

Key Highlights
Qwen 2.5 7B is a high-performance open-source language model.
Full precision (FP16) inference requires ~17.18 GB VRAM; fine-tuning can exceed 92 GB.
Running locally demands high-end GPUs, making deployment costly for most.
Novita AI, nCompass, and Nineteen AI all support Qwen 2.5 7B access.
your friends to Novita AI and both of you will earn $10 in LLM API credits—up to $500 in total rewards.
To support the developer community, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B is currently available for free on Novita AI.

Qwen 2.5 7B is a powerful 7B-parameter model built for high-quality language generation. While its performance is impressive, its hardware demands pose a barrier to many teams. Through reliable third-party API providers like Novita AI, nCompass, and Nineteen AI, developers can deploy and scale Qwen 2.5 7B in seconds—no high-end GPU setup required.
What is Qwen 2.5 7B?

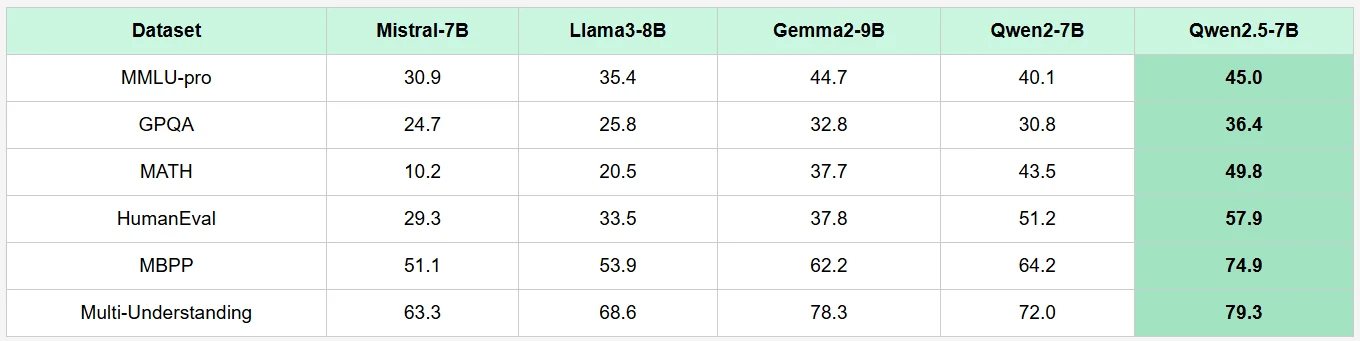
Qwen 2.5 7B Benchmark
Qwen 2.5 7B Hardware Requirements
| Percision | Approximately VRAM Inference Required |
| FP32 | 32.26GB |
| FP16 | 17.18GB |
| Percision | Approximately VRAM Fine-tuning Required |
| FP16 | 92.57GB |
Why Use an API for Qwen 2.5 7B?
Qwen 2.5 7B delivers strong performance, but its hardware requirements can be prohibitive. In FP16 precision, inference typically demands 17.18 GB of VRAM, while fine-tuning may require up to 92.57 GB. Deploying the model locally often necessitates high-end GPUs such as A100s or RTX 4090s—resources beyond the reach of most developers and teams. API access provides a practical alternative, offering immediate availability of compute resources without upfront infrastructure costs or operational complexity.
