

主なハイライト
注目すべきコスト優位性 :低VRAM要件、控えめなハードウェア要件で、一般的なハードウェアでも動作可能。
優れたパフォーマンス :一般的な知識、コード処理、数学的推論、論理的推論、多言語処理など、マルチタスクで優れた性能を発揮。汎用性とタスク適応性が高い。
Novita AI の魅力的な価格設定 :Novita AI では、入力トークン100万トークンあたり0.02ドル、出力トークン100万トークンあたり0.05ドルと非常に競争力のある価格を提供しています。
開発者、ホビイスト、中小企業にとって、AIモデルの追求には、パフォーマンスとコストのバランスを取るという共通の課題がつきものです。多くの人は、ハイエンドハードウェアへの大規模な投資やトークンコストで予算を圧迫することなく、さまざまなタスクで信頼性の高い結果を提供するソリューションを求めています。Llama 3.1 8B は、こうした懸念に理想的な答えとして登場しました。
友達を Novita AI に紹介すると、あなたも友達もそれぞれ10ドル分の LLM API クレジットを獲得できます(最大500ドルまで)。
開発者コミュニティを支援するため、Llama 3.2 1B、Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B は現在 Novita AI で無料でご利用いただけます。

Llama 3.1 8B とは?
LLaMA 3.1 8B は、高密度トランスフォーマーアーキテクチャを採用したオープンソースの大規模言語モデルです。複数の言語をサポートし、テキスト生成とコード生成の両方で優れたパフォーマンスを発揮するため、汎用的なアプリケーションに適しています。

