

Puntos clave
Notable ventaja de coste: Requiere poca VRAM, tiene requisitos de hardware modestos, lo que permite su funcionamiento en hardware común.
Rendimiento sobresaliente: Destaca en múltiples tareas como conocimiento general, procesamiento de código, razonamiento matemático, razonamiento lógico y procesamiento multilingüe, con gran versatilidad y adaptabilidad a las tareas.
Precio atractivo en Novita AI: Con un precio altamente competitivo en Novita AI de $0.02 por cada 1M de tokens de entrada y $0.05 por cada 1M de tokens de salida,
Para desarrolladores, aficionados y pequeñas y medianas empresas, la búsqueda de un modelo de IA a menudo conlleva un punto doloroso común: equilibrar el rendimiento y el coste. Muchos buscan una solución que no requiera una inversión masiva en hardware de gama alta ni que rompa el banco en costes de tokens, pero que aún así ofrezca resultados fiables en una variedad de tareas. Llama 3.1 8B surge como la respuesta ideal a estas preocupaciones.
Recomienda a tus amigos Novita AI y ambos ganaréis $10 en créditos de API LLM, hasta $500 en recompensas totales.
Para apoyar a la comunidad de desarrolladores, Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B están actualmente disponibles de forma gratuita en Novita AI.

¿Qué es Llama 3.1 8B?
LLaMA 3.1 8B es un modelo de lenguaje grande de código abierto construido con una arquitectura de transformador denso. Soporta múltiples idiomas y ofrece un rendimiento sólido tanto en generación de texto como de código, lo que lo hace adecuado para aplicaciones de propósito general.

