

- Llama 4 Maverick vs Gemma 3 27B: Tasks
- Llama 4 Maverick vs Gemma 3 27B:Basic Introduction
- Llama 4 Maverick vs Gemma 3 27B:Benchmark
- Llama 4 Maverick vs Gemma 3 27B: Speed Comparsion
- Llama 4 Maverick vs Gemma 3 27B: Hardware Requirements
- Llama 4 Maverick vs Gemma 3 27B: Applications
- How to Access Llama 4 Maverick and Gemma 3 27B via Novita API?
Key Highlights
Model Differences
Llama 4 Maverick is a high-performance, multimodal AI model designed for complex tasks like long-context reasoning and multilingual support, making it ideal for enterprises, research, and government applications.
Gemma 3 27B is a lightweight AI model better suited for small to medium businesses, education, and prototyping, with efficient cloud deployment and lower hardware requirements.
Performance Comparison: Llama 4 Maverick outperforms Gemma 3 27B in benchmarks and response speed, making it suitable for demanding real-time applications.
Hardware Requirements: Llama 4 Maverick requires high-end GPUs, while Gemma 3 27B is more cost-effective with lower hardware demands.
The AI landscape is dominated by cutting-edge language models like Llama 4 Maverick and Gemma 3 27B, each tailored for distinct use cases. Llama 4 Maverick’s unmatched power, multimodal capability, and support for 200 languages make it a top choice for enterprise-level and research-intensive tasks. On the other hand, Gemma 3 27B offers a lightweight alternative, excelling in cost-effective deployment and accessibility for small to medium businesses, education, and prototyping. This guide compares their features, benchmarks, and use cases to help you decide which model suits your needs best.
Llama 4 Maverick vs Gemma 3 27B: Tasks
Prompt: *“*Tell me what the subject of this picture is, and tell me its English so that I can learn this word“
Llama 4 Maverick
The subject of this picture is a water lily. The English word for it is “water lily” or “lotus” (although technically, the lotus is a different type of flower, Nelumbo, while water lilies belong to the Nymphaea genus).
In this case, the correct term is likely “water lily.”
Gemma 3 27B
The subject of the picture is a water lily.
That’s the English word for it!
Here are some things to know about water lilies:
- They are aquatic flowering plants that grow in ponds and lakes.
- They have floating leaves and beautiful, fragrant flowers.
- They come in a variety of colors, including white, pink, yellow, and red.
Llama 4 Maverick vs Gemma 3 27B:Basic Introduction
Llama 4 Maverick
| Category | Item | Details |
|---|---|---|
| Basic Info | Release Date | April 5, 2025 |
| Model Size | 400B parameters (17B active/token) | |
| Open Source | Open | |
| Architecture | 128 Mixture-of-Experts (MoE) | |
| Language Support | Language Support | Pre-trained on 200 languages. Supports Arabic, English, French, German, Hindi, Indonesian, Italian, Portuguese, Spanish, Tagalog, Thai, and Vietnamese. |
| Multimodal | Multimodal Capability | Input: Multilingual text and image; output multilingual text and code |
| Training | Training Data | ~22 trillion tokens of multimodal data (some from Instagram and Facebook) |
| Pre-Training | MetaP: Adaptive Expert Configuration + mid-training | |
| Post-Training | SFT (Easy Data) → RL (Hard Data) → DPO |
Gemma 3 27B
| Category | Item | Details |
|---|---|---|
| Basic Info | Release Date | March 12, 2025 |
| Model Size | 27 billion parameters | |
| Open Source | Yes (released by Google) | |
| Architecture | Interleaved Local-Global Attention | |
| Context Window | 128K tokens | |
| Language Support | Supported Multilingual Languages | Over 140 languages |
| Multimodal | Multimodal Capability | Yes (processes images and text, outputs text) |
| Training | Training Data | 14 trillion tokens |
| Training Method | Knowledge Distillation + Reinforcement Learning from Human Feedback (RLHF) |
Llama 4 Maverick vs Gemma 3 27B:Benchmark
| Benchmark | Llama 4 Maverick | Gemma 3 27B |
|---|---|---|
| MMLU-Pro | 80.5 | 67.5 |
| GPQA Diamond | 69.8 | 42.4 |
| LiveCodeBench | 43.4 | 29.7 |
| MATH | 73.7 | 69.0 |
| MMMU | 73.4 | 64.9 |
Llama 4 Maverick is the stronger general-purpose model, excelling in high-complexity, multilingual, and multimodal tasks. Gemma 3 27B shows notable performance in lighter or specific domains like mathematical reasoning and multimodal understanding, but overall, it falls behind Llama 4 Maverick in versatility and power.
