

简介
DistilBERT 是一种革命性的语言模型,旨在使大规模语言处理更加高效和成本效益。由 Hugging Face 开发,DistilBERT 是 BERT 的精简版本,BERT 是一种广泛使用的语言模型,显著提升了 NLP 任务的最新水平。
像 BERT 这样的语言模型在规模和复杂性上不断增长,例如 Nvidia 最新发布的模型拥有 83 亿个参数,是 BERT-large 的 24 倍。虽然这些更大的模型带来了更好的性能,但也伴随着环境和财务成本。
理解紧凑模型的需求
像 DistilBERT 这样更小的模型也具有实际优势。它们可以在不牺牲性能的情况下部署在智能手机等资源受限的设备上。这使得开发能够在设备上运行的现实世界应用成为可能,从而减少了对昂贵 GPU 服务器的需求并确保了数据隐私。
DistilBERT 较小的体积也使得 CPU 上的推理时间更快,非常适合需要低延迟和响应性的应用,例如聊天机器人或语音助手。这在机器学习领域尤为重要,像 DistilBERT 这样的紧凑模型对于高效且有效的设备端处理变得越来越必要。
什么是 DistilBERT
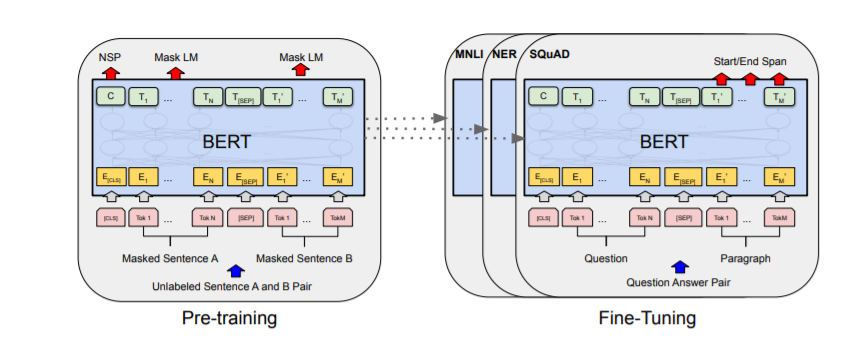
DistilBERT 是 BERT 的精简版本,BERT 是原始基于 Transformer 的语言模型,彻底改变了 NLP。尽管 BERT 在各种 NLP 任务中取得了显著性能,但其庞大的体积和计算需求使其在资源受限的环境中使用具有挑战性。
DistilBERT 的核心概念
DistilBERT 的核心概念包括知识蒸馏、归纳偏差和 Transformer 架构。知识蒸馏是一种将较大模型(如 BERT)压缩为较小模型(如 DistilBERT)的技术。它通过训练较小的模型来模仿较大模型的行为。
归纳偏差指的是嵌入在模型架构和训练过程中的假设或先验知识。DistilBERT 受益于 BERT 在预训练期间学到的归纳偏差,使其能够很好地泛化到各种 NLP 任务。
Transformer 架构最初由 Vaswani 等人提出,构成了 BERT 和 DistilBERT 的基础。它由自注意力机制组成,能够捕捉句子中单词之间的上下文和关系,使模型能够理解和生成自然语言。
DistilBERT 中的知识蒸馏机制
DistilBERT 中的知识蒸馏机制涉及训练学生模型模仿教师模型的输出分布。在训练过程中,学生模型学习为每个类别生成与教师模型相似的概率。
蒸馏过程包括最小化学生模型和教师模型的 logits(应用 softmax 之前的输出分数)之间的差异。学生模型被训练为预测与教师模型相同的正确类别的高概率。
通过结合来自教师模型的知识,学生模型能够近似较大模型的行为,并在下游任务上实现相近的性能。这种蒸馏过程允许将教师模型学到的知识压缩成更小、更高效的模型,如 DistilBERT。
DistilBERT 的技术规格
DistilBERT 具有多个技术规格,使其成为比 BERT 更紧凑、更高效的模型。它的参数比 BERT 少约 40%,使其更轻量,更适合设备端计算。
在推理方面,DistilBERT 比 BERT 快得多,推理时间减少了 60%。这使得文本数据的处理更高效,并支持实时应用。
DistilBERT 通过利用知识蒸馏并结合较大模型学到的归纳偏差来实现这些效率和速度的提升。这些技术规格使 DistilBERT 成为需要快速高效语言处理的 NLP 任务的宝贵工具。
DistilBERT 与 BERT:对比分析
DistilBERT 与 BERT 的对比分析揭示了性能、模型大小和训练时间方面的关键差异。尽管 DistilBERT 是 BERT 的压缩版本,但在各种 NLP 任务上保留了 BERT 97% 的性能。

