

- Conceitos Principais por Trás do DistilBERT
- Especificações Técnicas do DistilBERT
- Aprimorando a Classificação de Texto com DistilBERT
- Aproveitando o DistilBERT para Análise de Sentimentos
- Otimizando o DistilBERT para Velocidade e Uso de Memória
- Melhores Práticas para Treinar o DistilBERT em Conjuntos de Dados Personalizados
- Pesquisas em Andamento e Limitações
Introdução
O DistilBERT é um modelo de linguagem revolucionário que visa tornar o processamento de linguagem em larga escala mais eficiente e econômico. Desenvolvido pela Hugging Face, o DistilBERT é uma versão destilada do BERT, um modelo de linguagem amplamente utilizado que melhorou significativamente o estado da arte em tarefas de PNL.
Modelos de linguagem como o BERT têm crescido em tamanho e complexidade, com modelos como o mais recente lançamento da Nvidia tendo 8,3 bilhões de parâmetros, 24 vezes maior que o BERT-large. Embora esses modelos maiores tenham levado a um melhor desempenho, eles vêm com custos ambientais e financeiros.
Compreendendo a Necessidade de Modelos Compactos
Modelos menores como o DistilBERT também têm vantagens práticas. Eles podem ser implantados em dispositivos com recursos limitados, como smartphones, sem comprometer o desempenho. Isso possibilita o desenvolvimento de aplicações do mundo real que podem ser executadas no dispositivo, reduzindo a necessidade de servidores GPU caros e garantindo a privacidade dos dados.
O tamanho menor do DistilBERT também resulta em tempos de inferência mais rápidos em CPU, tornando-o ideal para aplicações que exigem baixa latência e capacidade de resposta, como chatbots ou assistentes de voz. Isso é especialmente importante no campo do aprendizado de máquina, onde modelos compactos como o DistilBERT estão se tornando cada vez mais necessários para o processamento eficiente e eficaz no dispositivo.
O que é DistilBERT
O DistilBERT é uma versão destilada do BERT, o modelo de linguagem original baseado em transformer que revolucionou a PNL. Embora o BERT tenha alcançado um desempenho notável em várias tarefas de PNL, seu grande tamanho e requisitos computacionais tornam seu uso desafiador em ambientes com recursos limitados.
Conceitos Principais por Trás do DistilBERT
Os conceitos principais por trás do DistilBERT são destilação de conhecimento, vieses indutivos e a arquitetura transformer. A destilação de conhecimento é a técnica usada para comprimir um modelo maior, como o BERT, em um modelo menor, como o DistilBERT. Envolve treinar o modelo menor para imitar o comportamento do modelo maior.
Vieses indutivos referem-se às suposições ou conhecimento prévio incorporados na arquitetura e no processo de treinamento de um modelo. O DistilBERT se beneficia dos vieses indutivos aprendidos pelo BERT durante o pré-treinamento, permitindo que ele generalize bem para várias tarefas de PNL.
A arquitetura transformer, originalmente introduzida por Vaswani et al., forma a base tanto do BERT quanto do DistilBERT. Consiste em mecanismos de autoatenção que capturam o contexto e as relações entre palavras em uma frase, permitindo que os modelos entendam e gerem linguagem natural.
O Mecanismo de Destilação de Conhecimento no DistilBERT
O mecanismo de destilação de conhecimento no DistilBERT envolve treinar o modelo aluno para imitar a distribuição de saída do modelo professor. Durante o treinamento, o modelo aluno aprende a produzir probabilidades semelhantes para cada classe que o modelo professor.
O processo de destilação consiste em minimizar a diferença entre os logits (pontuações de saída antes da aplicação do softmax) dos modelos aluno e professor. O modelo aluno é treinado para prever as mesmas altas probabilidades para as classes corretas que o modelo professor.
Ao incorporar o conhecimento do modelo professor, o modelo aluno é capaz de aproximar o comportamento do modelo maior e alcançar desempenho semelhante em tarefas downstream. Esse processo de destilação permite a compressão do conhecimento aprendido pelo modelo professor em um modelo menor e mais eficiente como o DistilBERT.