Llama 4 Maverick vs Gemma 3 27B: Speed Comparsion
If you want to test it yourself, you can start a free trial on the Novita AI website.

Try Llama 4 Maverick and Gemma 3 27B Demo Now!
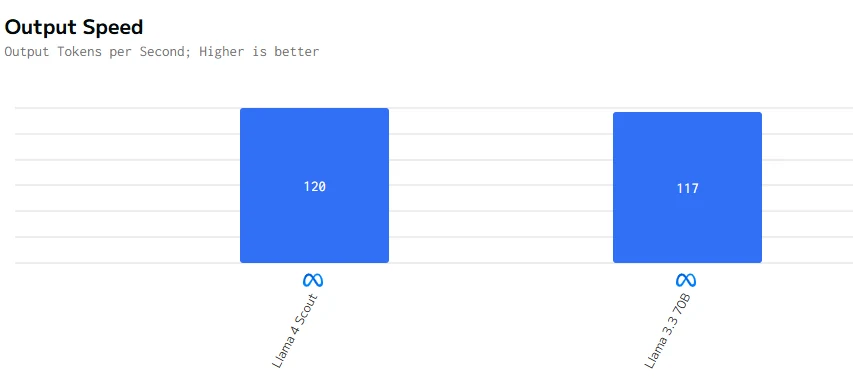
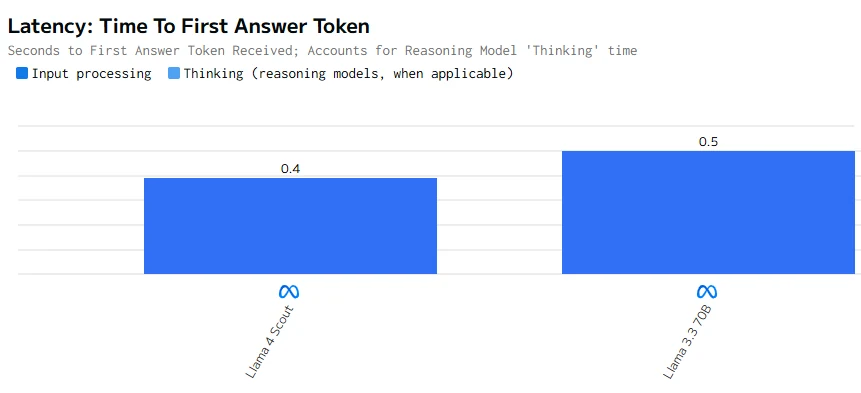
Llama 4 Maverick significantly outperforms Gemma 3 27B in both output speed and response latency, making it better suited for efficient, real-time tasks. In contrast, Gemma 3 27B falls short in terms of performance.
Llama 4 Maverick vs Gemma 3 27B: Hardware Requirements
| Metric | Llama 4 Maverick | Gemma 3 27B |
|---|---|---|
| INT4 VRAM | ||
| 4K Tokens | ~318 GB - 4 * H100 / A100 | — |
| 128K Tokens | ~552 GB - 8 * H100 | — |
| FP16 VRAM | ||
| 4K Tokens | ~1.22 TB - 16 * H100 | 75GB-H100 |
| 128K Tokens | ~1.45 TB - About 6 * H100 | 91.7GB-2*H100 |
Llama 4 Maverick:
Higher hardware requirements mean it can handle more complex tasks, such as ultra-long context reasoning.
It is suitable for high-performance computing environments (e.g., enterprise-level deployments, research institutions, and large-scale language model services).
Gemma 3 27B:
Low hardware requirements support lightweight deployment, making it ideal for resource-constrained scenarios (e.g., small to medium-sized businesses or standard cloud deployments).
It is better suited for applications requiring quick deployment and low-cost operations.
Llama 4 Maverick vs Gemma 3 27B: Applications
Llama 4 Maverick
- Enterprise-Level AI: Large-scale applications like document analysis, legal/financial data review.
- Research & Development: Ideal for academic research, long-context reasoning (128K tokens).
- Advanced AI Services: Multilingual chatbots, domain-specific solutions (e.g., medical/legal).
- Multimodal AI: Combines text, images, and other modalities for creative or analytical tasks.
- Government & Defense: For large-scale, sensitive data processing and predictive analytics.
Gemma 3 27B
- Small to Medium Businesses (SMBs): Customer support chatbots, text summarization, content generation.
- Cloud-Based Solutions: Lightweight AI tools easily deployable on standard cloud infrastructure.
- Education: AI tutoring, automated grading, and text simplification.
