

- Kernkonzepte hinter DistilBERT
- Technische Spezifikationen von DistilBERT
- Textklassifikation mit DistilBERT verbessern
- DistilBERT für die Stimmungsanalyse nutzen
- Optimierung von DistilBERT für Geschwindigkeit und Speichernutzung
- Best Practices für das Training von DistilBERT auf benutzerdefinierten Datensätzen
- Laufende Forschung und Einschränkungen
Einleitung
DistilBERT ist ein revolutionäres Sprachmodell, das darauf abzielt, die großflächige Sprachverarbeitung effizienter und kostengünstiger zu gestalten. Entwickelt von Hugging Face, ist DistilBERT eine destillierte Version von BERT, einem weit verbreiteten Sprachmodell, das den Stand der Technik bei NLP-Aufgaben erheblich verbessert hat.
Sprachmodelle wie BERT sind in Größe und Komplexität gewachsen, wobei Modelle wie Nvidias neueste Veröffentlichung 8,3 Milliarden Parameter haben – 24 Mal größer als BERT-large. Während diese größeren Modelle zu einer besseren Leistung geführt haben, sind sie mit Umwelt- und finanziellen Kosten verbunden.
Das Verständnis der Notwendigkeit kompakter Modelle
Kleinere Modelle wie DistilBERT haben auch praktische Vorteile. Sie können auf ressourcenbeschränkten Geräten wie Smartphones eingesetzt werden, ohne die Leistung zu beeinträchtigen. Dies ermöglicht die Entwicklung von realen Anwendungen, die auf dem Gerät ausgeführt werden können, wodurch der Bedarf an teuren GPU-Servern reduziert und die Privatsphäre der Daten gewährleistet wird.
Die geringere Größe von DistilBERT führt auch zu schnelleren Inferenzzeiten auf der CPU, was es ideal für Anwendungen macht, die niedrige Latenz und Reaktionsfähigkeit erfordern, wie Chatbots oder Sprachassistenten. Dies ist besonders wichtig im Bereich des maschinellen Lernens, wo kompakte Modelle wie DistilBERT für eine effiziente und effektive Verarbeitung auf dem Gerät zunehmend notwendig werden.
Was ist DistilBERT
DistilBERT ist eine destillierte Version von BERT, dem ursprünglichen transformer-basierten Sprachmodell, das die NLP revolutioniert hat. Während BERT bemerkenswerte Leistungen bei verschiedenen NLP-Aufgaben erzielt hat, machen seine Größe und die hohen Rechenanforderungen den Einsatz in ressourcenbeschränkten Umgebungen schwierig.
Kernkonzepte hinter DistilBERT
Die Kernkonzepte hinter DistilBERT sind Wissensdestillation, induktive Verzerrungen und die Transformer-Architektur. Wissensdestillation ist die Technik, die verwendet wird, um ein größeres Modell wie BERT in ein kleineres Modell wie DistilBERT zu komprimieren. Dabei wird das kleinere Modell trainiert, das Verhalten des größeren Modells nachzuahmen.
Induktive Verzerrungen beziehen sich auf die Annahmen oder das Vorwissen, das in der Architektur und dem Trainingsprozess eines Modells eingebettet ist. DistilBERT profitiert von den induktiven Verzerrungen, die BERT während des Vortrainings gelernt hat, und kann so gut auf verschiedene NLP-Aufgaben verallgemeinern.
Die Transformer-Architektur, ursprünglich von Vaswani et al. eingeführt, bildet die Grundlage sowohl für BERT als auch für DistilBERT. Sie besteht aus Selbstaufmerksamkeitsmechanismen, die den Kontext und die Beziehungen zwischen Wörtern in einem Satz erfassen, sodass die Modelle natürliche Sprache verstehen und generieren können.
Der Mechanismus der Wissensdestillation in DistilBERT
Der Mechanismus der Wissensdestillation in DistilBERT besteht darin, das Schülermodell so zu trainieren, dass es die Ausgabeverteilung des Lehrermodells nachahmt. Während des Trainings lernt das Schülermodell, ähnliche Wahrscheinlichkeiten für jede Klasse zu erzeugen wie das Lehrermodell.
Der Destillationsprozess besteht darin, die Differenz zwischen den Logits (Ausgabewerte vor Anwendung von Softmax) des Schüler- und des Lehrermodells zu minimieren. Das Schülermodell wird trainiert, die gleichen hohen Wahrscheinlichkeiten für die richtigen Klassen vorherzusagen wie das Lehrermodell.
