

重點摘要
顯著成本優勢:所需 VRAM 低,硬體需求適中,可在常見硬體上運作。
傑出效能:在通用知識、程式處理、數學推理、邏輯推理及多語言處理等多項任務中表現優異,具備強大的通用性與任務適應能力。
Novita AI 上的優惠價格:在 Novita AI 上極具競爭力,每 1M 輸入 Token 僅需 $0.02,每 1M 輸出 Token 僅需 $0.05。
對於開發者、業餘愛好者以及中小型企業而言,追求 AI 模型時常面臨一個共同的痛點:如何在效能與成本之間取得平衡。許多人正在尋找一個不需要大筆投資高階硬體、也不需花費高昂 Token 費用的解決方案,同時仍能在各項任務中提供可靠的結果。Llama 3.1 8B 正是回應這些疑慮的理想解答。
推薦朋友使用 Novita AI,您和對方都可獲得 $10 的 LLM API 額度,最高可累積 $500 總獎勵。
為了支援開發者社群,Llama 3.2 1B、Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B 目前在 Novita AI 上免費提供。

什麼是 Llama 3.1 8B?
LLaMA 3.1 8B 是一個採用密集 Transformer 架構的開源大型語言模型。它支援多種語言,並在文字與程式碼生成方面展現強大效能,適合通用型應用。

- 模型大小: 1B
- 開源: 是
- 架構: 密集 Transformer
- 上下文長度: 128,000 個 Token
語言支援
支援英文、德文、法文、義大利文、葡萄牙文、印度文、西班牙文及泰文。
多模態能力
接受文字作為輸入,生成文字或程式碼作為輸出。不支援圖片或音訊輸入。
訓練資料
從公開來源預訓練約 15 兆 Token。使用超過 2500 萬個合成生成的指令範例以及公開的指令資料集進行微調。
Llama 3.1 8B 基準測試(與其他模型比較)
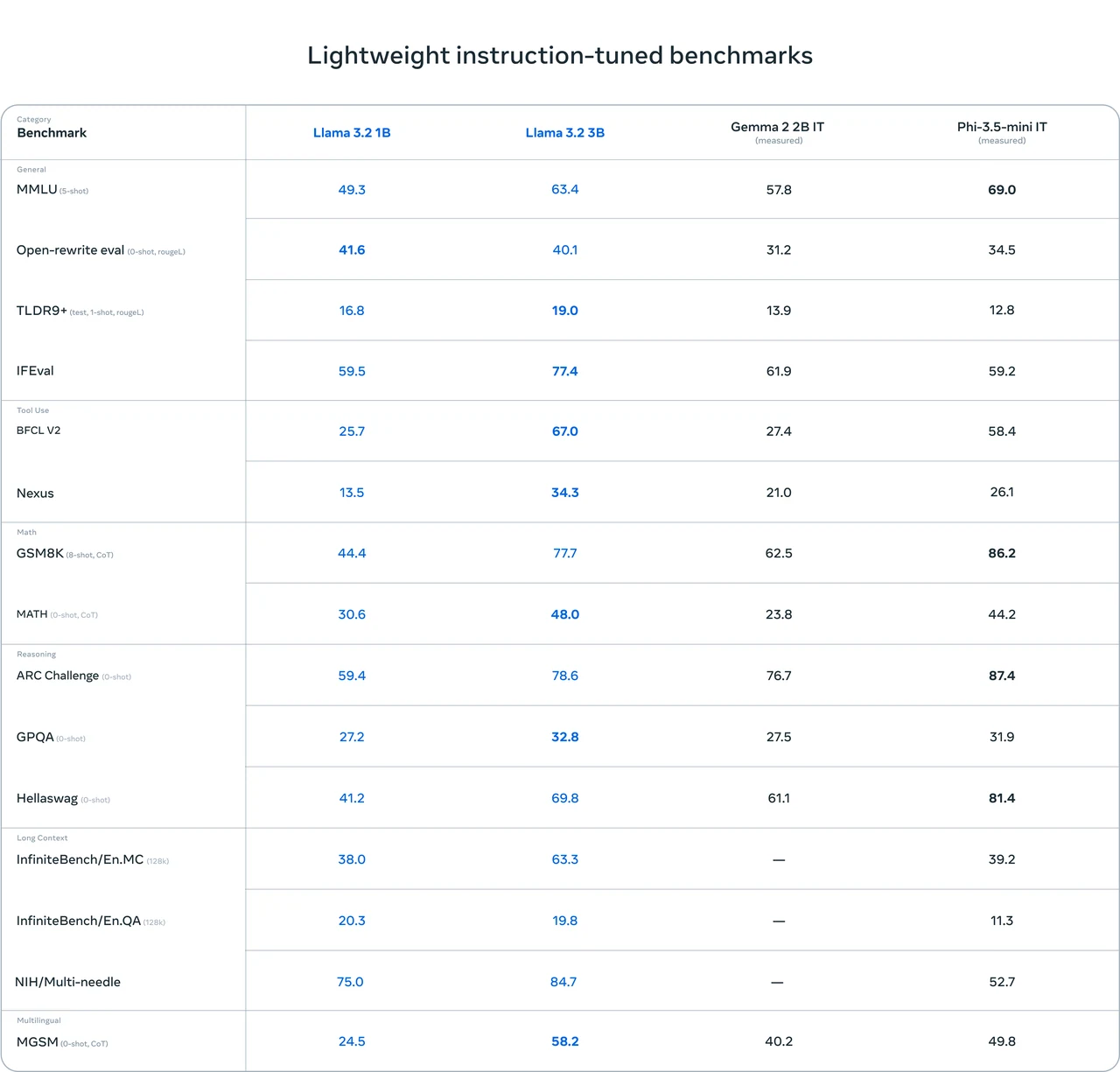
- 全面的優異表現:Llama 3.1 8B 在多項基準測試中取得了相對良好的成績。例如,在 IFEval(80.4)與 GSM8K(8-shot, CoT)(84.5)等測試中分數較高,顯示其在通用能力、數學推理等方面具備一定優勢。
- 傑出的程式能力:在程式相關測試如 HumanEval(0-shot)(72.6)與 MBPP EvalPlus(base)(0-shot)(72.8)中表現良好,顯示其在程式處理任務上具有強大的能力。
- 仍有進步空間:在某些測試中分數並非最高,例如 MATH(0-shot, CoT)(51.9)與 GPQA(0-shot, CoT)(32.8)。這表示在特定數學推理與問答場景中仍有性能提升的空間。
Llama 3.1 8B 硬體需求
| 模型 | 所需 VRAM (FP16) | 建議 GPU |
|---|---|---|
| LLaMA 3.1 8B | 17.17 GB | RTX 3090 (12 GB,不足) 2× RTX 4060 (各 8 GB) |
| Qwen3-8B | 17.89 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3 8B | 17.17 GB | RTX 3090 2× RTX 4060 |
| Gemma 3 4B | 10.29 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3.2 1B | 3.14 GB | RTX 4060 |
儘管 LLaMA 3.1 8B 在 8B 參數類別中提供了良好的效能與記憶體使用平衡,**但對於大多數使用單一 GPU 的業餘愛好者或開發者而言,其硬體需求仍然偏高 **。對於輕量部署,較小的模型如 Gemma 3 4B 或 LLaMA 3.2 1B 所需的 VRAM 顯著較低,因此在消費級硬體上更容易取得。
如何存取 Llama 3.2 1B?
步驟 1:登入並進入模型庫
登入您的帳戶,然後點選 模型庫 按鈕。

