

Destaques Principais
Vantagem de Custo Notável: Exige pouca VRAM, possui requisitos de hardware modestos, permitindo operação em hardware comum.
Desempenho Excepcional: Destaca-se em múltiplas tarefas, incluindo conhecimento geral, processamento de código, raciocínio matemático, raciocínio lógico e processamento multilíngue, com forte versatilidade e adaptabilidade a tarefas.
Preço Atrativo na Novita AI: Com um preço altamente competitivo na Novita AI a $0,02 por 1M de tokens de entrada e $0,05 por 1M de tokens de saída.
Para desenvolvedores, entusiastas e pequenas e médias empresas, a busca por um modelo de IA frequentemente enfrenta um ponto doloroso comum: equilibrar desempenho e custo. Muitos procuram uma solução que não exija um grande investimento em hardware de ponta nem pese no orçamento com custos de tokens, mas que ainda entregue resultados confiáveis em uma variedade de tarefas. O Llama 3.1 8B surge como a resposta ideal para essas preocupações.
Indique seus amigos para a Novita AI e ambos ganharão $10 em créditos da API LLM — até $500 em recompensas totais.
Para apoiar a comunidade de desenvolvedores, o Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B está atualmente disponível gratuitamente na Novita AI.

O que é o Llama 3.1 8B?
O LLaMA 3.1 8B é um modelo de linguagem grande de código aberto construído com uma arquitetura transformer densa. Ele suporta vários idiomas e oferece forte desempenho tanto na geração de texto quanto de código, sendo adequado para aplicações de uso geral.

