

引言
DistilBERT 是一種革命性的語言模型,旨在讓大規模語言處理更有效率且更具成本效益。由 Hugging Face 開發,DistilBERT 是 BERT(一個廣泛使用的語言模型)的蒸餾版本,後者大幅提升了 NLP 任務的技術水準。
像 BERT 這類語言模型在規模和複雜度上不斷成長,例如 Nvidia 最新發佈的模型擁有 83 億個參數,比 BERT-large 大了 24 倍。雖然這些更大的模型帶來了更好的效能,但也伴隨著環境與財務成本的增加。
理解輕量模型的需求
像 DistilBERT 這類較小的模型也具有實務上的優勢。它們可以部署在資源受限的裝置上(如智慧型手機),同時不犧牲效能。這使得開發能在裝置端執行的真實世界應用成為可能,減少對昂貴 GPU 伺服器的需求,並確保資料隱私。
DistilBERT 較小的體積也讓 CPU 的推論時間更快,使其非常適合需要低延遲與高回應性的應用,例如聊天機器人或語音助理。這在機器學習領域尤其重要,因為像 DistilBERT 這類輕量模型對於在裝置端進行高效且有效的處理變得越來越必要。
什麼是 DistilBERT
DistilBERT 是 BERT 的蒸餾版本,而 BERT 是原始基於 transformer 的語言模型,徹底改變了 NLP。雖然 BERT 在各種 NLP 任務上表現卓越,但其龐大的體積和計算需求使得在資源受限的環境中使用變得困難。
DistilBERT 的核心概念
DistilBERT 的核心概念包括知識蒸餾、歸納偏置以及 transformer 架構。知識蒸餾是將較大模型(如 BERT)壓縮成較小模型(如 DistilBERT)所使用的技術。它透過訓練較小的模型來模仿較大模型的行為。
歸納偏置指的是嵌入在模型架構和訓練過程中的假設或先驗知識。DistilBERT 受益於 BERT 在預訓練中學到的歸納偏置,使其能夠良好地泛化到各種 NLP 任務。
Transformer 架構最初由 Vaswani 等人提出,構成了 BERT 和 DistilBERT 的基礎。它包含自注意力機制,能夠捕捉句子中單詞之間的上下文和關係,使模型能夠理解和生成自然語言。
DistilBERT 中的知識蒸餾機制
DistilBERT 中的知識蒸餾機制涉及訓練學生模型來模仿教師模型的輸出分佈。在訓練過程中,學生模型學習為每個類別產生與教師模型類似的機率。
蒸餾過程包括最小化學生的 logits(在應用 softmax 之前的輸出分數)與教師的 logits 之間的差異。學生模型被訓練來預測與教師模型相同的高機率正確類別。
透過納入教師模型的知識,學生模型能夠近似較大模型的行為,並在下游任務上達到類似的效能。這種蒸餾過程允許將教師模型學到的知識壓縮成更小、更有效率的模型,例如 DistilBERT。
DistilBERT 的技術規格
DistilBERT 擁有幾項技術規格,使其相較於 BERT 成為更輕量且有效率的模型。它的參數比 BERT 少了約 40%,更輕量且更適合在裝置端計算。
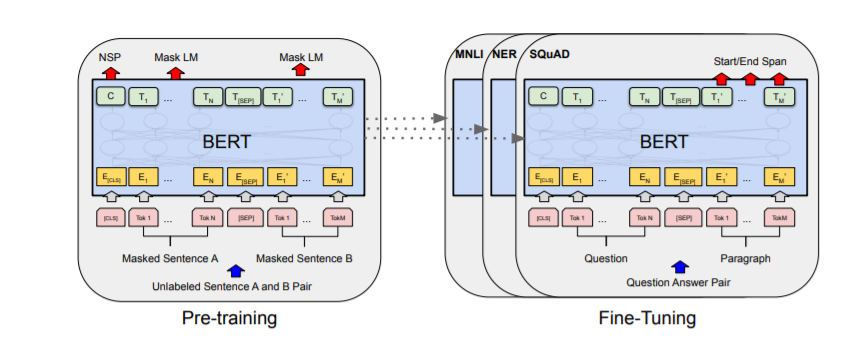
在推論方面,DistilBERT 比 BERT 快得多,推論時間減少了 60%。這使得文字資料的處理更有效率,並實現即時應用。
DistilBERT 透過利用知識蒸餾和納入較大模型學到的歸納偏置,實現了效率和速度的提升。這些技術規格使 DistilBERT 成為需要快速且高效語言處理的 NLP 任務的寶貴工具。
DistilBERT 與 BERT:比較分析
DistilBERT 與 BERT 的比較分析揭示了它們在效能、模型大小和訓練時間上的關鍵差異。雖然 DistilBERT 是 BERT 的壓縮版本,但在各種 NLP 任務上保留了 BERT 97% 的效能。

