

Points clés
Avantage économique notable : Faible demande en VRAM, besoins matériels modestes, permettant un fonctionnement sur du matériel courant.
Performances exceptionnelles : Excelle dans de multiples tâches incluant les connaissances générales, le traitement de code, le raisonnement mathématique, le raisonnement logique et le traitement multilingue, avec une grande polyvalence et adaptabilité.
Tarification attractive sur Novita AI : Avec un prix très compétitif sur Novita AI à 0,02 $ par million de tokens en entrée et 0,05 $ par million de tokens en sortie.
Pour les développeurs, les passionnés et les petites et moyennes entreprises, la quête d’un modèle d’IA se heurte souvent à un problème récurrent : trouver le bon équilibre entre performance et coût. Beaucoup cherchent une solution qui ne nécessite pas un investissement massif dans du matériel haut de gamme ni ne ruine le budget en tokens, tout en offrant des résultats fiables sur diverses tâches. Llama 3.1 8B émerge comme la réponse idéale à ces préoccupations.
Parrainez vos amis sur Novita AI et vous recevrez tous les deux 10 $ de crédits API LLM – jusqu’à 500 $ de récompenses totales.
Pour soutenir la communauté des développeurs, Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B sont actuellement disponibles gratuitement sur Novita AI.

Qu’est-ce que Llama 3.1 8B ?
LLaMA 3.1 8B est un grand modèle de langage open source construit sur une architecture de transformateur dense. Il prend en charge plusieurs langues et offre des performances solides en génération de texte et de code, ce qui le rend adapté aux applications généralistes.

