

はじめに
DistilBERT は、大規模言語処理をより効率的かつコスト効果の高いものにする革新的な言語モデルです。Hugging Face によって開発された DistilBERT は、NLP タスクの最先端を大幅に向上させてきた広く使われている言語モデル BERT の蒸留版です。
BERT のような言語モデルは、サイズと複雑さが増大しており、Nvidia の最新リリースでは 83 億パラメータ(BERT-large の 24 倍)を誇ります。これらの大規模モデルは性能向上につながっていますが、環境面とコスト面での負担が伴います。
コンパクトなモデルの必要性を理解する
DistilBERT のような小型モデルには実用的な利点もあります。性能を損なうことなく、スマートフォンのようなリソース制約のあるデバイスに展開できます。これにより、デバイス上で動作する実世界のアプリケーションの開発が可能になり、高価な GPU サーバーの必要性が減り、データプライバシーが確保されます。
DistilBERT の小型サイズは CPU での推論時間の短縮にもつながり、チャットボットや音声アシスタントのように低レイテンシと応答性が求められるアプリケーションに最適です。これは機械学習の分野において特に重要であり、DistilBERT のようなコンパクトなモデルは、効率的かつ効果的なデバイス上処理のためにますます必要とされています。
DistilBERT とは
DistilBERT は、NLP に革命をもたらしたオリジナルの Transformer ベース言語モデル BERT の蒸留版です。BERT はさまざまな NLP タスクで目覚ましい性能を達成してきましたが、そのサイズの大きさと計算要件の高さから、リソース制約のある環境での使用は困難です。
DistilBERT の背後にある中核的概念
DistilBERT の背後にある中核的概念は、知識蒸留、帰納的バイアス、および Transformer アーキテクチャです。知識蒸留は、BERT のような大規模モデルを DistilBERT のような小型モデルに圧縮するために使用される手法です。これは、小型モデルが大規模モデルの振る舞いを模倣するように訓練することを含みます。
帰納的バイアスとは、モデルのアーキテクチャと訓練プロセスに組み込まれた仮定または事前知識を指します。DistilBERT は、BERT が事前学習中に学習した帰納的バイアスの恩恵を受けており、さまざまな NLP タスクにうまく汎化できます。
Transformer アーキテクチャは、Vaswani らによって最初に導入され、BERT と DistilBERT の両方の基盤を形成しています。これは、文中の単語間のコンテキストと関係を捉える自己注意メカニズムで構成されており、モデルが自然言語を理解し生成することを可能にします。
DistilBERT における知識蒸留のメカニズム
DistilBERT における知識蒸留のメカニズムは、生徒モデルが教師モデルの出力分布を模倣するように訓練することを含みます。訓練中、生徒モデルは教師モデルと同じように各クラスに対して類似した確率を生成することを学習します。
蒸留プロセスは、生徒モデルと教師モデルのロジット(ソフトマックス適用前の出力スコア)の差を最小化することで構成されます。生徒モデルは、教師モデルが正しいクラスに対して高い確率を予測するのと同じように、高い確率を予測するように訓練されます。
教師モデルの知識を取り入れることで、生徒モデルは大規模モデルの振る舞いを近似し、下流タスクで同様の性能を達成できます。この蒸留プロセスにより、教師モデルが学習した知識を DistilBERT のようなより小型で効率的なモデルに圧縮することが可能になります。
DistilBERT の技術仕様
DistilBERT には、BERT と比較してよりコンパクトで効率的なモデルにするためのいくつかの技術仕様があります。パラメータ数は BERT より約 40% 少なく、より軽量でデバイス上の計算に適しています。
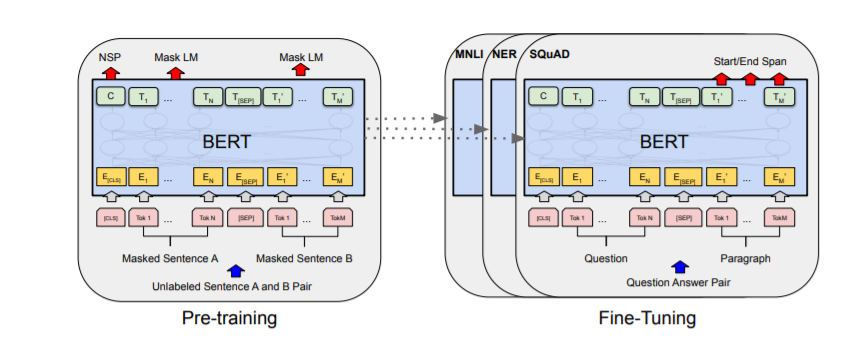
推論に関しては、DistilBERT は BERT よりも大幅に高速で、推論時間が 60% 削減されます。これにより、テキストデータのより効率的な処理が可能になり、リアルタイムアプリケーションが実現します。
DistilBERT は、知識蒸留を活用し、大規模モデルによって学習された帰納的バイアスを取り入れることで、これらの効率性と速度の向上を達成しています。これらの技術仕様により、DistilBERT は高速で効率的な言語処理を必要とする NLP タスクにとって貴重なツールとなっています。
DistilBERT と BERT:比較分析
DistilBERT と BERT の比較分析により、性能、モデルサイズ、トレーニング時間における主要な違いが明らかになります。DistilBERT は BERT の圧縮版ですが、さまざまな NLP タスクにおいて BERT の性能の 97% を保持しています。