- Tamanho do Modelo: 1B
- Código Aberto: Sim
- Arquitetura: Transformer Denso
- Comprimento de Contexto: 128.000 tokens
Suporte a Idiomas
Suporta inglês, alemão, francês, italiano, português, hindi, espanhol e tailandês.
Capacidade Multimodal
Aceita texto como entrada e gera texto ou código como saída. Não suporta entradas de imagem ou áudio.
Dados de Treinamento
Pré-treinado em aproximadamente 15 trilhões de tokens de fontes publicamente disponíveis. Ajustado com mais de 25 milhões de exemplos de instrução gerados sinteticamente, juntamente com conjuntos de dados de instrução públicos.
Benchmark do Llama 3.1 8B (Comparado com Outros Modelos)
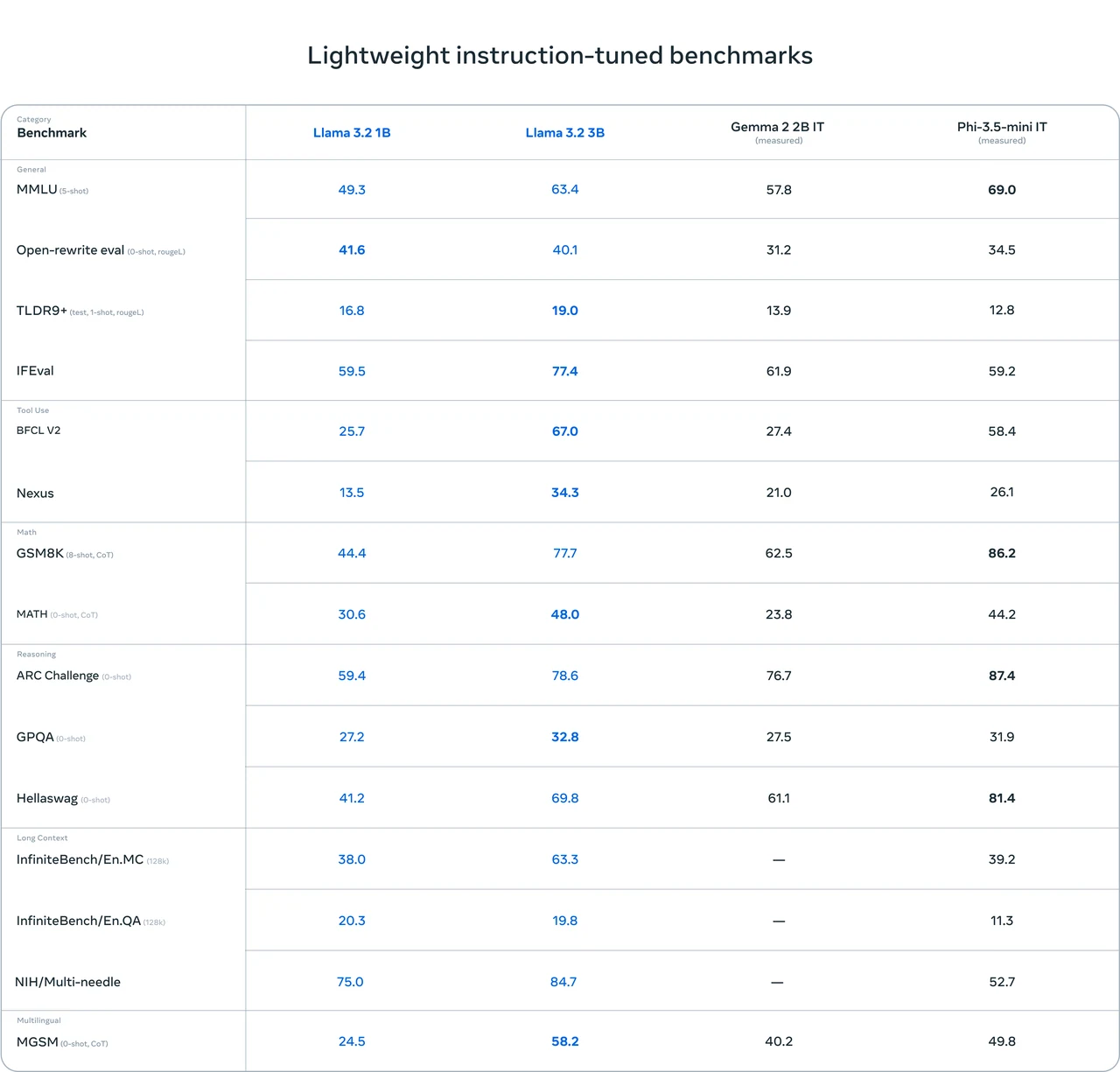
- Bom desempenho geral: O Llama 3.1 8B obteve resultados relativamente bons em vários testes de benchmark. Por exemplo, possui pontuações altas em testes como IFEval (80,4) e GSM8K (8-shot, CoT) (84,5), indicando que tem certos pontos fortes em capacidades gerais, raciocínio matemático, etc.
- Excelente habilidade de codificação: Apresenta bom desempenho em testes relacionados a código, como HumanEval (0-shot) (72,6) e MBPP EvalPlus (base) (0-shot) (72,8), sugerindo forte capacidade em tarefas de manipulação de código.
- Espaço para melhoria: Suas pontuações não são as mais altas em alguns testes, como MATH (0-shot, CoT) (51,9) e GPQA (0-shot, CoT) (32,8). Isso implica que ainda há espaço para melhoria de desempenho em cenários específicos de raciocínio matemático e perguntas e respostas.
Requisitos de Hardware do Llama 3.1 8B
| Modelo | VRAM Necessária (FP16) | GPUs Típicas |
|---|---|---|
| LLaMA 3.1 8B | 17,17 GB | RTX 3090 (12 GB, insuficiente) 2× RTX 4060 (8 GB cada) |
| Qwen3-8B | 17,89 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3 8B | 17,17 GB | RTX 3090 2× RTX 4060 |
| Gemma 3 4B | 10,29 GB | RTX 3090 2× RTX 4060 |
| LLaMA 3.2 1B | 3,14 GB | RTX 4060 |
Embora o LLaMA 3.1 8B ofereça um equilíbrio bem otimizado entre capacidade e uso de memória dentro da classe de 8B parâmetros, sua demanda de hardware ainda é alta para a maioria dos entusiastas ou desenvolvedores com uma única GPU. Para implantações leves, modelos menores como Gemma 3 4B ou LLaMA 3.2 1B oferecem requisitos de VRAM significativamente menores, tornando-os mais acessíveis em hardware de consumo.
Como Acessar o Llama 3.2 1B?
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Experimente o Llama 3.1 8B Agora!
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos a você uma nova chave de API. Acesse a página “Settings“ e copie a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<SUA CHAVE DE API Novita AI>",
)
model = "meta-llama/llama-3.1-8b-instruct-bf16"
stream = True # ou False
max_tokens = 2048
system_content = """Seja um assistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
O LLaMA 3.1 8B equilibra desempenho e escalabilidade, especialmente em tarefas multilíngues e de codificação. No entanto, desenvolvedores com hardware limitado podem achar seus requisitos exigentes. Para casos de uso leves, o Llama 3.2 1B ou Gemma 3 4B oferecem alternativas econômicas. Com o acesso à API da Novita AI, os desenvolvedores podem explorar esses modelos facilmente sem investir em GPUs de ponta.
Perguntas Frequentes
O que é o Llama 3.1 8B?
Um modelo de código aberto com 8B parâmetros otimizado para geração de texto e código de uso geral.
Posso executar o llama 3.1 8b em uma única GPU?
A inferência requer 3,14 GB de VRAM; o fine-tuning requer 14,11 GB de VRAM.
Onde posso usar o llama 3.1 8b?
Você pode acessá-lo através da plataforma Novita AI usando sua API Python simples para chat completions e muito mais.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem GPU acessível e confiável para construir e escalar.**