- Taille du modèle : 8B
- Open Source : Oui
- Architecture : Transformateur dense
- Longueur de contexte : 128 000 tokens
Langues prises en charge
Prend en charge l’anglais, l’allemand, le français, l’italien, le portugais, l’hindi, l’espagnol et le thaï.
Capacité multimodale
Accepte le texte en entrée et génère du texte ou du code en sortie. Il ne prend pas en charge les entrées images ou audio.
Données d’entraînement
Pré-entraîné sur environ 15 000 milliards de tokens provenant de sources publiques. Affiné avec plus de 25 millions d’exemples d’instructions générées synthétiquement, ainsi que des ensembles de données d’instructions publiques.
Benchmarks de Llama 3.1 8B (comparé à d’autres modèles)
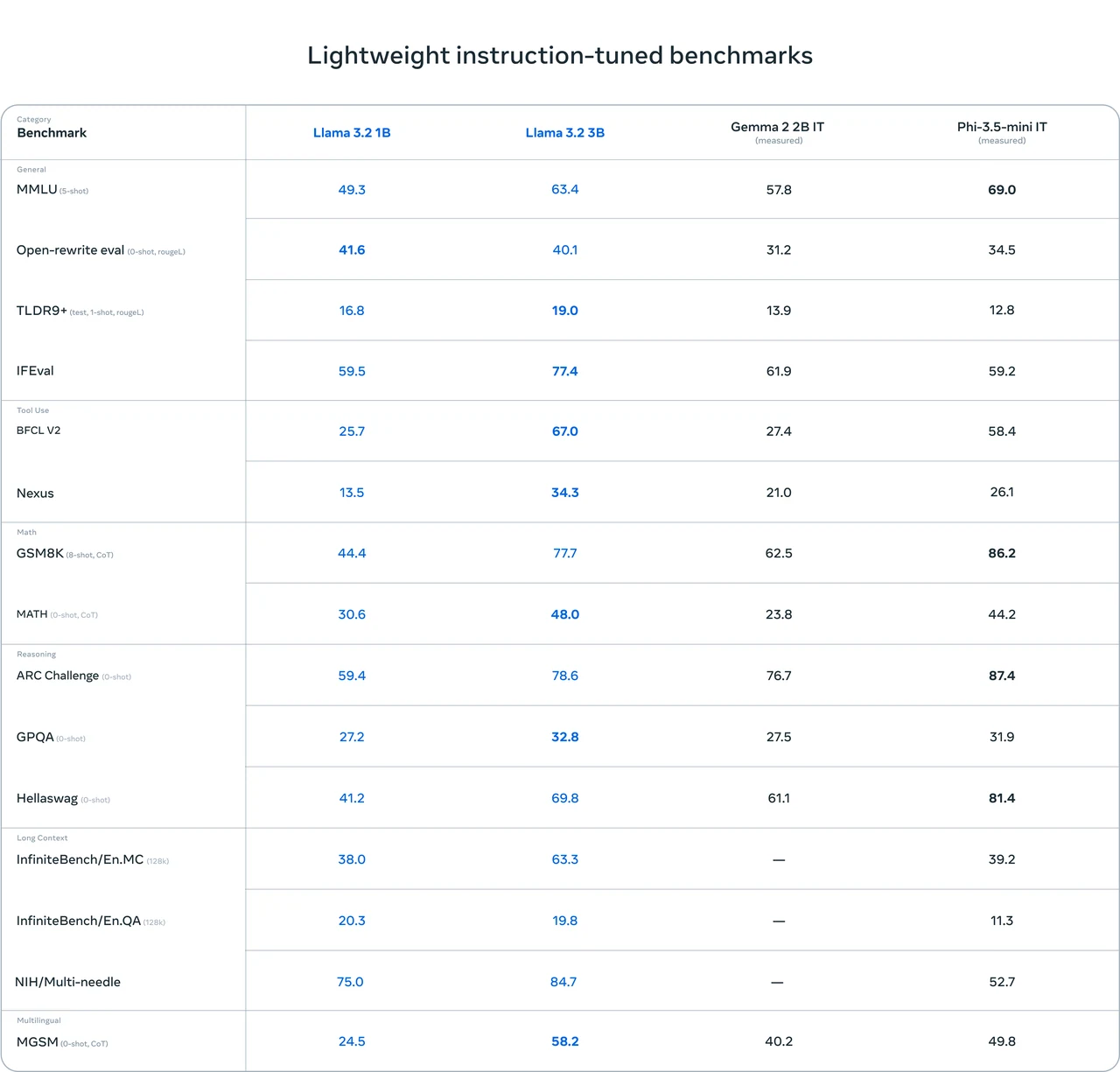
- Bonnes performances globales : Llama 3.1 8B a obtenu des résultats relativement bons dans plusieurs tests de référence. Par exemple, il atteint des scores élevés dans des tests comme IFEval (80,4) et GSM8K (8-shot, CoT) (84,5), ce qui indique qu’il possède certaines forces en capacités générales et en raisonnement mathématique.
- Capacité de codage remarquable : Il performe bien dans les tests liés au code tels que HumanEval (0-shot) (72,6) et MBPP EvalPlus (base) (0-shot) (72,8), suggérant de solides compétences dans les tâches de traitement de code.
- Marge d’amélioration : Ses scores ne sont pas les plus élevés dans certains tests, comme MATH (0-shot, CoT) (51,9) et GPQA (0-shot, CoT) (32,8). Cela implique qu’il reste une marge de progression dans des scénarios spécifiques de raisonnement mathématique et de questions-réponses.
Configuration matérielle requise pour Llama 3.1 8B
| Modèle | VRAM nécessaire (FP16) | GPU typiques |
|---|---|---|
| LLaMA 3.1 8B | 17,17 Go | RTX 3090 (12 Go, insuffisant) 2× RTX 4060 (8 Go chacune) |
| Qwen3-8B | 17,89 Go | RTX 3090 2× RTX 4060 |
| LLaMA 3 8B | 17,17 Go | RTX 3090 2× RTX 4060 |
| Gemma 3 4B | 10,29 Go | RTX 3090 2× RTX 4060 |
| LLaMA 3.2 1B | 3,14 Go | RTX 4060 |
Bien que LLaMA 3.1 8B offre un bon équilibre optimisé entre capacité et utilisation mémoire au sein de la classe des 8B paramètres, son besoin matériel reste élevé pour la plupart des passionnés ou développeurs avec un seul GPU. Pour un déploiement léger, des modèles plus petits comme Gemma 3 4B ou LLaMA 3.2 1B offrent des besoins en VRAM nettement inférieurs, les rendant plus accessibles sur du matériel grand public.
Comment accéder à Llama 3.1 8B ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Essayez Llama 3.1 8B maintenant !
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page « Settings » et copiez la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets propre à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "meta-llama/llama-3.1-8b-instruct-bf16"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant serviable"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
LLaMA 3.1 8B établit un bon équilibre entre performance et évolutivité, notamment dans les tâches multilingues et de codage. Cependant, les développeurs disposant d’un matériel limité peuvent trouver ses besoins exigeants. Pour des cas d’usage légers, Llama 3.2 1B ou Gemma 3 4B offrent des alternatives économiques. Grâce à l’accès via l’API de Novita AI, les développeurs peuvent explorer ces modèles facilement sans investir dans des GPU haut de gamme.
Questions fréquentes
Qu’est-ce que Llama 3.1 8B ?
Un modèle open source de 8 milliards de paramètres optimisé pour la génération de texte et de code à usage général.
Puis-je exécuter Llama 3.1 8B sur un seul GPU ?
L’inférence nécessite 17,17 Go de VRAM ; le fine-tuning nécessite plus de 80 Go.
Où puis-je utiliser Llama 3.1 8B ?
Vous pouvez y accéder via la plateforme Novita AI en utilisant leur simple API Python pour les complétions de chat et plus encore.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