Durch die Einbeziehung des Wissens aus dem Lehrermodell kann das Schülermodell das Verhalten des größeren Modells annähern und eine ähnliche Leistung bei nachgelagerten Aufgaben erzielen. Dieser Destillationsprozess ermöglicht die Komprimierung des vom Lehrermodell gelernten Wissens in ein kleineres und effizienteres Modell wie DistilBERT.
Technische Spezifikationen von DistilBERT
DistilBERT hat mehrere technische Spezifikationen, die es im Vergleich zu BERT zu einem kompakteren und effizienteren Modell machen. Es hat etwa 40 % weniger Parameter als BERT, was es leichter und besser für Berechnungen auf dem Gerät geeignet macht.
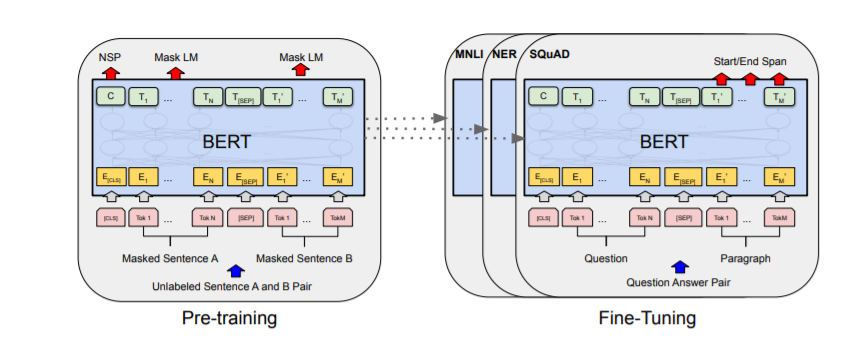
In Bezug auf die Inferenz ist DistilBERT deutlich schneller als BERT, mit einer Reduzierung der Inferenzzeit um 60 %. Dies ermöglicht eine effizientere Verarbeitung von Textdaten und ermöglicht Echtzeitanwendungen.
DistilBERT erreicht diese Verbesserungen in Effizienz und Geschwindigkeit durch den Einsatz von Wissensdestillation und die Einbeziehung induktiver Verzerrungen, die vom größeren Modell gelernt wurden. Diese technischen Spezifikationen machen DistilBERT zu einem wertvollen Werkzeug für NLP-Aufgaben, die eine schnelle und effiziente Sprachverarbeitung erfordern.
DistilBERT vs. BERT: Eine vergleichende Analyse
Eine vergleichende Analyse zwischen DistilBERT und BERT zeigt wesentliche Unterschiede in der Leistung, Modellgröße und Trainingszeit. Während DistilBERT eine komprimierte Version von BERT ist, behält es 97 % der Leistung von BERT bei verschiedenen NLP-Aufgaben.

Die geringere Modellgröße von DistilBERT macht es effizienter in Bezug auf Speichernutzung und Speicheranforderungen. Dies ermöglicht schnellere Trainings- und Inferenzzeiten im Vergleich zu BERT.
Trotz der Reduzierung der Modellgröße behält DistilBERT eine hohe Leistung bei einer breiten Palette von NLP-Aufgaben bei, was es zu einer geeigneten Alternative für Anwendungen mit begrenzten Ressourcen oder strengeren Rechenbeschränkungen macht.

Leistungskennzahlen: Effizienz und Genauigkeit von DistilBERT
Die Leistung von DistilBERT kann anhand seiner Effizienz und Genauigkeit bei verschiedenen nachgelagerten Aufgaben bewertet werden. Im Vergleich zu BERT zeigt DistilBERT eine vergleichbare oder sogar bessere Leistung, während es ein effizienteres und leichteres Modell ist.
DistilBERT schneidet beim General Language Understanding Evaluation (GLUE) Benchmark gut ab, der aus mehreren nachgelagerten NLP-Aufgaben besteht. Es erzielt hohe Genauigkeits- und F1-Werte bei Aufgaben wie Stimmungsanalyse, Textklassifikation und Fragebeantwortung.
Die Effizienz von DistilBERT spiegelt sich in seiner geringeren Modellgröße und schnelleren Inferenzzeiten wider. Dies macht es besser geeignet für Echtzeitanwendungen, bei denen niedrige Latenz und Reaktionsfähigkeit entscheidend sind. Darüber hinaus tragen die reduzierten Rechenanforderungen von DistilBERT zu einer geringeren Umweltbelastung bei, was es zu einer nachhaltigeren Wahl für NLP-Aufgaben macht.
Wie man DistilBERT implementiert
Die Transformers-Bibliothek von Hugging Face bietet eine Reihe von DistilBERT-Modellen in verschiedenen Versionen und Größen. In dieser Anleitung zeigen wir, wie man ein Modell lädt und eine Single-Label-Klassifikation durchführt.