Advantages of API Access
| ⚙️ Automation Automate tasks, reduce manual work, boost efficiency. | 🧩 Integration Connect systems, create seamless experiences. | 📈 Scalability Scale easily without overhauls. | 💡 Innovation Build faster, cheaper, smarter solutions. |
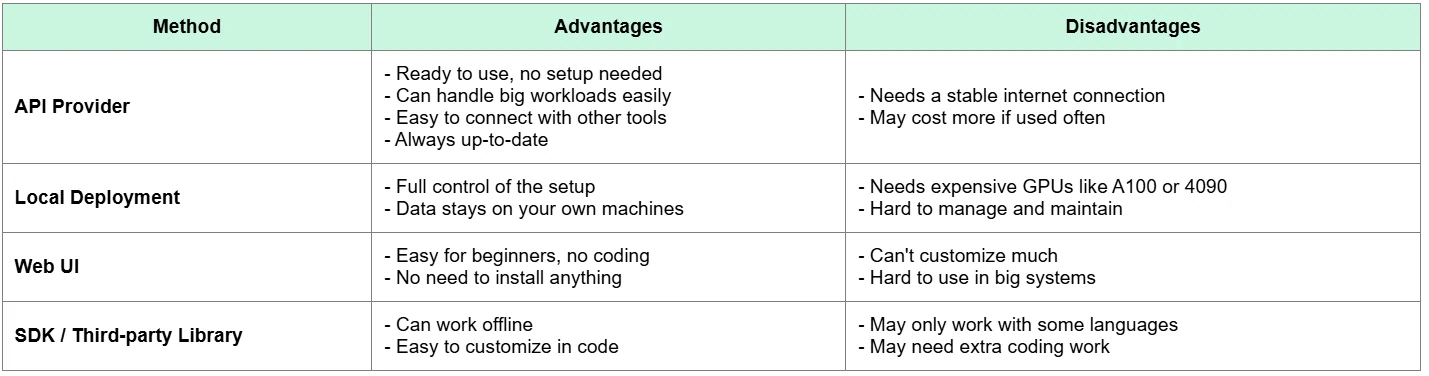
Comparison: API vs Other Deployment Methods
How to Choose an API Provider (5 metrics)
Max Output: The more tokens allowed per response, the better.
Higher = Better
Input Cost: Cost per million input tokens.
Lower = Better
Output Cost: Cost per million output tokens.
Lower = Better
Latency: Time between sending a request and receiving the first byte.
Lower = Better
Throughput: Number of requests the API can handle per second.
Higher = Better
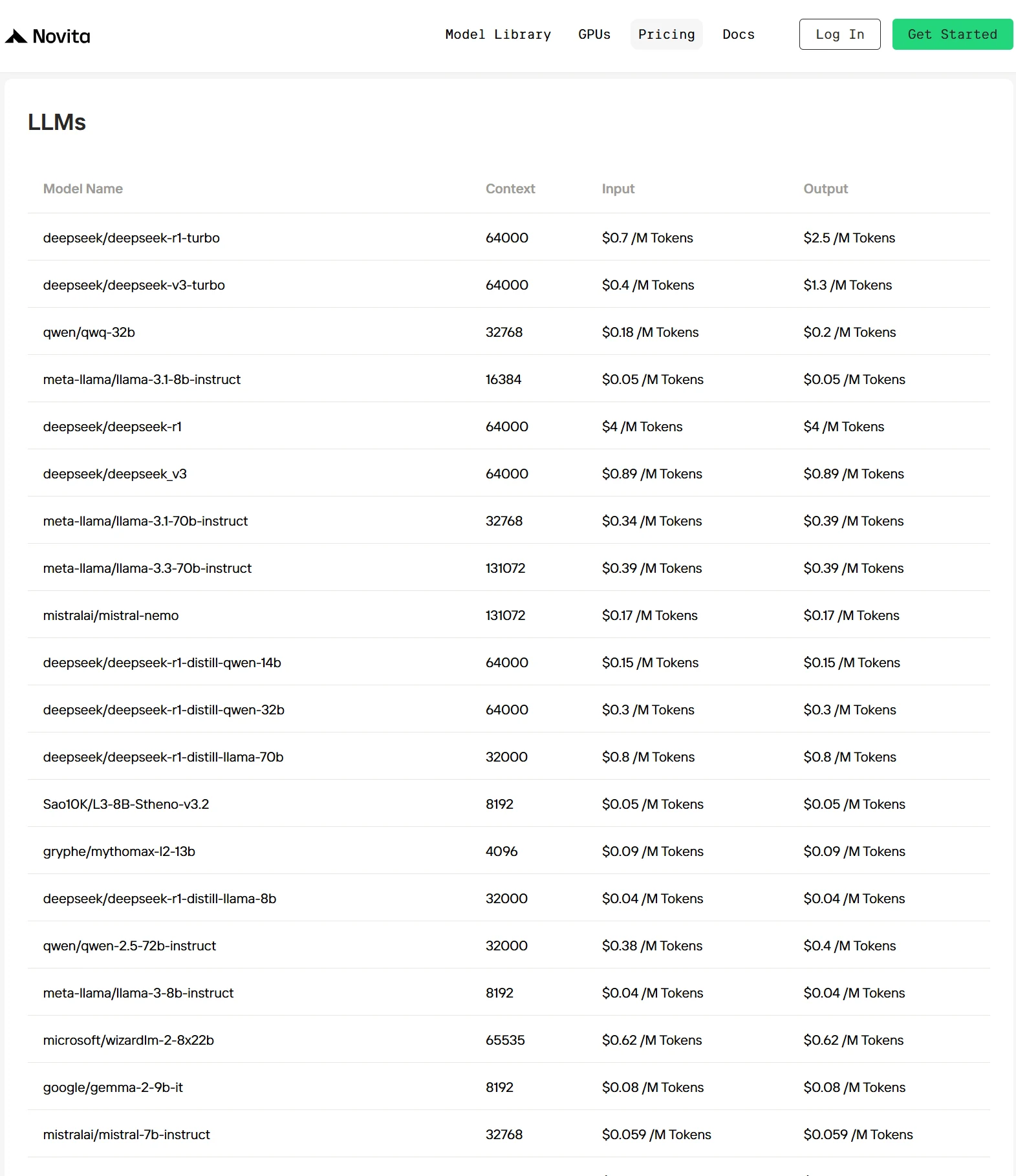
Top 3 API Providers of Qwen 2.5 7B
1. Novita AI
Novita AI is a developer-friendly cloud platform that enables fast deployment of AI models via a simple API, backed by affordable and reliable GPU infrastructure. With pre-integrated multimodal models like DeepSeek V3, DeepSeek R1, and LLaMA 3.3 70B, developers can get started immediately—no setup required. Novita’s proprietary optimization technology further reduces inference costs by 30%–50% compared to major providers, making it both efficient and cost-effective for scaling AI applications.