DistilBERT 较小的模型大小使其在内存使用和存储需求方面更加高效。与 BERT 相比,这使得训练和推理时间更快。
尽管模型大小减小,DistilBERT 仍然在广泛的 NLP 任务上保持高性能,使其成为资源有限或计算约束更严格的应用的合适替代方案。

性能指标:DistilBERT 的效率和准确性
DistilBERT 的性能可以根据其在各种下游任务上的效率和准确性来评估。与 BERT 相比,DistilBERT 表现出相当甚至更好的性能,同时是一个更高效、更轻量的模型。
DistilBERT 在通用语言理解评估(GLUE)基准测试上表现良好,该基准由多个下游 NLP 任务组成。它在情感分析、文本分类和问答等任务上取得了高准确率和 F1 分数。
DistilBERT 的效率体现在其较小的模型大小和更快的推理时间上。这使得它更适合实时应用,因为低延迟和响应性至关重要。此外,DistilBERT 降低的计算需求有助于减少环境影响,使其成为 NLP 任务更可持续的选择。
如何实现 DistilBERT
Huggingface 的 Transformers 库提供了各种版本和大小的 DistilBERT 模型。在本指南中,我们将演示如何加载模型并执行单标签分类。
首先,我们将安装并导入必要的包。然后,我们将使用 DistilBertForSequenceClassification 和 DistilBertTokenizer 分别加载“distilbert-base-uncased-finetuned-sst-2-english”模型及其分词器。接下来,我们将对输入数据进行分词,并使用分词后的输出预测标签,在本例中为情感分析。
!pip install -q transformers
import torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
inputs = tokenizer("Wow! What a surprise!", return_tensors="pt")
with torch.inference_mode():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
DistilBERT 实际应用:案例研究
DistilBERT 已成功应用于多个案例研究,展示了其在不同 NLP 任务中的有效性。两个值得注意的例子是情感分析和文本分类。
使用 DistilBERT 增强文本分类
DistilBERT 可以通过提供更快、更高效的准确预测来显著增强文本分类任务。它使用与 BERT 相同的架构,但层数更少,并移除了 token 类型嵌入和池化器。
尽管有这些变化,DistilBERT 在 GLUE 语言理解基准上保留了 BERT 95% 的性能。这使得 DistilBERT 成为各种文本分类任务的强大工具,包括情感分析、命名实体识别和意图检测。
利用 DistilBERT 进行情感分析
情感分析是一种常见的 NLP 任务,涉及确定一段文本中表达的情感或情绪。DistilBERT,特别是 DistilBertForSequenceClassification 模型,非常适合情感分析,因为它已经在大规模文本语料上进行了训练,对语言有很强的理解能力。通过在情感分析数据集上微调 DistilBERT,它可以准确地将文本分类为正面、负面或中性情感。
DistilBERT 分配给每个情感类别的概率可用于衡量文本中表达的情感强度。凭借其较小的体积和更快的推理时间,DistilBERT 是情感分析应用的理想选择,这些应用需要实时分析大量文本,例如社交媒体监控或客户反馈分析。
