la puissance de l’apprentissage profond.
Recherche en cours et limites
Les groupes de recherche universitaires et industriels continuent d’explorer le vaste potentiel de DistilBERT tout en reconnaissant ses limites. Les universités et les laboratoires de recherche en IA se penchent sur les subtilités du modèle pour améliorer ses capacités et étendre son applicabilité.
- Initiatives de recherche : Les principales universités et groupes de recherche en IA collaborent pour repousser les limites du potentiel de DistilBERT.
- Traitement des limites : Les recherches en cours se concentrent sur l’amélioration de la rétention du contexte sur des textes plus longs et la compréhension nuancée du langage.
- Affinement du modèle : Des efforts sont faits pour affiner DistilBERT pour des tâches spécifiques, telles que le diagnostic médical et l’analyse de documents juridiques, où la précision est cruciale.
Cependant, il est long de surmonter ces limites. Vous pouvez choisir de meilleurs modèles comme Llama 3 récemment publié pour accomplir votre travail en gagnant du temps. Voici novita.ai API LLM avec les modèles suivants :

Essayez notre API LLM gratuitement dès maintenant :

Conclusion
En conclusion, DistilBERT a révolutionné le monde des modèles d’IA grâce à son design compact et son efficacité accrue. En distillant les connaissances de son prédécesseur BERT, il offre une alternative plus rapide et plus légère sans compromettre la précision.
L’application de DistilBERT dans des scénarios réels, tels que la classification de textes et l’analyse des sentiments, montre son immense potentiel. Il est crucial de comprendre les spécifications techniques et les métriques de performance pour exploiter ses capacités de manière optimale. Alors que nous explorons l’avenir des modèles compacts comme DistilBERT, les progrès continus dans les techniques de compression de modèles promettent des perspectives passionnantes pour le développement et l’innovation en IA. Restez à l’écoute pour la prochaine génération de modèles d’IA et explorez les possibilités qui vous attendent.
novita.ai, la plateforme tout-en-un pour une créativité illimitée qui vous donne accès à plus de 100 APIs. De la génération d’images au traitement du langage, en passant par l’amélioration audio et la manipulation vidéo, avec un paiement à l’utilisation économique, elle vous libère des contraintes de maintenance GPU tout en construisant vos propres produits. Essayez-la gratuitement.
Lecture recommandée
Moteur d’inférence LLM Novita AI : le plus grand débit et l’inférence la moins chère disponibles