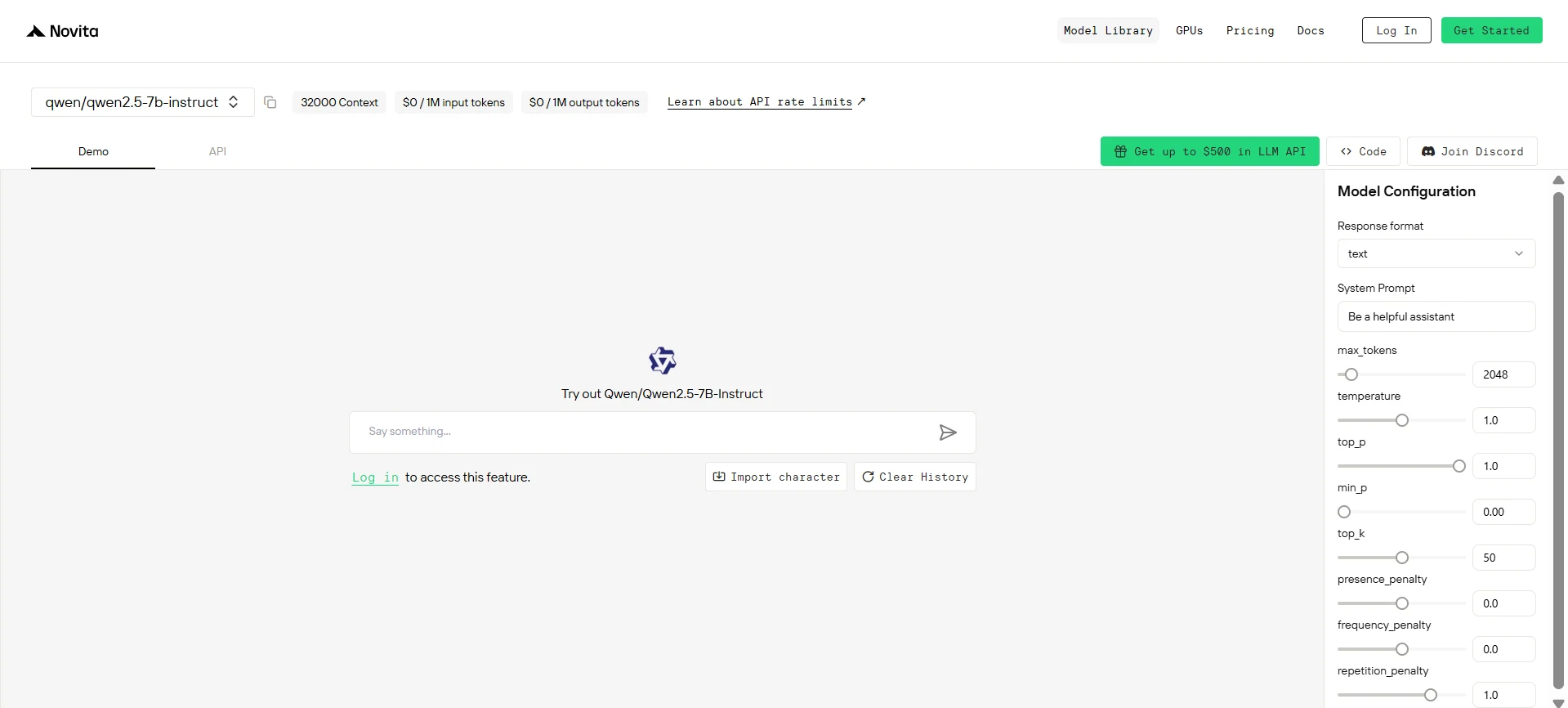
How to Access Qwen 2.5 7B via Novita API?
You can begin your free trial to explore the capabilities of the selected model. After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)2.nCompass
nCompass Technologies is an emerging leader in AI infrastructure optimization, offering advanced solutions that address the growing performance and cost challenges of large-scale AI inference. By developing custom GPU kernels and serving software, nCompass enables businesses to maintain high-quality service on fewer GPUs—dramatically reducing hardware costs without sacrificing speed or scalability.
How to Access Qwen 2.5 7B through it?
from openai import OpenAI
client = OpenAI(
base_url="https://api.ncompass.tech/v1",
api_key="YOUR_API_KEY",
)
completion = client.chat.completions.create(
model="meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)3.Nineteen AI
Nineteen AI specializes in inference, providing streamlined access to top open-source LLMs, image generation models—including those trained on Subnet 19 datasets—and a range of specialized models like embeddings. We’ve also developed and open-sourced our own workflows, such as avatar generation, to support fast and flexible AI development.
How to Access Qwen 2.5 7B through it?
import json
import contextlib
import requests