最大化 DistilBERT 能力的高级技巧
优化 DistilBERT 的速度和内存使用
为了最大化 DistilBERT 的速度和内存使用,建议利用 GPU 加速并优化代码以实现并行处理。这可以显著减少 DistilBERT 的推理时间,使其在实时应用中更高效。此外,使用量化(quantization)和剪枝(pruning)等技术可以进一步减少 DistilBERT 的内存使用,同时不影响其性能。
在自定义数据集上训练 DistilBERT 的最佳实践
在自定义数据集上训练 DistilBERT 时,遵循最佳实践以获得最佳结果非常重要。这包括正确预处理数据、确保类别分布平衡、以及使用适当的学习率和 epoch 数进行微调。数据增强技术,例如随机单词掩码或打乱,也可以应用于增加训练数据的多样性并提高模型的泛化能力。
优化 DistilBERT 的速度和内存使用
为了优化 DistilBERT 的速度和内存使用,可以应用多种技术。
首先,利用硬件加速(如 GPU)可以大大提高 DistilBERT 的推理速度。
此外,优化代码以实现并行处理并利用批处理(例如在非常大的批次上进行训练)可以进一步提升 DistilBERT 计算的速度。为了减少内存使用,可以使用量化(以较低精度近似网络权重)和权重剪枝(移除网络中的一些连接)等技术。
像 DistilBERT 这样的紧凑模型的未来
像 DistilBERT 这样的紧凑模型代表了 NLP 的未来,因为它们相比于大型模型提供了更高效、更具成本效益的解决方案。对设备端语言处理能力的需求正在增加,紧凑模型提供了一种可行的解决方案,可以在资源受限的设备上运行。
随着模型压缩技术研究的不断进步,我们可以期待更小、更快的模型,并在近年来的性能上有所改进。此外,像 DistilBERT 这样的预训练紧凑模型的可用性使开发人员能够快速部署 NLP 应用,而无需大量的计算资源。NLP 的未来将看到像 DistilBERT 这样的紧凑模型的广泛采用和发展,以满足实时语言处理的需求,并利用深度学习的力量。
正在进行的研究与局限性
学术界和工业界的研究小组都在继续探索 DistilBERT 的巨大潜力,同时认识到其局限性。大学和人工智能研究实验室正在深入研究该模型的复杂性,以增强其能力并扩展其适用性。
- 研究倡议:顶尖大学和人工智能研究小组正在合作,突破 DistilBERT 潜力的边界。
- 解决局限性:正在进行的研究侧重于改进长文本的上下文保留和细微语言理解。
- 模型优化:正在努力针对特定任务(如医学诊断和法律文档分析)优化 DistilBERT,在这些任务中精度至关重要。
然而,克服这些局限性是耗时的。您可以选择更好的模型,例如最近发布的 Llama 3,以节省时间完成工作。以下是 novita.ai LLM API 提供的模型:

立即免费试用我们的 LLM API:

结论
总之,DistilBERT 以其紧凑的设计和更高的效率彻底改变了 AI 模型的世界。通过从其前身 BERT 中蒸馏知识,它提供了更快、更轻量的替代方案,同时不牺牲准确性。
DistilBERT 在现实场景中的应用,如文本分类和情感分析,展示了其巨大的潜力。理解技术规格和性能指标对于优化其能力至关重要。随着我们深入探讨像 DistilBERT 这样的紧凑模型的未来,模型压缩技术的持续进步为 AI 开发和创新带来了令人兴奋的前景。敬请期待下一代 AI 模型,并探索未来的可能性。
novita.ai,一站式平台,为您提供无限创造力,可访问 100 多个 API。从图像生成、语言处理到音频增强和视频操作,按量付费,价格低廉,让您在构建自己产品的同时免去 GPU 维护的烦恼。立即免费试用。
推荐阅读