步驟 2:選擇您的模型
瀏覽可用的選項,然後選擇符合您需求的模型。

步驟 3:開始免費試用
開始免費試用,探索所選模型的功能。
步驟 4:取得您的 API 金鑰
為了進行 API 驗證,我們將提供一個新的 API 金鑰。進入「設定」頁面,即可依照圖片指示複製 API 金鑰。

步驟 5:安裝 API
使用與您程式語言對應的套件管理器來安裝 API。
安裝完成後,將必要的函式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,開始與 Novita AI LLM 進行互動。以下是 Python 使用者使用聊天補全 API 的範例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.1-8b-instruct-bf16"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
LLaMA 3.1 8B 在效能與可擴展性之間取得了平衡,尤其是在多語言與程式任務方面。然而,硬體資源有限的開發者可能會覺得其需求較高。對於輕量使用案例,Llama 3.2 1B 或 Gemma 3 4B 提供了更具成本效益的替代方案。透過 Novita AI 的 API 存取,開發者可以輕鬆探索這些模型,無需投資高階 GPU。
常見問題
什麼是 Llama 3.1 8B?
一個開源的 8B 參數模型,針對通用文字與程式碼生成進行最佳化。
我能在單一 GPU 上執行 Llama 3.1 8B 嗎?
推理需要 3.14 GB VRAM;微調需要 14.11 GB VRAM。
我在哪裡可以使用 Llama 3.1 8B?
您可以透過 Novita AI 平台使用其簡單的 Python API 進行聊天補全等操作。
Novita AI 是一個 AI 雲端平台,為開發者提供使用簡單 API 部署 AI 模型的簡便方式,同時也提供經濟實惠且可靠的 GPU 雲端服務,用於建置與擴展。**



