

Points clés
Gemma 3 27B est le dernier modèle de langage open source de Google avec 27 milliards de paramètres, publié en mars 2025.
Il est doté d’une architecture d’attention locale-globale entrelacée avancée et d’une fenêtre de contexte pouvant atteindre 128 000 tokens.
Multilingue et multimodal : prend en charge plus de 140 langues et des tâches de texte à partir d’images.
L’inférence est possible sur un seul GPU H100, mais l’entraînement nécessite beaucoup plus de VRAM (plus de 500 Go).
L’accès via API offre un moyen économique et évolutif d’utiliser Gemma 3 27B sans se soucier du matériel, comme Novita AI.
Gemma 3 27B est un modèle de langage open source de pointe développé par Google. Avec ses puissantes capacités multilingues et multimodales, il est conçu pour le raisonnement avancé, la génération de contenu et une utilisation en entreprise à grande échelle.
Qu’est-ce que Gemma 3 27B ?
Aperçu de Gemma 3 27B
Fonctionnalités et innovations clés du dernier grand modèle open source
📅Informations de base
Date de publication : 12 mars 2025
Taille du modèle : 27B paramètres
Open Source : Oui (Google)
🧠Architecture et contexte
Architecture : Attention locale-globale entrelacée
Fenêtre de contexte : Jusqu’à 128 000 tokens (modèle 1B : 32 000)
Gestion optimisée de la mémoire : Un ratio d’attention locale/globale accru et une minimisation de l’explosion du cache KV réduisent considérablement la surcharge mémoire.
Contexte plus long et efficacité mémoire pour des entrées et inférences à grande échelle.
🌐Multilingue et multimodal
Multilingue : Prend en charge plus de 140 langues
Capacité multimodale : Texte à partir d’images avec l’encodeur visuel SigLIP, permettant un traitement efficace des données visuelles.
Multimodal : Texte à partir d’images et support multilingue pour des scénarios variés.
⚡Performances et entraînement
Performances améliorées : La version 4B optimisée par instructions égale les performances de Gemma 2 27B, plus efficace à plus petite échelle.
Données d’entraînement : 14 000 milliards de tokens
Méthodes d’entraînement : Distillation de connaissances, entraînement avancé sensible à la quantification (QAT) et RLHF.
La distillation et la QAT réduisent l’utilisation de la VRAM tout en maintenant de bonnes performances.
Benchmark de Gemma 3 27B