Especificações Técnicas do DistilBERT
O DistilBERT possui várias especificações técnicas que o tornam um modelo mais compacto e eficiente em comparação com o BERT. Ele tem aproximadamente 40% menos parâmetros que o BERT, tornando-o mais leve e mais adequado para computações no dispositivo.
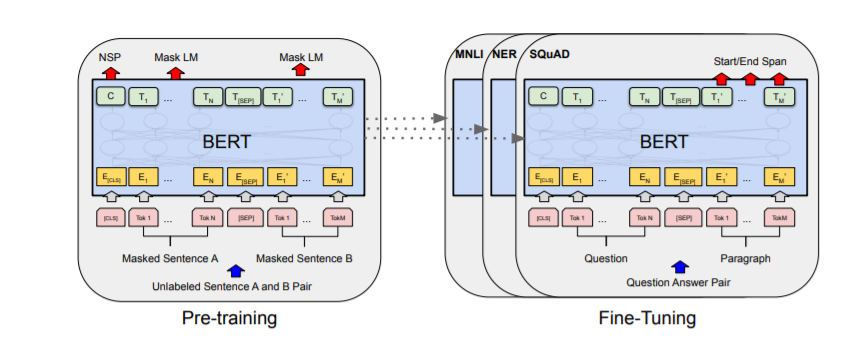
Em termos de inferência, o DistilBERT é significativamente mais rápido que o BERT, com uma redução de 60% no tempo de inferência. Isso permite um processamento mais eficiente de dados de texto e possibilita aplicações em tempo real.
O DistilBERT alcança essas melhorias em eficiência e velocidade utilizando destilação de conhecimento e incorporando vieses indutivos aprendidos pelo modelo maior. Essas especificações técnicas tornam o DistilBERT uma ferramenta valiosa para tarefas de PNL que exigem processamento de linguagem rápido e eficiente.
DistilBERT vs. BERT: Uma Análise Comparativa
Uma análise comparativa entre DistilBERT e BERT revela diferenças chave em desempenho, tamanho do modelo e tempo de treinamento. Enquanto o DistilBERT é uma versão comprimida do BERT, ele retém 97% do desempenho do BERT em várias tarefas de PNL.

O tamanho menor do modelo DistilBERT o torna mais eficiente em termos de uso de memória e requisitos de armazenamento. Isso possibilita tempos de treinamento e inferência mais rápidos em comparação com o BERT.
Apesar da redução no tamanho do modelo, o DistilBERT mantém alto desempenho em uma ampla gama de tarefas de PNL, tornando-o uma alternativa adequada para aplicações com recursos limitados ou restrições computacionais mais rigorosas.

Métricas de Desempenho: Eficiência e Precisão do DistilBERT
O desempenho do DistilBERT pode ser avaliado com base em sua eficiência e precisão em várias tarefas downstream. Quando comparado ao BERT, o DistilBERT demonstra desempenho comparável ou até melhor, enquanto é um modelo mais eficiente e leve.
O DistilBERT tem bom desempenho no benchmark GLUE (General Language Understanding Evaluation), que consiste em múltiplas tarefas downstream de PNL. Ele alcança alta precisão e pontuações F1 em tarefas como análise de sentimentos, classificação de texto e resposta a perguntas.
A eficiência do DistilBERT é refletida em seu tamanho menor de modelo e tempos de inferência mais rápidos. Isso o torna mais adequado para aplicações em tempo real, onde baixa latência e capacidade de resposta são cruciais. Além disso, os requisitos computacionais reduzidos do DistilBERT contribuem para um menor impacto ambiental, tornando-o uma escolha mais sustentável para tarefas de PNL.
Como Implementar o DistilBERT
A biblioteca Transformers da Huggingface fornece uma gama de modelos DistilBERT em várias versões e tamanhos. Neste guia, demonstraremos como carregar um modelo e realizar classificação de rótulo único.
