

Key Highlights
Notable Cost Advantage: Demands low VRAM, has modest hardware requirements, enabling operation on common hardware.
Outstanding Performance: Excels in multi - tasks including general knowledge, code processing, mathematical reasoning, logical reasoning, and multilingual processing, featuring strong versatility and task adaptability.
Attractive Pricing on Novita AI: With a highly competitive price on Novita AI at $0.02 per 1M input tokens and $0.05 per 1M output tokens,
For developers, hobbyists, and small - to - medium - sized businesses, the pursuit of an AI model often comes with a common pain point: balancing performance and cost. Many are looking for a solution that doesn’t require a massive investment in high - end hardware or break the bank on token costs, yet still delivers reliable results across a range of tasks. Llama 3.1 8B emerges as the ideal answer to these concerns.
Refer your friends to Novita AI and both of you will earn $10 in LLM API credits—up to $500 in total rewards.
To support the developer community, Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B is currently available for free on Novita AI.

What is Llama 3.1 8B?
LLaMA 3.1 8B is an open-source large language model built with a dense transformer architecture. It supports multiple languages and delivers strong performance in both text and code generation, making it suitable for general-purpose applications.

- Model Size: 1B
- Open Source: Yes
- Architecture: Dense Transform
- Context Length: 128,000 tokens
Language Support
Supports English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
Multimodal Capability
Accepts text as input and generates text or code as output. It does not support image or audio inputs.
Training Data
Pretrained on approximately 15 trillion tokens from publicly available sources. Fine-tuned with more than 25 million synthetically generated instruction examples, along with public instruction datasets.
Llama 3.1 8B Benchmark( VS Other Models)
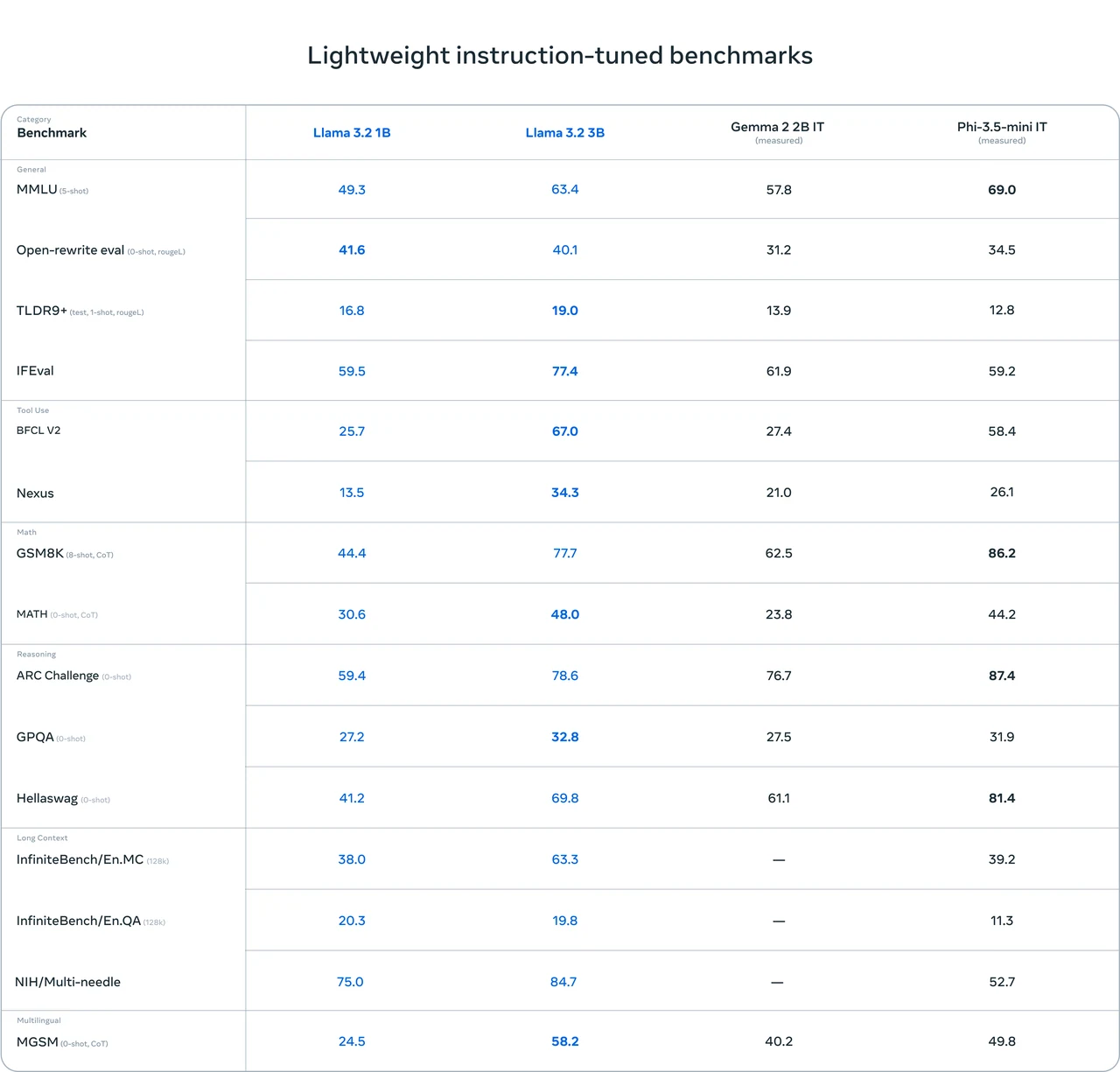
- Good comprehensive performance: Llama 3.1 8B has achieved relatively good results in multiple benchmark tests. For example, it has high scores in tests such as IFEval (80.4) and GSM8K (8 - shot, CoT) (84.5), indicating that it has certain strengths in general - purpose capabilities, mathematical reasoning, etc.