- モデルサイズ: 1B
- オープンソース: はい
- アーキテクチャ: 高密度トランスフォーマー
- コンテキスト長: 128,000 トークン
対応言語
英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語に対応。
マルチモーダル機能
テキスト入力を受け付け、テキストまたはコードを出力として生成します。画像や音声の入力には対応していません。
トレーニングデータ
公開ソースから約15兆トークンで事前学習。2500万以上の合成生成された指示例と、公開指示データセットでファインチューニングされています。
Llama 3.1 8B ベンチマーク(他のモデルとの比較)
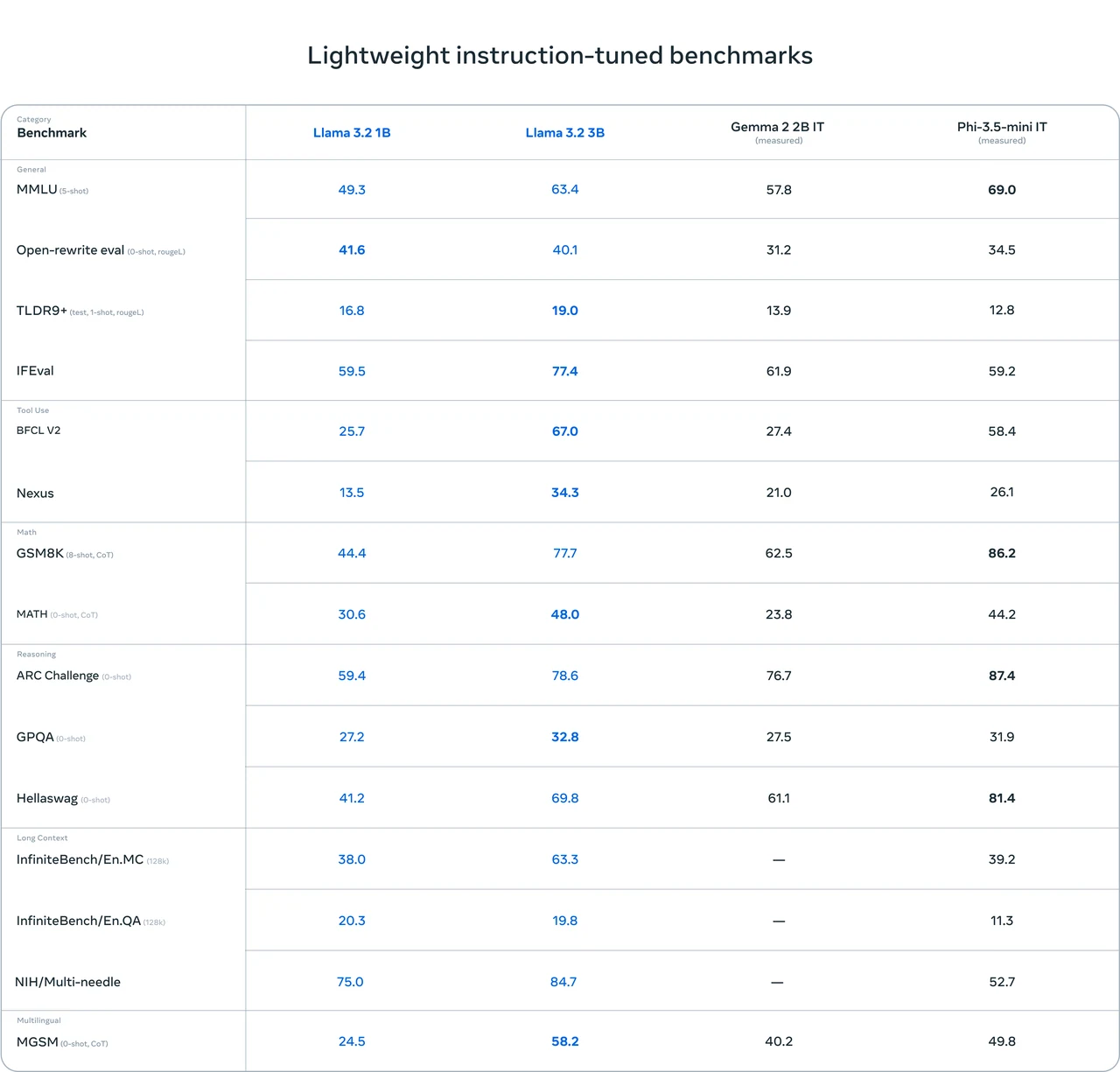
- 優れた総合性能 :Llama 3.1 8B は複数のベンチマークテストで比較的良好な結果を達成しています。例えば、IFEval(80.4)やGSM8K(8-shot、CoT)(84.5)などのテストで高スコアを示し、汎用能力や数学的推論などに一定の強みがあることを示しています。
- 優れたコーディング能力 :HumanEval(0-shot)(72.6)やMBPP EvalPlus(base)(0-shot)(72.8)などのコード関連テストで良好なパフォーマンスを発揮し、コード処理タスクに強い能力を持つことを示唆しています。
- 改善の余地 :MATH(0-shot、CoT)(51.9)やGPQA(0-shot、CoT)(32.8)などの一部のテストではスコアが最高ではありません。これは、特定の数学的推論や質問応答のシナリオにおいて、パフォーマンス向上の余地がまだあることを意味します。
Llama 3.1 8B ハードウェア要件
| モデル | VRAM 要件 (FP16) | 一般的なGPU |
|---|---|---|
| LLaMA 3.1 8B | 17.17 GB | RTX 3090(12 GB、不十分) 2× RTX 4060(各8 GB) |
| Qwen3-8B | 17.89 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3 8B | 17.17 GB | RTX 3090 2× RTX 4060 |
| Gemma 3 4B | 10.29 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3.2 1B | 3.14 GB | RTX 4060 |
LLaMA 3.1 8B は8Bパラメータクラス内で能力とメモリ使用量のバランスが良好に最適化されていますが、**単一GPUを使用するほとんどのホビイストや開発者にとって、そのハードウェア要求は依然として高いものがあります **。軽量デプロイメントには、Gemma 3 4B や LLaMA 3.2 1B などの小型モデルの方がVRAM要件が大幅に低く、一般消費者向けハードウェアでもよりアクセスしやすくなっています。
Llama 3.1 8B にアクセスする方法
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。

ステップ3:無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
ステップ4:API キーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに移動し、画像のように API キーをコピーします。

ステップ5:API のインストール
ご使用のプログラミング言語に固有のパッケージマネージャーを使用して API をインストールします。
インストール後、必要なライブラリを開発環境にインポートします。API キーを使って API を初期化し、Novita AI LLM との対話を開始します。以下は Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.1-8b-instruct-bf16"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
LLaMA 3.1 8B は、特に多言語処理やコーディングタスクにおいて、パフォーマンスとスケーラビリティのバランスを実現しています。ただし、ハードウェアに制限のある開発者にとっては、その要件が高いと感じるかもしれません。軽量なユースケースには、Llama 3.2 1B や Gemma 3 4B がコスト効率の良い代替案を提供します。Novita AI の API アクセスを通じて、開発者はハイエンド GPU に投資することなく、これらのモデルを簡単に試すことができます。
よくある質問
Llama 3.1 8B とは何ですか?
汎用的なテキスト生成とコード生成に最適化された、オープンソースの8Bパラメータモデルです。
Llama 3.1 8B を1台の GPU で実行できますか?
推論には3.14 GBのVRAM、ファインチューニングには14.11 GBのVRAMが必要です。
Llama 3.1 8B はどこで使用できますか?
Novita AI プラットフォームから、シンプルな Python API を使用してチャット補完などにアクセスできます。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできると同時に、手頃で信頼性の高い GPU クラウドを構築およびスケーリングのために提供する AI クラウドプラットフォームです。