- Tamaño del modelo: 1B
- Código abierto: Sí
- Arquitectura: Transformador denso
- Longitud de contexto: 128,000 tokens
Soporte de idiomas
Soporta inglés, alemán, francés, italiano, portugués, hindi, español y tailandés.
Capacidad multimodal
Acepta texto como entrada y genera texto o código como salida. No soporta entradas de imagen o audio.
Datos de entrenamiento
Preentrenado con aproximadamente 15 billones de tokens de fuentes disponibles públicamente. Ajustado con más de 25 millones de ejemplos de instrucciones generadas sintéticamente, junto con conjuntos de datos de instrucciones públicas.
Benchmark de Llama 3.1 8B (comparado con otros modelos)
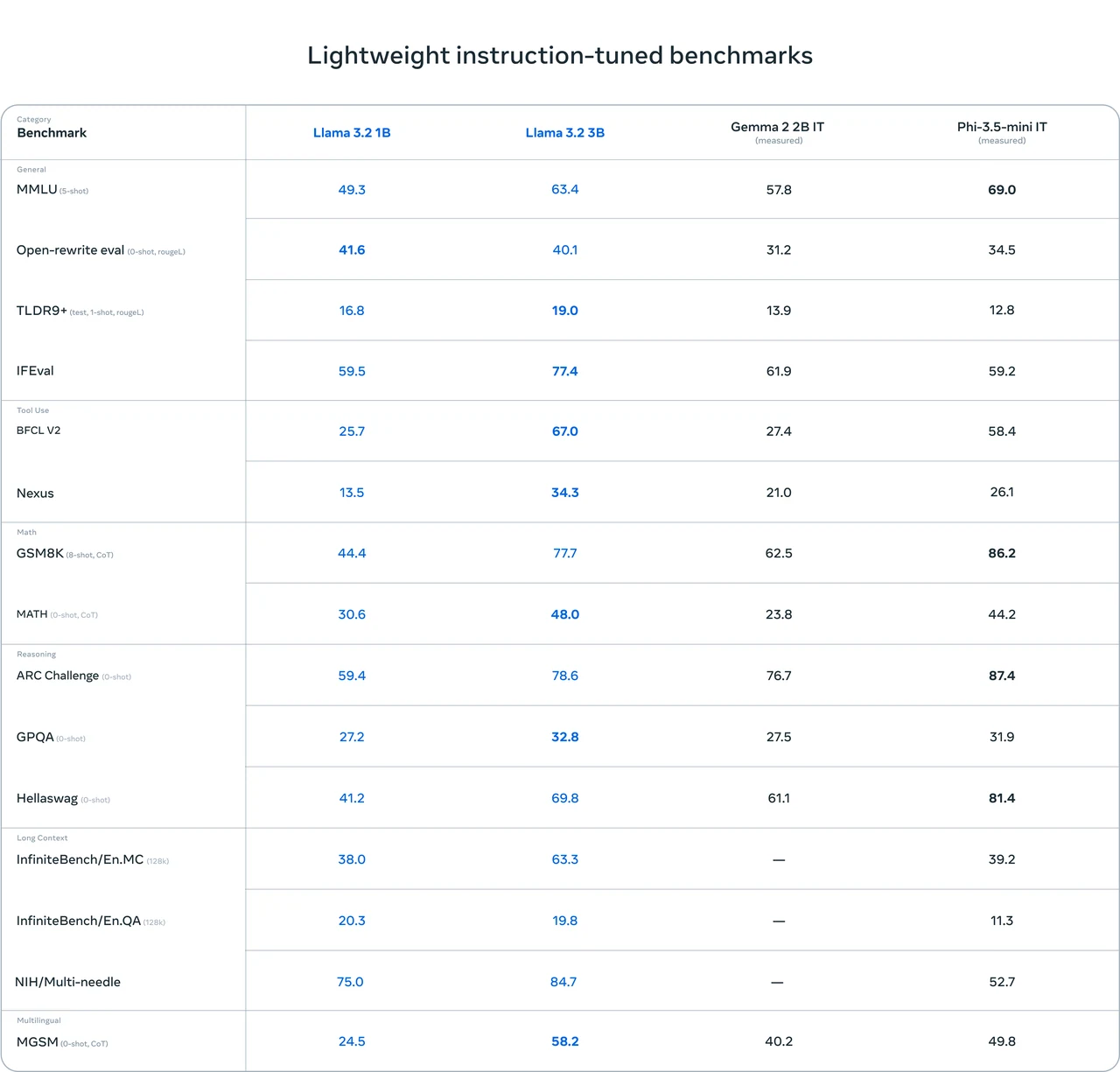
- Buen rendimiento integral: Llama 3.1 8B ha obtenido resultados relativamente buenos en múltiples pruebas de referencia. Por ejemplo, tiene puntuaciones altas en pruebas como IFEval (80.4) y GSM8K (8 disparos, CoT) (84.5), lo que indica que tiene ciertas fortalezas en capacidades de propósito general, razonamiento matemático, etc.
- Excelente habilidad de codificación: Se desempeña bien en pruebas relacionadas con código como HumanEval (0 disparos) (72.6) y MBPP EvalPlus (base) (0 disparos) (72.8), lo que sugiere que tiene fuertes capacidades en tareas de manejo de código.
- Margen de mejora: Sus puntuaciones no son las más altas en algunas pruebas, como MATH (0 disparos, CoT) (51.9) y GPQA (0 disparos, CoT) (32.8). Esto implica que todavía hay espacio para mejorar el rendimiento en escenarios específicos de razonamiento matemático y respuesta a preguntas.
Requisitos de hardware de Llama 3.1 8B
| Modelo | VRAM requerida (FP16) | GPUs típicas |
|---|---|---|
| LLaMA 3.1 8B | 17.17 GB | RTX 3090 (12 GB, no suficiente) 2× RTX 4060 (8 GB cada una) |
| Qwen3-8B | 17.89 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3 8B | 17.17 GB | RTX 3090 2× RTX 4060 |
| Gemma 3 4B | 10.29 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3.2 1B | 3.14 GB | RTX 4060 |
Si bien LLaMA 3.1 8B ofrece un equilibrio bien optimizado entre capacidad y uso de memoria dentro de la clase de 8B parámetros, su demanda de hardware sigue siendo elevada para la mayoría de los aficionados o desarrolladores con una sola GPU. Para despliegues ligeros, modelos más pequeños como Gemma 3 4B o LLaMA 3.2 1B ofrecen requisitos de VRAM significativamente más bajos, lo que los hace más accesibles en hardware de grado de consumo.
Cómo acceder a Llama 3.2 1B?
Paso 1: Iniciar sesión y acceder a la Biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Paso 2: Elegir tu modelo
Navega entre las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comenzar tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtener tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Ingresa a la página de “Configuración” y copia la clave de API como se indica en la imagen.

Paso 5: Instalar la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.1-8b-instruct-bf16"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
LLaMA 3.1 8B logra un equilibrio entre rendimiento y escalabilidad, especialmente en tareas multilingües y de codificación. Sin embargo, los desarrolladores con hardware limitado pueden encontrar exigentes sus requisitos. Para casos de uso ligeros, Llama 3.2 1B o Gemma 3 4B ofrecen alternativas rentables. Con el acceso a la API de Novita AI, los desarrolladores pueden explorar estos modelos fácilmente sin invertir en GPUs de alta gama.
Preguntas frecuentes
¿Qué es Llama 3.1 8B?
Un modelo de código abierto de 8B parámetros optimizado para generación de texto y código de propósito general.
¿Puedo ejecutar Llama 3.1 8B en una sola GPU?
La inferencia requiere 3.14 GB de VRAM; el ajuste fino necesita 14.11 GB de VRAM.
¿Dónde puedo usar Llama 3.1 8B?
Puedes acceder a él a través de la plataforma Novita AI utilizando su sencilla API de Python para completaciones de chat y más.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una manera sencilla de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.