DistilBERT の小型モデルサイズは、メモリ使用量とストレージ要件の点でより効率的です。これにより、BERT と比較してより高速なトレーニングと推論時間が可能になります。
モデルサイズの削減にもかかわらず、DistilBERT は幅広い NLP タスクで高い性能を維持しており、リソースが限られている、またはより厳しい計算制約があるアプリケーションにとって適切な代替手段となります。

パフォーマンス指標:DistilBERT の効率性と精度
DistilBERT の性能は、さまざまな下流タスクにおける効率性と精度に基づいて評価できます。BERT と比較すると、DistilBERT はより効率的で軽量なモデルでありながら、同等またはそれ以上の性能を示します。
DistilBERT は、複数の下流 NLP タスクからなる GLUE ベンチマークで良好なパフォーマンスを発揮します。感情分析、テキスト分類、質問応答などのタスクで高い精度と F1 スコアを達成します。
DistilBERT の効率性は、より小さなモデルサイズとより高速な推論時間に表れています。これにより、低レイテンシと応答性が重要なリアルタイムアプリケーションにより適しています。さらに、DistilBERT の計算要件の低減は環境負荷の低減に貢献し、NLP タスクにとってより持続可能な選択肢となります。
DistilBERT の実装方法
Huggingface の Transformers ライブラリは、さまざまなバージョンとサイズの DistilBERT モデルを提供しています。このガイドでは、モデルをロードしてシングルラベル分類を実行する方法を説明します。
まず、必要なパッケージをインストールしてインポートします。次に、DistilBertForSequenceClassification と DistilBertTokenizer を使用して、“distilbert-base-uncased-finetuned-sst-2-english” モデルとそのトークナイザをロードします。次に、入力データをトークナイズし、トークナイズされた出力を使用してラベルを予測します。この例では感情分析です。
!pip install -q transformersimport torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassificationtokenizer = DistilBertTokenizer.from_pretrained(“distilbert-base-uncased-finetuned-sst-2-english”)
model = DistilBertForSequenceClassification.from_pretrained(“distilbert-base-uncased-finetuned-sst-2-english”)inputs = tokenizer(“Wow! What a surprise!”, return_tensors=“pt”)with torch.inference_mode():
logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
DistilBERT の実際の活用事例
DistilBERT はさまざまな事例研究で成功裏に適用され、さまざまな NLP タスクでの有効性が実証されています。注目すべき2つの例は、感情分析とテキスト分類です。
テキスト分類の強化における DistilBERT の活用
DistilBERT は、より高速かつ効率的な方法で正確な予測を提供することにより、テキスト分類タスクを大幅に強化できます。BERT と同じアーキテクチャを使用しますが、レイヤー数が少なく、トークンタイプ埋め込みとプーラーが削除されています。
これらの変更にもかかわらず、DistilBERT は言語理解の GLUE ベンチマークにおいて BERT の性能の 95% を保持しています。これにより、DistilBERT は感情分析、固有表現認識、インテント検出など、さまざまなテキスト分類タスクのための強力なツールとなっています。
感情分析のための DistilBERT の活用
感情分析は、テキストで表現された感情や気持ちを判断する一般的な NLP タスクです。DistilBERT、特に DistilBertForSequenceClassification モデルは、大規模なテキストコーパスでトレーニングされ、言語に対する強力な理解を持っているため、感情分析に適しています。感情分析データセットで DistilBERT を微調整することにより、テキストをポジティブ、ネガティブ、またはニュートラルな感情に正確に分類できます。
DistilBERT によって各感情クラスに割り当てられた確率は、テキストで表現された感情の強さを評価するために使用できます。DistilBERT はサイズが小さく推論時間が速いため、ソーシャルメディアのモニタリングや顧客フィードバック分析など、大量のテキストをリアルタイムで分析する必要がある感情分析アプリケーションに理想的な選択肢です。