Primeiro, instalaremos e importaremos os pacotes necessários. Em seguida, carregaremos o modelo “distilbert-base-uncased-finetuned-sst-2-english” junto com seu tokenizador usando DistilBertForSequenceClassification e DistilBertTokenizer, respectivamente. Depois, tokenizaremos os dados de entrada e usaremos a saída tokenizada para prever o rótulo, que neste exemplo é análise de sentimentos.
!pip install -q transformersimport torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassificationtokenizer = DistilBertTokenizer.from_pretrained(“distilbert-base-uncased-finetuned-sst-2-english”)
model = DistilBertForSequenceClassification.from_pretrained(“distilbert-base-uncased-finetuned-sst-2-english”)inputs = tokenizer(“Uau! Que surpresa!”, return_tensors=“pt”)with torch.inference_mode():
logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
DistilBERT em Ação: Estudos de Caso
O DistilBERT foi aplicado com sucesso em vários estudos de caso, demonstrando sua eficácia em diferentes tarefas de PNL. Dois exemplos notáveis são análise de sentimentos e classificação de texto.
Aprimorando a Classificação de Texto com DistilBERT
O DistilBERT pode aprimorar significativamente as tarefas de classificação de texto, fornecendo previsões precisas de maneira mais rápida e eficiente. Ele usa a mesma arquitetura do BERT, mas com menos camadas e embeddings de tipo de token removidos e pooler.
Apesar dessas mudanças, o DistilBERT retém 95% do desempenho do BERT no benchmark GLUE para compreensão de linguagem. Isso torna o DistilBERT uma ferramenta poderosa para várias tarefas de classificação de texto, incluindo análise de sentimentos, reconhecimento de entidades nomeadas e detecção de intenção.
Aproveitando o DistilBERT para Análise de Sentimentos
A análise de sentimentos é uma tarefa comum de PNL que envolve determinar o sentimento ou emoção expressa em um trecho de texto. O DistilBERT, especificamente o modelo DistilBertForSequenceClassification, é bem adequado para análise de sentimentos, pois foi treinado em um grande corpus de texto e possui um forte entendimento da linguagem. Ao ajustar o DistilBERT em um conjunto de dados de análise de sentimentos, ele pode classificar com precisão o texto em sentimentos positivos, negativos ou neutros.
As probabilidades atribuídas a cada classe de sentimento pelo DistilBERT podem ser usadas para medir a força do sentimento expresso no texto. Com seu tamanho menor e tempo de inferência mais rápido, o DistilBERT é uma escolha ideal para aplicações de análise de sentimentos que exigem análise em tempo real de grandes volumes de texto, como monitoramento de mídias sociais ou análise de feedback de clientes.
Dicas Avançadas para Maximizar as Capacidades do DistilBERT
Otimizando o DistilBERT para Velocidade e Uso de Memória
Para maximizar a velocidade e o uso de memória do DistilBERT, recomenda-se utilizar aceleração por GPU e otimizar o código para processamento paralelo. Isso pode reduzir significativamente o tempo de inferência do DistilBERT, tornando-o mais eficiente para aplicações em tempo real. Além disso, técnicas como quantização e poda podem reduzir ainda mais o uso de memória do DistilBERT sem comprometer seu desempenho.
Melhores Práticas para Treinar o DistilBERT em Conjuntos de Dados Personalizados
Ao treinar o DistilBERT em conjuntos de dados personalizados, é importante seguir as melhores práticas para alcançar resultados ideais. Isso inclui pré-processar adequadamente os dados, garantir uma distribuição equilibrada das classes e ajustar o modelo com uma taxa de aprendizado e número de épocas apropriados. Técnicas de aumento de dados, como mascaramento aleatório de palavras ou embaralhamento, também podem ser aplicadas para aumentar a diversidade dos dados de treinamento e melhorar a capacidade de generalização do modelo.
