

Wichtige Highlights
Bemerkenswerter Kostenvorteil: Geringer VRAM-Bedarf, bescheidene Hardware-Anforderungen, ermöglicht Betrieb auf handelsüblicher Hardware.
Herausragende Leistung: Hervorragend bei mehreren Aufgaben, darunter Allgemeinwissen, Code-Verarbeitung, mathematisches Denken, logisches Denken und mehrsprachige Verarbeitung, mit starker Vielseitigkeit und Aufgabenanpassungsfähigkeit.
Attraktive Preise auf Novita AI: Mit einem äußerst wettbewerbsfähigen Preis auf Novita AI von 0,02 $ pro 1M Input-Token und 0,05 $ pro 1M Output-Token.
Für Entwickler, Hobbyisten und kleine bis mittlere Unternehmen ist die Suche nach einem KI-Modell oft mit einem häufigen Problem verbunden: dem Abwägen zwischen Leistung und Kosten. Viele suchen nach einer Lösung, die keine massive Investition in High-End-Hardware erfordert oder das Budget durch Token-Kosten sprengt, aber dennoch zuverlässige Ergebnisse bei einer Reihe von Aufgaben liefert. Llama 3.1 8B erweist sich als ideale Antwort auf diese Anliegen.
Empfehlen Sie Freunden Novita AI und Sie beide erhalten 10 $ in LLM-API-Guthaben – insgesamt bis zu 500 $ Belohnungen.
Um die Entwickler-Community zu unterstützen, sind Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B derzeit kostenlos auf Novita AI verfügbar.

Was ist Llama 3.1 8B?
LLaMA 3.1 8B ist ein Open-Source-Sprachmodell mit einer dichten Transformer-Architektur. Es unterstützt mehrere Sprachen und liefert starke Leistungen sowohl bei der Text- als auch bei der Code-Generierung, was es für allgemeine Anwendungen geeignet macht.