DistilBERT の能力を最大化するための高度なヒント
速度とメモリ使用量の最適化
DistilBERT の速度とメモリ使用量を最大化するには、GPU アクセラレーションを利用し、並列処理のためにコードを最適化することをお勧めします。これにより、DistilBERT の推論時間が大幅に短縮され、リアルタイムアプリケーションにより効率的になります。さらに、量子化やプルーニングなどの手法を使用することで、性能を損なうことなく DistilBERT のメモリ使用量をさらに削減できます。
カスタムデータセットでの DistilBERT トレーニングのベストプラクティス
カスタムデータセットで DistilBERT をトレーニングする場合は、最適な結果を得るためにベストプラクティスに従うことが重要です。これには、データの適切な前処理、クラスのバランスの確保、適切な学習率とエポック数での微調整が含まれます。ランダムな単語マスキングやシャッフルなどのデータ拡張手法を適用して、トレーニングデータの多様性を高め、モデルの汎化能力を向上させることもできます。
速度とメモリ使用量の最適化
DistilBERT の速度とメモリ使用量を最適化するには、いくつかの手法を適用できます。
まず、GPU などのハードウェアアクセラレーションを利用することで、DistilBERT の推論速度を大幅に向上させることができます。
さらに、並列処理のためにコードを最適化し、非常に大きなバッチでのトレーニングなどのバッチ処理を活用することで、DistilBERT の計算速度をさらに向上させることができます。メモリ使用量を削減するには、量子化(ネットワークの重みをより小さな精度で近似する)や重みプルーニング(ネットワーク内の一部の接続を削除する)などの手法を使用できます。
DistilBERT のようなコンパクトモデルの未来
DistilBERT のようなコンパクトモデルは、大規模モデルと比較してより効率的でコスト効果の高いソリューションを提供するため、NLP の未来を象徴しています。デバイス上での言語処理機能への需要は高まっており、コンパクトモデルはリソース制約のあるデバイスで実行可能なソリューションを提供します。
モデル圧縮技術の研究が進むにつれて、近年ではさらに小型で高速なモデルが改善された性能で期待できます。さらに、DistilBERT のような事前学習済みコンパクトモデルの利用可能性により、開発者は大規模な計算リソースを必要とせずに NLP アプリケーションを迅速にデプロイできます。NLP の未来は、リアルタイム言語処理の需要に応えるために、DistilBERT のようなコンパクトモデルの広範な採用と開発が見られるでしょう。
進行中の研究と限界
学界と産業界の両方の研究グループは、DistilBERT の広大な可能性を探求し続けながら、その限界を認識しています。大学や AI 研究ラボは、モデルの複雑さを掘り下げ、その能力を強化し、適用範囲を拡大しています。
- 研究イニシアチブ: 主要大学や AI 研究グループが協力して、DistilBERT の可能性の限界を押し広げています。
- 限界への取り組み: 進行中の研究は、長いテキストにわたるコンテキスト保持と微妙な言語理解の改善に焦点を当てています。
- モデルの洗練: 精度が重要となる医療診断や法文書分析などの特定タスク向けに DistilBERT を洗練する努力が行われています。
しかし、これらの限界を克服するには時間がかかります。最近リリースされた Llama 3 のようなより優れたモデルを選択して、時間を節約しながら作業を完了することもできます。ここに novita.ai の LLM API のモデル一覧があります:

今すぐ無料で LLM API をお試しください:

結論
結論として、DistilBERT はコンパクトな設計と向上した効率性により、AI モデルの世界に革命をもたらしました。先行モデル BERT から知識を蒸留することで、精度を損なうことなく、より高速で軽量な代替手段を提供します。
テキスト分類や感情分析などの実世界のシナリオへの DistilBERT の適用は、その計り知れない可能性を示しています。技術仕様とパフォーマンス指標を理解することは、その能力を最適に活用するために重要です。DistilBERT のようなコンパクトモデルの未来を探求するにつれて、モデル圧縮技術の継続的な進歩は、AI 開発とイノベーションにエキサイティングな展望を約束します。AI モデルの次世代にご期待ください。そして、待ち受ける可能性を探求してください。
novita.ai は、100 以上の API にアクセスできる、無限の創造性のためのワンストッププラットフォームです。画像生成、言語処理、音声強調、ビデオ操作に至るまで、低コストの従量課金制で、GPU メンテナンスの手間から解放されながら、独自の製品を構築できます。今すぐ無料でお試しください。
おすすめの記事