Otimizando o DistilBERT para Velocidade e Uso de Memória
Para otimizar o DistilBERT para velocidade e uso de memória, existem várias técnicas que podem ser aplicadas.
Primeiro, utilizar aceleração de hardware, como GPUs, pode melhorar muito a velocidade de inferência do DistilBERT.
Além disso, otimizar o código para processamento paralelo e aproveitar o processamento em lote, como treinar em lotes muito grandes, pode aumentar ainda mais a velocidade das computações do DistilBERT. Para reduzir o uso de memória, técnicas como quantização (aproximar os pesos de uma rede com uma precisão menor) e poda de pesos (remover algumas conexões na rede) podem ser usadas.
O Futuro dos Modelos Compactos como o DistilBERT
Modelos compactos como o DistilBERT representam o futuro da PNL, pois oferecem uma solução mais eficiente e econômica em comparação com modelos maiores. A demanda por capacidades de processamento de linguagem no dispositivo está aumentando, e modelos compactos fornecem uma solução viável que pode ser executada em dispositivos com recursos limitados.
À medida que a pesquisa em técnicas de compressão de modelos continua a avançar, podemos esperar modelos ainda menores e mais rápidos com desempenho melhorado nos últimos anos. Além disso, a disponibilidade de modelos compactos pré-treinados como o DistilBERT permite que desenvolvedores implantem rapidamente aplicações de PNL sem a necessidade de recursos computacionais extensos. O futuro da PNL verá a adoção generalizada e o desenvolvimento de modelos compactos, como o DistilBERT, para atender às demandas do processamento de linguagem em tempo real usando o poder do aprendizado profundo.
Pesquisas em Andamento e Limitações
Grupos de pesquisa acadêmica e industrial continuam explorando o vasto potencial do DistilBERT, reconhecendo suas limitações. Universidades e laboratórios de pesquisa em IA estão investigando as complexidades do modelo para aprimorar suas capacidades e ampliar sua aplicabilidade.
- Iniciativas de Pesquisa: Universidades líderes e grupos de pesquisa em IA estão colaborando para expandir os limites do potencial do DistilBERT.
- Abordando Limitações: A pesquisa em andamento foca em melhorar a retenção de contexto em textos mais longos e a compreensão de linguagem sutil.
- Refinamento do Modelo: Esforços estão sendo feitos para refinar o DistilBERT para tarefas específicas, como diagnóstico médico e análise de documentos jurídicos, onde a precisão é crucial.
No entanto, superar essas limitações é demorado. Você pode escolher modelos melhores, como o Llama 3 lançado recentemente, para realizar seu trabalho economizando tempo. Aqui está a API LLM da novita.ai apresentando modelos:

Experimente nossa API LLM gratuitamente agora:

Conclusão
Em conclusão, o DistilBERT revolucionou o mundo dos modelos de IA com seu design compacto e eficiência aprimorada. Ao destilar conhecimento de seu predecessor BERT, ele oferece uma alternativa mais rápida e leve sem comprometer a precisão.
A aplicação do DistilBERT em cenários do mundo real, como classificação de texto e análise de sentimentos, demonstra seu imenso potencial. É crucial compreender as especificações técnicas e métricas de desempenho para aproveitar suas capacidades de forma ideal. À medida que nos aprofundamos no futuro de modelos compactos como o DistilBERT, os avanços contínuos nas técnicas de compressão de modelos prometem perspectivas empolgantes para o desenvolvimento e inovação em IA. Fique atento à próxima geração de modelos de IA e explore as possibilidades que o aguardam.
novita.ai, a plataforma completa para criatividade ilimitada que lhe dá acesso a mais de 100 APIs. De geração de imagens e processamento de linguagem a aprimoramento de áudio e manipulação de vídeo, com preço acessível pay-as-you-go, ela libera você das preocupações com manutenção de GPU enquanto constrói seus próprios produtos. Experimente gratuitamente.
Leitura recomendada
Novita AI LLM Inference Engine: a maior taxa de transferência e a inferência mais barata disponível