url = "https://api.nineteen.ai/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_NINETEEN_API_KEY",
"Content-Type": "application/json"
}
data = {
"messages": [],
"model": "chat-qwen-2-5-7b",
"temperature": 0.5,
"max_tokens": 500,
"top_p": 0.5,
"stream": True
}
response = requests.post(url, headers=headers, json=data)
if response.status_code != 200:
raise Exception(response.text)
for x in response.content.decode().split("\
"):
if not x:
continue
with contextlib.suppress(Exception):
print(json.loads(x.split("data: ")[1].strip())["choices"][0]["delta"]["content"], end="", flush=True)For developers looking to integrate Qwen 2.5 7B into their stack efficiently, API-based access is the most practical choice. It removes infrastructure overhead, reduces costs, and simplifies scaling. Whether you’re building chatbots, embeddings, or creative apps, third-party APIs let you get started fast—with performance that matches local deployment.
Frequently Asked Questions
How much VRAM does Qwen 2.5 7B need?
~17.18 GB for inference (FP16); fine-tuning requires up to 92.57 GB.
Why use an API instead of running locally?
APIs eliminate the need for expensive GPUs, provide instant access, and are easier to scale.
Which providers support Qwen 2.5 7B?
Novita AI, nCompass Technologies, and Nineteen AI and more……
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