- Modellgröße: 1B
- Open Source: Ja
- Architektur: Dense Transformer
- Kontextlänge: 128.000 Token
Sprachunterstützung
Unterstützt Englisch, Deutsch, Französisch, Italienisch, Portugiesisch, Hindi, Spanisch und Thailändisch.
Multimodale Fähigkeiten
Akzeptiert Text als Eingabe und generiert Text oder Code als Ausgabe. Es unterstützt keine Bild- oder Audio-Eingaben.
Trainingsdaten
Vortrainiert auf etwa 15 Billionen Token aus öffentlich zugänglichen Quellen. Feinabstimmung mit mehr als 25 Millionen synthetisch generierten Instruktionsbeispielen sowie öffentlichen Instruktionsdatensätzen.
Llama 3.1 8B Benchmark (vs. andere Modelle)
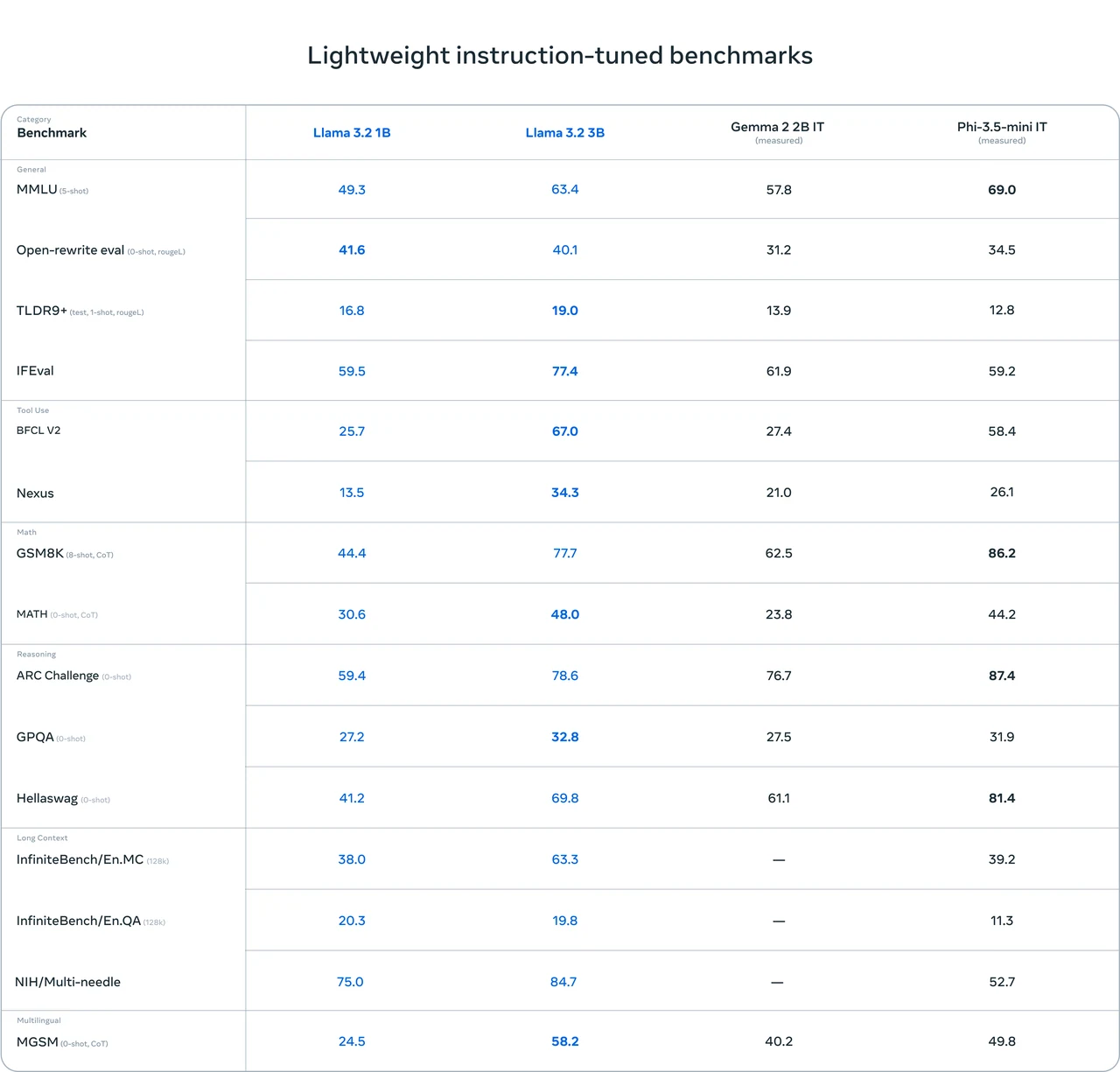
- Gute Gesamtleistung: Llama 3.1 8B hat in mehreren Benchmark-Tests relativ gute Ergebnisse erzielt. Beispielsweise hat es hohe Punktzahlen in Tests wie IFEval (80,4) und GSM8K (8-shot, CoT) (84,5), was darauf hindeutet, dass es gewisse Stärken in allgemeinen Fähigkeiten und mathematischem Denken hat.
- Hervorragende Programmierfähigkeit: Es schneidet gut in Code-bezogenen Tests ab, wie HumanEval (0-shot) (72,6) und MBPP EvalPlus (base) (0-shot) (72,8), was auf starke Fähigkeiten bei der Verarbeitung von Code-Aufgaben hinweist.
- Verbesserungspotenzial: Seine Punktzahlen sind in einigen Tests nicht die höchsten, z. B. in MATH (0-shot, CoT) (51,9) und GPQA (0-shot, CoT) (32,8). Dies deutet darauf hin, dass in bestimmten mathematischen Denk- und Frage-Antwort-Szenarien noch Raum für Leistungssteigerungen besteht.
Llama 3.1 8B Hardware-Anforderungen
| Modell | Erforderlicher VRAM (FP16) | Typische GPUs |
|---|---|---|
| LLaMA 3.1 8B | 17,17 GB | RTX 3090 (12 GB, nicht ausreichend) 2× RTX 4060 (8 GB je) |
| Qwen3-8B | 17,89 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3 8B | 17,17 GB | RTX 3090 2× RTX 4060 |
| Gemma 3 4B | 10,29 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3.2 1B | 3,14 GB | RTX 4060 |
Während LLaMA 3.1 8B ein gut optimiertes Gleichgewicht zwischen Leistung und Speichernutzung innerhalb der 8B-Parameterklasse bietet, bleibt der Hardwarebedarf für die meisten Hobbyisten oder Entwickler mit einer einzelnen GPU hoch. Für eine leichte Bereitstellung bieten kleinere Modelle wie Gemma 3 4B oder LLaMA 3.2 1B deutlich geringere VRAM-Anforderungen, was sie auf Consumer-Hardware zugänglicher macht.
Wie greife ich auf Llama 3.2 1B zu?
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Jetzt Llama 3.1 8B ausprobieren!
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Um sich bei der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite „Einstellungen“ auf und kopieren Sie den API-Schlüssel, wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<Ihr Novita AI API-Schlüssel>",
)
model = "meta-llama/llama-3.1-8b-instruct-bf16"
stream = True # oder False
max_tokens = 2048
system_content = """Sei ein hilfreicher Assistent"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
LLaMA 3.1 8B bietet eine ausgewogene Mischung aus Leistung und Skalierbarkeit, insbesondere bei mehrsprachigen und Programmieraufgaben. Entwickler mit begrenzter Hardware könnten die Anforderungen jedoch als anspruchsvoll empfinden. Für leichte Anwendungsfälle bieten Llama 3.2 1B oder Gemma 3 4B kosteneffiziente Alternativen. Mit dem API-Zugang von Novita AI können Entwickler diese Modelle problemlos erkunden, ohne in High-End-GPUs investieren zu müssen.
Häufig gestellte Fragen
Was ist Llama 3.1 8B?
Ein Open-Source-Modell mit 8B Parametern, optimiert für allgemeine Text- und Code-Generierung.
Kann ich Llama 3.1 8B auf einer einzelnen GPU ausführen?
Die Inferenz erfordert 3,14 GB VRAM; die Feinabstimmung benötigt 14,11 GB VRAM.
Wo kann ich Llama 3.1 8B verwenden?
Sie können über die Novita AI-Plattform darauf zugreifen, indem Sie deren einfache Python-API für Chat-Completions und mehr verwenden.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bereitstellt.