DistilBERT 較小的模型大小使其在記憶體使用和儲存需求上更有效率。這使得訓練和推論時間都比 BERT 更快。
儘管模型大小減小了,DistilBERT 在廣泛的 NLP 任務上仍保持高效能,使其成為資源有限或計算條件較嚴格環境的合適替代方案。

效能指標:DistilBERT 的效率與準確度
DistilBERT 的效能可以根據其在各種下游任務上的效率和準確度來評估。與 BERT 相比,DistilBERT 表現出相當甚至更好的效能,同時是更有效率且更輕量的模型。
DistilBERT 在通用語言理解評估(GLUE)基準上表現良好,該基準包含多個下游 NLP 任務。它在情感分析、文字分類和問答等任務上取得了高準確度和 F1 分數。
DistilBERT 的效率體現在其較小的模型大小和更快的推論時間。這使其更適合即時應用,因為低延遲和高回應性至關重要。此外,DistilBERT 降低的計算需求也有助於減少環境影響,使其成為 NLP 任務中更永續的選擇。
如何實作 DistilBERT
Huggingface 的 Transformers 函式庫提供了多種版本的 DistilBERT 模型。在本指南中,我們將示範如何載入模型並執行單標籤分類。
首先,我們將安裝並匯入必要的套件。然後,我們將使用 DistilBertForSequenceClassification 和 DistilBertTokenizer 分別載入 distilbert-base-uncased-finetuned-sst-2-english 模型及其分詞器。接著,我們將對輸入資料進行分詞,並使用分詞後的輸出預測標籤,在此範例中為情感分析。
!pip install -q transformersimport torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassificationtokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")inputs = tokenizer("Wow! What a surprise!", return_tensors="pt")with torch.inference_mode():
logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
DistilBERT 實際應用案例
DistilBERT 已成功應用於多個案例研究,展示了其在不同 NLP 任務中的有效性。兩個值得注意的例子是情感分析和文字分類。
使用 DistilBERT 強化文字分類
DistilBERT 可以透過提供更快、更有效率的準確預測,大幅強化文字分類任務。它使用與 BERT 相同的架構,但層數較少,並移除了 token 類型嵌入和池化器。
儘管有這些變更,DistilBERT 在語言理解的 GLUE 基準上仍保留了 BERT 95% 的效能。這使得 DistilBERT 成為各種文字分類任務的強大工具,包括情感分析、命名實體識別和意圖偵測。
利用 DistilBERT 進行情感分析
情感分析是一種常見的 NLP 任務,涉及判斷一段文字所表達的情感或情緒。DistilBERT,特別是 DistilBertForSequenceClassification 模型,非常適合情感分析,因為它已在大量文字語料上進行訓練,並對語言有深入的理解。透過在情感分析資料集上微調 DistilBERT,它可以準確地將文字分類為正面、負面或中性情感。
DistilBERT 分配給每個情感類別的機率可用於衡量文字中所表達情感的強度。憑藉其較小的體積和更快的推論時間,DistilBERT 是需要即時分析大量文字的情感分析應用(例如社群媒體監控或客戶回饋分析)的理想選擇。