- Outstanding coding ability: It performs well in code - related tests such as HumanEval (0 - shot) (72.6) and MBPP EvalPlus (base) (0 - shot) (72.8), suggesting that it has strong capabilities in code - handling tasks.
- Room for improvement: Its scores are not the highest in some tests, such as MATH (0 - shot, CoT) (51.9) and GPQA (0 - shot, CoT) (32.8). This implies that there is still room for performance improvement in specific mathematical reasoning and question - answering scenarios.
Llama 3.1 8B Hardware Requirements
| Model | VRAM Required (FP16) | Typical GPUs |
|---|---|---|
| LLaMA 3.1 8B | 17.17 GB | RTX 3090 (12 GB, not sufficient) 2× RTX 4060 (8 GB each) |
| Qwen3-8B | 17.89 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3 8B | 17.17 GB | RTX 3090 2× RTX 4060 |
| Gemma 3 4B | 10.29 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3.2 1B | 3.14 GB | RTX 4060 |
While LLaMA 3.1 8B offers a well-optimized balance of capability and memory use within the 8B parameter class, its hardware demand remains steep for most hobbyists or developers with a single GPU. For lightweight deployment, smaller models like Gemma 3 4B or LLaMA 3.2 1B offer significantly lower VRAM requirements, making them more accessible on consumer-grade hardware.
How to Access Llama 3.2 1B?
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.1-8b-instruct-bf16"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
LLaMA 3.1 8B strikes a balance between performance and scalability, especially in multilingual and coding tasks. However, developers with limited hardware may find its requirements demanding. For lightweight use cases, Llama 3.2 1B or Gemma 3 4B provide cost-effective alternatives. With Novita AI’s API access, developers can explore these models easily without investing in high-end GPUs.
Frequently Asked Questions
What is Llama 3.1 8B?
An open-source 8B parameter model optimized for general-purpose text and code generation.
Can I run llama 3.1 8b on a single GPU?
Inference requires 3.14 GB VRAM; fine-tuning needs 14.11 GB VRAM.
Where can I use llama 3.1 8b ?
You can access it via the Novita AI platform using their simple Python API for chat completions and more.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