Zuerst installieren und importieren wir die erforderlichen Pakete. Dann laden wir das Modell „distilbert-base-uncased-finetuned-sst-2-english“ zusammen mit seinem Tokenizer, und zwar mit DistilBertForSequenceClassification bzw. DistilBertTokenizer. Als nächstes tokenisieren wir die Eingabedaten und verwenden die tokenisierte Ausgabe, um das Label vorherzusagen, das in diesem Beispiel die Stimmungsanalyse ist.
!pip install -q transformers
import torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
inputs = tokenizer("Wow! What a surprise!", return_tensors="pt")
with torch.inference_mode():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
DistilBERT in Aktion: Fallstudien
DistilBERT wurde erfolgreich in verschiedenen Fallstudien eingesetzt und hat seine Wirksamkeit bei unterschiedlichen NLP-Aufgaben unter Beweis gestellt. Zwei bemerkenswerte Beispiele sind die Stimmungsanalyse und die Textklassifikation.
Textklassifikation mit DistilBERT verbessern
DistilBERT kann Textklassifikationsaufgaben erheblich verbessern, indem es genaue Vorhersagen auf schnellere und effizientere Weise liefert. Es verwendet die gleiche Architektur wie BERT, jedoch mit weniger Schichten und entfernten Token-Typ-Embeddings und Pooler.
Trotz dieser Änderungen behält DistilBERT 95 % der Leistung von BERT beim GLUE-Benchmark für Sprachverständnis. Dies macht DistilBERT zu einem leistungsstarken Werkzeug für verschiedene Textklassifikationsaufgaben, einschließlich Stimmungsanalyse, Named Entity Recognition und Absichtserkennung.
DistilBERT für die Stimmungsanalyse nutzen
Die Stimmungsanalyse ist eine häufige NLP-Aufgabe, bei der die Stimmung oder Emotion in einem Text bestimmt wird. DistilBERT, insbesondere das Modell DistilBertForSequenceClassification, ist für die Stimmungsanalyse gut geeignet, da es auf einem großen Textkorpus trainiert wurde und ein starkes Sprachverständnis besitzt. Durch Feintuning von DistilBERT auf einem Stimmungsanalyse-Datensatz kann es Texte genau in positive, negative oder neutrale Stimmungen einteilen.
Die von DistilBERT für jede Stimmungsklasse zugewiesenen Wahrscheinlichkeiten können verwendet werden, um die Stärke der im Text ausgedrückten Stimmung zu messen. Aufgrund seiner geringeren Größe und schnelleren Inferenzzeit ist DistilBERT eine ideale Wahl für Stimmungsanalyse-Anwendungen, die eine Echtzeitanalyse großer Textmengen erfordern, wie z. B. Social-Media-Überwachung oder Kundenfeedback-Analyse.
Fortgeschrittene Tipps zur Maximierung der Fähigkeiten von DistilBERT
Optimierung von DistilBERT für Geschwindigkeit und Speichernutzung
Um die Geschwindigkeit und Speichernutzung von DistilBERT zu maximieren, wird empfohlen, GPU-Beschleunigung zu nutzen und den Code für die Parallelverarbeitung zu optimieren. Dies kann die Inferenzzeit von DistilBERT erheblich reduzieren und es für Echtzeitanwendungen effizienter machen. Darüber hinaus können Techniken wie Quantisierung und Pruning die Speichernutzung von DistilBERT weiter reduzieren, ohne die Leistung zu beeinträchtigen.
Best Practices für das Training von DistilBERT auf benutzerdefinierten Datensätzen
Beim Training von DistilBERT auf benutzerdefinierten Datensätzen ist es wichtig, Best Practices zu befolgen, um optimale Ergebnisse zu erzielen. Dazu gehören die ordnungsgemäße Vorverarbeitung der Daten, die Sicherstellung einer ausgewogenen Verteilung der Klassen und das Feintuning des Modells mit einer geeigneten Lernrate und Anzahl von Epochen. Auch Datenanreicherungstechniken wie zufälliges Maskieren von Wörtern oder Mischen können angewendet werden, um die Vielfalt der Trainingsdaten zu erhöhen und die Generalisierungsfähigkeit des Modells zu verbessern.
Optimierung von DistilBERT für Geschwindigkeit und Speichernutzung
Um DistilBERT für Geschwindigkeit und Speichernutzung zu optimieren, können verschiedene Techniken angewendet werden.
Erstens kann die Nutzung von Hardwarebeschleunigung wie GPUs die Inferenzgeschwindigkeit von DistilBERT erheblich verbessern.