最大化 DistilBERT 能力的進階技巧
優化 DistilBERT 的速度與記憶體使用
為了最大化 DistilBERT 的速度和記憶體使用,建議利用 GPU 加速並優化程式碼以進行平行處理。這可以顯著減少 DistilBERT 的推論時間,使其在即時應用中更有效率。此外,使用量化(quantization)和剪枝(pruning)等技術可以進一步減少 DistilBERT 的記憶體使用量,同時不損害其效能。
在自訂資料集上訓練 DistilBERT 的最佳實務
在自訂資料集上訓練 DistilBERT 時,遵循最佳實務以獲得最佳結果非常重要。這包括適當的資料前處理、確保類別平衡分佈,以及使用合適的學習率和訓練週期數來微調模型。資料增強技術(如隨機遮罩或打亂單詞)也可以應用於增加訓練資料的多樣性,並改善模型的泛化能力。
優化 DistilBERT 的速度與記憶體使用
為了優化 DistilBERT 的速度和記憶體使用,可以應用多種技術。
首先,利用硬體加速(如 GPU)可以大幅提升 DistilBERT 的推論速度。
此外,優化程式碼以進行平行處理,並利用批次處理(例如使用非常大的批次進行訓練),可以進一步提升 DistilBERT 的計算速度。為了減少記憶體使用,可以使用量化(以較低精度近似網路權重)和權重剪枝(移除網路中的部分連接)等技術。
輕量模型(如 DistilBERT)的未來
像 DistilBERT 這類輕量模型代表了 NLP 的未來,因為它們相比於較大的模型提供了更有效率且更具成本效益的解決方案。對裝置端語言處理能力的需求正在增加,而輕量模型提供了一個可行的解決方案,可以在資源受限的裝置上運行。
隨著模型壓縮技術研究的持續進展,我們可以期待近年來出現更小、更快且效能更好的模型。此外,像 DistilBERT 這類預訓練輕量模型的可用性,使開發者能夠快速部署 NLP 應用,而無需大量的計算資源。NLP 的未來將見證像 DistilBERT 這類輕量模型的廣泛採用和發展,以滿足即時語言處理的需求,並利用深度學習的力量。
持續進行的研究與限制
學術和工業研究團隊持續探索 DistilBERT 的巨大潛力,同時也認識到其限制。大學和 AI 研究實驗室正在深入研究該模型的細節,以增強其能力並擴大其適用性。
- 研究計劃:頂尖大學和 AI 研究小組正在合作,推動 DistilBERT 潛力的極限。
- 解決限制:持續的研究專注於改善在較長文本上的上下文保留能力以及細微語言的 understanding。
- 模型優化:正在努力針對特定任務(例如醫療診斷和法律文件分析)優化 DistilBERT,這些任務中精確度至關重要。
然而,克服這些限制需要耗費時間。您可以選擇更好的模型(例如最近發佈的 Llama 3)來節省時間並完成工作。這裡是 novita.ai 的 LLM API,提供以下模型:

立即免費試用我們的 LLM API:

結論
總之,DistilBERT 以其緊湊的設計和更高的效率革新了 AI 模型的世界。透過從其前身 BERT 中蒸餾知識,它提供了一個更快、更輕量的替代方案,同時不犧牲準確度。
DistilBERT 在真實場景中的應用(如文字分類和情感分析)展現了其巨大的潛力。理解其技術規格和效能指標對於最佳化利用其能力至關重要。當我們深入探討像 DistilBERT 這類輕量模型的未來時,模型壓縮技術的持續進展預示著 AI 發展與創新的令人興奮的前景。敬請期待下一代 AI 模型,並探索隨之而來的可能性。
novita.ai 是一個一站式平台,為無限創意提供 100 多個 API。從圖像生成和語言處理到音訊增強和影片操作,採用按量付費的廉價方案,讓您在建立自己的產品時無需煩惱 GPU 維護。立即免費試用。
推薦閱讀



