

Introduction
DistilBERT is a revolutionary language model that aims to make large-scale language processing more efficient and cost-effective. Developed by Hugging Face, DistilBERT is a distilled version of BERT, a widely used language model that has significantly improved the state-of-the-art in NLP tasks.
Language models like BERT have been growing in size and complexity, with models like Nvidia’s latest release having 8.3 billion parameters, 24 times larger than BERT-large. While these larger models have led to better performance, they come with environmental and financial costs.
Understanding the Need for Compact Models
Smaller models like DistilBERT also have practical advantages. They can be deployed on resource-constrained devices like smartphones without compromising performance. This enables the development of real-world applications that can run on-device, reducing the need for costly GPU servers and ensuring data privacy.
The smaller size of DistilBERT also results in faster inference times on CPU, making it ideal for applications that require low latency and responsiveness, such as chatbots or voice assistants. This is especially important in the field of machine learning, where compact models like DistilBERT are becoming increasingly necessary for efficient and effective on-device processing.
What is DistilBERT
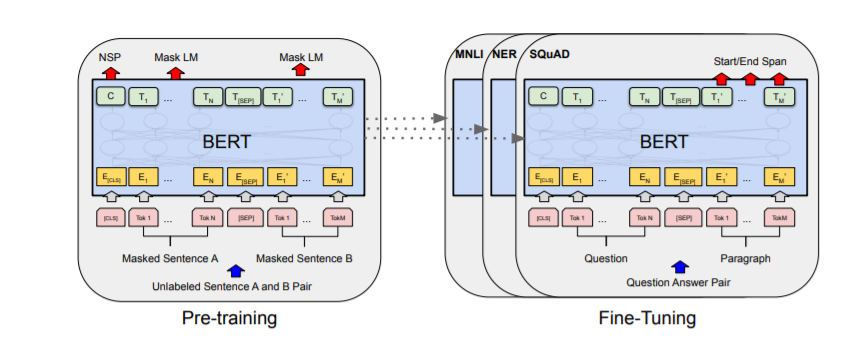
DistilBERT is a distilled version of BERT, the original transformer-based language model that has revolutionized NLP. While BERT has achieved remarkable performance on various NLP tasks, its large size and computational requirements make it challenging to use in resource-constrained settings.
Core Concepts Behind DistilBERT
The core concepts behind DistilBERT are knowledge distillation, inductive biases, and the transformer architecture. Knowledge distillation is the technique used to compress a larger model, like BERT, into a smaller model, like DistilBERT. It involves training the smaller model to mimic the behavior of the larger model.
Inductive biases refer to the assumptions or prior knowledge embedded in the architecture and training process of a model. DistilBERT benefits from the inductive biases learned by BERT during pre-training, allowing it to generalize well to various NLP tasks.
The transformer architecture, originally introduced by Vaswani et al., forms the basis of both BERT and DistilBERT. It consists of self-attention mechanisms that capture the context and relationships between words in a sentence, enabling the models to understand and generate natural language.
The Mechanism of Distilling Knowledge in DistilBERT
The mechanism of distilling knowledge in DistilBERT involves training the student model to mimic the output distribution of the teacher model. During training, the student model learns to produce similar probabilities for each class as the teacher model.
The distillation process consists of minimizing the difference between the logits (output scores before applying softmax) of the student and teacher models. The student model is trained to predict the same high probabilities for the correct classes as the teacher model.
By incorporating the knowledge from the teacher model, the student model is able to approximate the behavior of the larger model and achieve similar performance on downstream tasks. This distillation process allows for the compression of the knowledge learned by the teacher model into a smaller and more efficient model like DistilBERT.
Technical Specifications of DistilBERT
DistilBERT has several technical specifications that make it a more compact and efficient model compared to BERT. It has approximately 40% fewer parameters than BERT, making it lighter and more suitable for on-device computations.
In terms of inference, DistilBERT is significantly faster than BERT, with a 60% reduction in inference time. This allows for more efficient processing of text data and enables real-time applications.
DistilBERT achieves these improvements in efficiency and speed by leveraging knowledge distillation and incorporating inductive biases learned by the larger model. These technical specifications make DistilBERT a valuable tool for NLP tasks that require fast and efficient language processing.
DistilBERT vs. BERT: A Comparative Analysis
A comparative analysis between DistilBERT and BERT reveals key differences in performance, model size, and training time. While DistilBERT is a compressed version of BERT, it retains 97% of BERT’s performance on various NLP tasks.

DistilBERT’s smaller model size makes it more efficient in terms of memory usage and storage requirements. This enables faster training and inference times compared to BERT.
Despite the reduction in model size, DistilBERT maintains high performance on a wide range of NLP tasks, making it a suitable alternative for applications with limited resources or stricter computational constraints.

