

Ключевые моменты
Заметное преимущество по стоимости: Требует мало видеопамяти, скромные требования к оборудованию, что позволяет работать на обычном оборудовании.
Выдающаяся производительность: Отлично справляется с множеством задач, включая общие знания, обработку кода, математические рассуждения, логические рассуждения и многоязычную обработку, отличаясь универсальностью и адаптируемостью.
Привлекательная цена на Novita AI: Благодаря высокой конкурентоспособности цены на Novita AI — $0.02 за 1 млн входных токенов и $0.05 за 1 млн выходных токенов.
Для разработчиков, энтузиастов и малых и средних компаний поиск идеальной AI-модели часто сопряжён с общей проблемой: необходимостью балансировать между производительностью и стоимостью. Многие ищут решение, которое не требует огромных вложений в дорогостоящее оборудование и не разоряет на стоимости токенов, но при этом стабильно выдаёт надёжные результаты в различных задачах. Llama 3.1 8B становится идеальным ответом на эти запросы.
Приглашайте друзей в Novita AI — вы оба получите по $10 на LLM API, а максимальная сумма вознаграждения — до $500.
В поддержку сообщества разработчиков Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B сейчас доступны бесплатно на Novita AI.

Что такое Llama 3.1 8B?
LLaMA 3.1 8B — это открытая большая языковая модель, построенная на плотной трансформерной архитектуре. Она поддерживает несколько языков и демонстрирует высокую производительность как в генерации текста, так и кода, что делает её подходящей для универсальных приложений.

- Размер модели: 1B
- Открытый исходный код: Да
- Архитектура: Плотный трансформер
- Длина контекста: 128 000 токенов
Поддерживаемые языки
Поддерживает английский, немецкий, французский, итальянский, португальский, хинди, испанский и тайский.
Мультимодальные возможности
Принимает на вход текст и генерирует текст или код. Не поддерживает изображения или аудио.
Данные обучения
Предварительно обучен на примерно 15 триллионах токенов из общедоступных источников. Тонкая настройка выполнена на более чем 25 миллионах синтетически сгенерированных примеров инструкций, а также на общедоступных наборах данных инструкций.
Llama 3.1 8B: Бенчмарки (в сравнении с другими моделями)
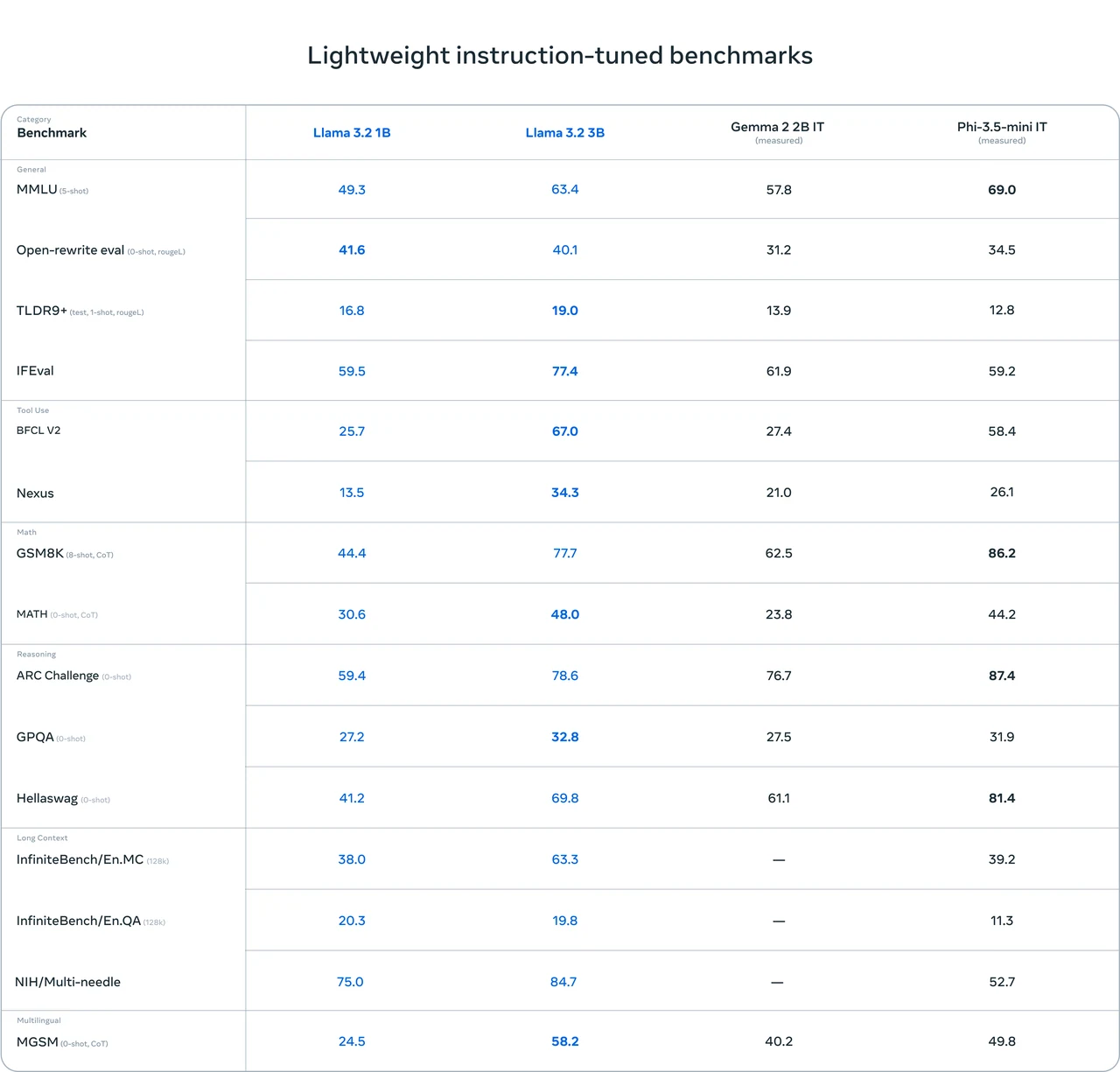
- Хорошая комплексная производительность: Llama 3.1 8B показала относительно хорошие результаты в нескольких бенчмарках. Например, высокие баллы в тестах IFEval (80.4) и GSM8K (8-shot, CoT) (84.5) указывают на определённые преимущества в универсальных способностях и математических рассуждениях.
- Отличная способность к работе с кодом: Хорошо проявляет себя в тестах, связанных с кодом, таких как HumanEval (0-shot) (72.6) и MBPP EvalPlus (base) (0-shot) (72.8), что говорит о высокой компетентности в задачах обработки кода.
- Потенциал для улучшения: В некоторых тестах её баллы не самые высокие, например, MATH (0-shot, CoT) (51.9) и GPQA (0-shot, CoT) (32.8). Это означает, что в определённых сценариях математических рассуждений и ответов на вопросы ещё есть место для улучшения.
Требования к оборудованию для Llama 3.1 8B
| Модель | Требуемая видеопамять (FP16) | Типичные видеокарты |
|---|---|---|
| LLaMA 3.1 8B | 17.17 ГБ | RTX 3090 (12 ГБ — недостаточно) 2× RTX 4060 (по 8 ГБ каждая) |
| Qwen3-8B | 17.89 ГБ | RTX 3090 2× RTX 4060 |
| LLaMA 3 8B | 17.17 ГБ | RTX 3090 2× RTX 4060 |
| Gemma 3 4B | 10.29 ГБ | RTX 3090 2× RTX 4060 |
| LLaMA 3.2 1B | 3.14 ГБ | RTX 4060 |
Хотя LLaMA 3.1 8B предлагает хорошо оптимизированный баланс возможностей и использования памяти в классе 8B параметров, требования к оборудованию остаются высокими для большинства энтузиастов или разработчиков с одной видеокартой. Для лёгкого развёртывания меньшие модели, такие как Gemma 3 4B или LLaMA 3.2 1B, требуют значительно меньше видеопамяти, что делает их более доступными на оборудовании потребительского уровня.
Как получить доступ к Llama 3.2 1B?
Шаг 1: Войдите в систему и откройте библиотеку моделей
Войдите в свою учётную запись и нажмите кнопку Model Library (Библиотека моделей).

Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите подходящую модель.

Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Попробовать Llama 3.1 8B сейчас!
Шаг 4: Получите API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Перейдите на страницу «Settings» и скопируйте API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, подходящего для вашего языка программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API, указав ваш API-ключ, чтобы начать взаимодействие с Novita AI LLM. Ниже приведён пример использования API для завершения чата на Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.1-8b-instruct-bf16"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
LLaMA 3.1 8B представляет собой баланс между производительностью и масштабируемостью, особенно в многоязычных задачах и задачах программирования. Однако разработчики с ограниченными аппаратными ресурсами могут посчитать её требования высокими. Для лёгких сценариев использования Llama 3.2 1B или Gemma 3 4B предлагают экономически эффективные альтернативы. Благодаря доступу через API Novita AI разработчики могут легко изучать эти модели, не вкладываясь в дорогие видеокарты.
Часто задаваемые вопросы
Что такое Llama 3.1 8B?
Это открытая модель с 8 млрд параметров, оптимизированная для универсальной генерации текста и кода.
Могу ли я запустить Llama 3.1 8B на одной видеокарте?
Для инференса требуется 3.14 ГБ видеопамяти; для тонкой настройки — 14.11 ГБ видеопамяти.
Где я могу использовать Llama 3.1 8B?
Вы можете получить к ней доступ через платформу Novita AI, используя их простой Python API для завершения чата и других задач.
Novita AI — это облачная AI-платформа, предоставляющая разработчикам простой способ развёртывания AI-моделей с помощью нашего простого API, а также доступное и надёжное облако GPU для создания и масштабирования.