- AI Prototyping: Ideal for testing ideas and building lightweight prototypes.
- Apple Silicon Support: Optimized for macOS environments and Apple hardware.
How to Access Llama 4 Maverick and Gemma 3 27B via Novita API?
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Try Llama 4 Maverick and Gemma 3 27B Demo Now!
Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
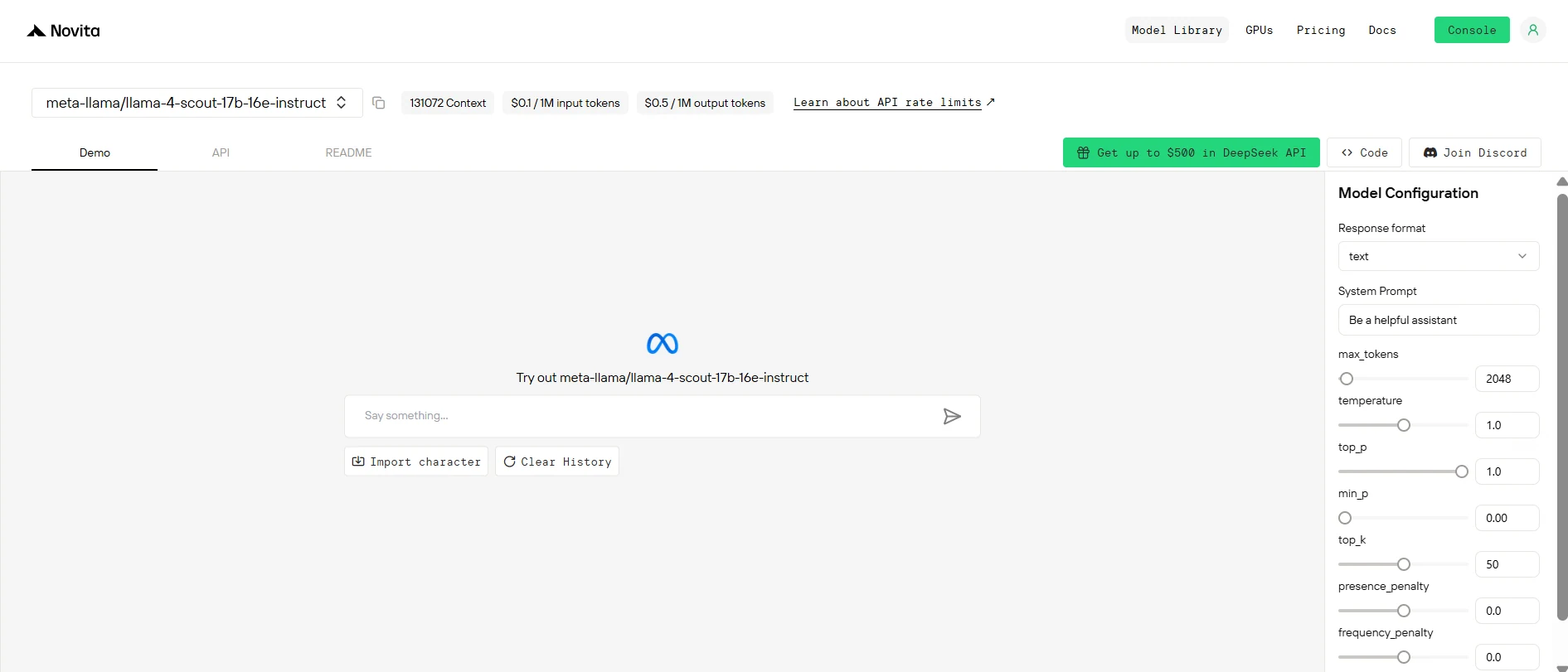
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Llama 4 Maverick and Gemma 3 27B cater to different audiences and applications. Llama 4 Maverick stands out for its superior performance and scalability, making it ideal for enterprises and research-intensive tasks. In contrast, Gemma 3 27B excels in lightweight, cost-efficient use cases, perfect for smaller organizations or developers with limited resources. Choose the model that aligns with your requirements, whether it’s high complexity or ease of deployment.
Frequently Asked Questions
Which model is better for real-time tasks?
Llama 4 Maverick significantly outperforms Gemma 3 27B in response speed and latency, making it better for real-time applications.
Can Gemma 3 27B handle long-context reasoning like Llama 4 Maverick?
No, while Gemma 3 27B offers a 128K token context window, it lacks the computational power and efficiency of Llama 4 Maverick for ultra-long-context reasoning tasks.
How to access Llama 4 Maverick and Gemma 3 27B?
Novita AI providing the affordable and reliable API for you.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