Performance Metrics: DistilBERT’s Efficiency and Accuracy
DistilBERT’s performance can be evaluated based on its efficiency and accuracy across various downstream tasks. When compared to BERT, DistilBERT demonstrates comparable or even better performance while being a more efficient and lightweight model.
DistilBERT performs well on the General Language Understanding Evaluation (GLUE) benchmark, which consists of multiple downstream NLP tasks. It achieves high accuracy and F1 scores on tasks such as sentiment analysis, text classification, and question answering.
The efficiency of DistilBERT is reflected in its smaller model size and faster inference times. This makes it more suitable for real-time applications, where low latency and responsiveness are crucial. Additionally, DistilBERT’s reduced computational requirements contribute to a lower environmental impact, making it a more sustainable choice for NLP tasks.
How to Implement DistilBERT
Huggingface’s Transformers library provides a range of DistilBERT models in various versions and sizes. In this guide, we will demonstrate how to load a model and perform single-label classification.
First, we will install and import the necessary packages. Then, we will load the “distilbert-base-uncased-finetuned-sst-2-english” model along with its tokenizer using DistilBertForSequenceClassification and DistilBertTokenizer, respectively. Next, we will tokenize the input data, and use the tokenized output to predict the label, which in this example, is sentiment analysis.
!pip install -q transformersimport torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassificationtokenizer = DistilBertTokenizer.from_pretrained(“distilbert-base-uncased-finetuned-sst-2-english”)
model = DistilBertForSequenceClassification.from_pretrained(“distilbert-base-uncased-finetuned-sst-2-english”)inputs = tokenizer(“Wow! What a surprise!”, return_tensors=“pt”)with torch.inference_mode():
logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
DistilBERT in Action: Case Studies
DistilBERT has been successfully applied in various case studies, demonstrating its effectiveness in different NLP tasks. Two noteworthy examples are sentiment analysis and text classification.
Enhancing Text Classification with DistilBERT
DistilBERT can greatly enhance text classification tasks by providing accurate predictions in a faster and more efficient manner. It uses the same architecture as BERT but with fewer layers and removed token-type embeddings and pooler.
Despite these changes, DistilBERT retains 95% of BERT’s performance on the GLUE benchmark for language understanding. This makes DistilBERT a powerful tool for various text classification tasks, including sentiment analysis, named entity recognition, and intent detection.
Leveraging DistilBERT for Sentiment Analysis
Sentiment analysis is a common NLP task that involves determining the sentiment or emotion expressed in a piece of text. DistilBERT, specifically the DistilBertForSequenceClassification model, is well-suited for sentiment analysis as it has been trained on a large corpus of text and has a strong understanding of language. By fine-tuning DistilBERT on a sentiment analysis dataset, it can accurately classify text into positive, negative, or neutral sentiments.
The probabilities assigned to each sentiment class by DistilBERT can be used to gauge the strength of the sentiment expressed in the text. With its smaller size and faster inference time, DistilBERT is an ideal choice for sentiment analysis applications that require real-time analysis of large amounts of text, such as social media monitoring or customer feedback analysis.
Advanced Tips for Maximizing DistilBERT’s Capabilities
Optimizing DistilBERT for Speed and Memory Usage
To maximize the speed and memory usage of DistilBERT, it is recommended to utilize GPU acceleration and optimize the code for parallel processing. This can significantly reduce the inference time of DistilBERT, making it more efficient for real-time applications. Additionally, using techniques such as quantization and pruning can further reduce the memory usage of DistilBERT without compromising its performance.
Best Practices for Training DistilBERT on Custom Datasets
When training DistilBERT on custom datasets, it is important to follow best practices to achieve optimal results. This includes properly preprocessing the data, ensuring a balanced distribution of classes, and fine-tuning the model with an appropriate learning rate and number of epochs. Data augmentation techniques, such as random word masking or shuffling, can also be applied to increase the diversity of the training data and improve the model’s generalization capabilities.
Optimizing DistilBERT for Speed and Memory Usage
To optimize DistilBERT for speed and memory usage, there are several techniques that can be applied.
First, utilizing hardware acceleration such as GPUs can greatly improve the inference speed of DistilBERT.
Additionally, optimizing the code for parallel processing and leveraging batch processing, such as training on very large batches, can further enhance the speed of DistilBERT’s computations. To reduce memory usage, techniques such as quantization (approximating the weights of a network with a smaller precision) and weights pruning (removing some connections in the network) can be used.
The Future of Compact Models Like DistilBERT
Compact models like DistilBERT represent the future of NLP as they offer a more efficient and cost-effective solution compared to larger models. The demand for on-device language processing capabilities is increasing, and compact models provide a viable solution that can run on resource-constrained devices.
As research in model compression techniques continues to advance, we can expect even smaller and faster models with improved performance in recent years. Additionally, the availability of pre-trained compact models like DistilBERT enables developers to quickly deploy NLP applications without the need for extensive computational resources. The future of NLP will see the widespread adoption and development of compact models, such as DistilBERT, to meet the demands of real-time language processing using the power of deep learning.
Ongoing Research and Limitations
Both academic and industrial research groups continue to explore the vast potential of DistilBERT while recognizing its limitations. Universities and AI research labs are delving into the model’s intricacies to enhance its capabilities and extend its applicability.
- Research Initiatives: Leading universities and AI research groups are collaborating to push the boundaries of DistilBERT’s potential.
- Addressing Limitations: Ongoing research focuses on improving context retention over longer texts and nuanced language understanding.
- Model Refinement: Efforts are being made to refine DistilBERT for specific tasks, such as medical diagnosis and legal document analysis, where precision is crucial.
However, it is time-consuming to overcome these limitations. You can choose better models such as Llama 3 released recently to get your work done with time saved. Here is novita.ai LLM API featuring models:

Try our LLM API for free now:

Conclusion
In conclusion, DistilBERT has revolutionized the world of AI models with its compact design and enhanced efficiency. By distilling knowledge from its predecessor BERT, it offers a faster and lighter alternative without compromising on accuracy.
The application of DistilBERT in real-world scenarios, such as text classification and sentiment analysis, showcases its immense potential. It is crucial to understand the technical specifications and performance metrics to leverage its capabilities optimally. As we delve into the future of compact models like DistilBERT, continuous advancements in model compression techniques promise exciting prospects for AI development and innovation. Stay tuned for the next generation of AI models and explore the possibilities that await.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available