Zusätzlich können die Optimierung des Codes für Parallelverarbeitung und die Nutzung von Batch-Verarbeitung, wie das Training mit sehr großen Batches, die Geschwindigkeit der Berechnungen von DistilBERT weiter erhöhen. Um die Speichernutzung zu reduzieren, können Techniken wie Quantisierung (Annäherung der Gewichte eines Netzwerks mit geringerer Genauigkeit) und Pruning (Entfernen einiger Verbindungen im Netzwerk) verwendet werden.
Die Zukunft kompakter Modelle wie DistilBERT
Kompakte Modelle wie DistilBERT repräsentieren die Zukunft der NLP, da sie eine effizientere und kostengünstigere Lösung im Vergleich zu größeren Modellen bieten. Die Nachfrage nach Sprachverarbeitungsfähigkeiten auf dem Gerät steigt, und kompakte Modelle bieten eine praktikable Lösung, die auf ressourcenbeschränkten Geräten ausgeführt werden kann.
Mit dem Fortschritt der Forschung an Modellkompressionstechniken können wir in den letzten Jahren noch kleinere und schnellere Modelle mit verbesserter Leistung erwarten. Darüber hinaus ermöglicht die Verfügbarkeit vortrainierter kompakter Modelle wie DistilBERT Entwicklern, NLP-Anwendungen schnell bereitzustellen, ohne umfangreiche Rechenressourcen zu benötigen. Die Zukunft der NLP wird die weitverbreitete Übernahme und Entwicklung kompakter Modelle wie DistilBERT sehen, um den Anforderungen der Echtzeit-Sprachverarbeitung mit der Kraft des Deep Learning gerecht zu werden.
Laufende Forschung und Einschränkungen
Sowohl akademische als auch industrielle Forschungsgruppen erforschen weiterhin das enorme Potenzial von DistilBERT und erkennen gleichzeitig seine Grenzen. Universitäten und KI-Forschungslabore untersuchen die Feinheiten des Modells, um seine Fähigkeiten zu verbessern und seine Anwendbarkeit zu erweitern.
- Forschungsinitiativen: Führende Universitäten und KI-Forschungsgruppen arbeiten zusammen, um die Grenzen des Potenzials von DistilBERT zu erweitern.
- Adressierung von Einschränkungen: Die laufende Forschung konzentriert sich auf die Verbesserung der Kontexterhaltung über längere Texte und das nuancierte Sprachverständnis.
- Modellverfeinerung: Es werden Anstrengungen unternommen, DistilBERT für spezifische Aufgaben wie medizinische Diagnose und juristische Dokumentenanalyse zu verfeinern, bei denen Präzision entscheidend ist.
Es ist jedoch zeitaufwändig, diese Einschränkungen zu überwinden. Sie können bessere Modelle wie das kürzlich veröffentlichte Llama 3 wählen, um Ihre Arbeit mit Zeitersparnis zu erledigen. Hier ist die LLM-API von novita.ai mit Modellen:

Probieren Sie unsere LLM-API jetzt kostenlos aus:

Fazit
Zusammenfassend hat DistilBERT die Welt der KI-Modelle mit seinem kompakten Design und seiner verbesserten Effizienz revolutioniert. Durch die Destillation von Wissen aus seinem Vorgänger BERT bietet es eine schnellere und leichtere Alternative, ohne die Genauigkeit zu beeinträchtigen.
Die Anwendung von DistilBERT in realen Szenarien wie Textklassifikation und Stimmungsanalyse zeigt sein immenses Potenzial. Es ist entscheidend, die technischen Spezifikationen und Leistungskennzahlen zu verstehen, um seine Fähigkeiten optimal zu nutzen. Während wir uns mit der Zukunft kompakter Modelle wie DistilBERT befassen, versprechen kontinuierliche Fortschritte bei Modellkompressionstechniken aufregende Perspektiven für die Entwicklung und Innovation von KI. Bleiben Sie gespannt auf die nächste Generation von KI-Modellen und erkunden Sie die Möglichkeiten, die uns erwarten.
novita.ai, die One-Stop-Plattform für grenzenlose Kreativität, die Ihnen Zugang zu über 100 APIs bietet. Von Bildgenerierung und Sprachverarbeitung bis hin zur Audioverbesserung und Videobearbeitung – mit einem günstigen Pay-as-you-go-Modell werden Sie von der GPU-Wartung befreit, während Sie Ihre eigenen Produkte entwickeln. Probieren Sie es kostenlos aus.
Empfohlene Lektüre
Novita AI LLM Inference Engine: Der größte Durchsatz und die günstigste Inferenz, die verfügbar ist