Gemma 3 27B a obtenu un score Elo impressionnant de 1339 dans le LMSys Chatbot Arena, le classant parmi les 10 meilleurs modèles aux côtés de concurrents propriétaires de premier plan comme o3-mini. Notamment, Gemma 3 27B offre ces performances exceptionnelles tout en fonctionnant sur un seul GPU NVIDIA H100 – un contraste frappant avec d’autres modèles de sa catégorie.
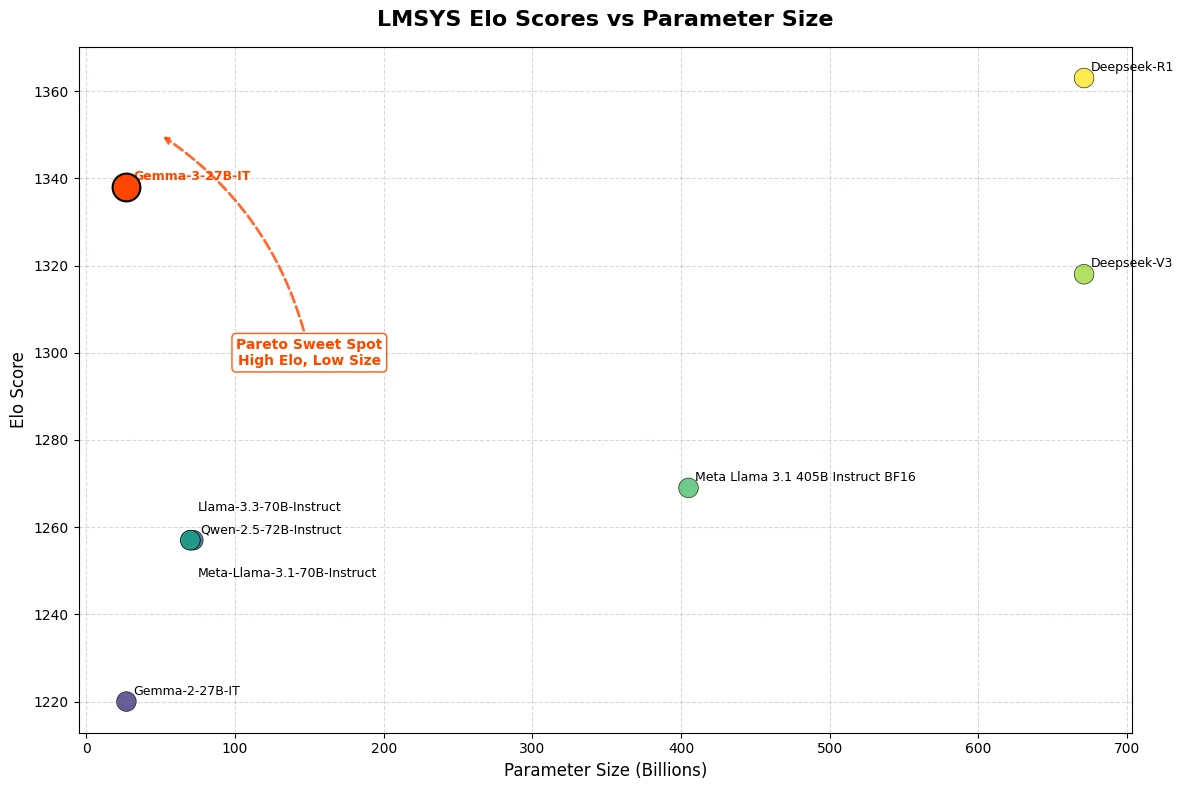
De Hugging Face
La VRAM d’un seul H100 est-elle suffisante pour Gemma 3 27B ?
Aperçu de la VRAM
VRAM (Video Random Access Memory) est la mémoire dédiée d’une carte graphique utilisée pour stocker les données d’image, les paramètres du modèle, les textures et autres informations nécessaires aux tâches exigeantes telles que l’apprentissage profond, le rendu graphique et le traitement vidéo.
Que signifie vraiment une VRAM élevée ?
- Prend en charge des modèles plus grands : Permet de charger et d’exécuter des modèles de réseaux neuronaux plus volumineux avec plus de paramètres ou des entrées de résolution plus élevée.
- Gère des tailles de lots plus grandes : Permet d’utiliser des tailles de lots plus importantes pendant l’entraînement ou l’inférence, améliorant le débit et l’efficacité.
- Permet des tâches plus complexes : Rend possible l’exécution de scènes complexes, de rendu haute définition ou de plusieurs tâches parallèles sans rencontrer de limitations mémoire.
- Réduit les goulots d’étranglement : Évite les ralentissements causés par des transferts fréquents de données entre la mémoire système et la mémoire GPU, améliorant ainsi les performances globales.
Quels sont les besoins en VRAM de Gemma 3 27B ?
Exigences GPU et VRAM de Gemma 3
Gemma 3 1B
GPU recommandé : Nvidia T4
VRAM requise : 16 Go+
Gemma 3 4B
GPU recommandé : Nvidia L4
VRAM requise : 24 Go+
Gemma 3 12B
GPU recommandé : Nvidia L40S
VRAM requise : 48 Go+
Gemma 3 27B
GPU recommandé : Nvidia A100
Considérations sur le stockage et le réseau
- Stockage : Bien qu’un SSD de 500 Go soit un minimum, un SSD NVMe de 1 To ou plus est recommandé pour des performances optimales et la gestion de grands ensembles de données.
- Réseau : Pour les déploiements cloud et les transferts de données volumineux, une vitesse réseau d’au moins 100 Mbps est conseillée pour éviter les retards.
Limitations de l’utilisation d’un seul H100 pour Gemma 3 27B
1. Déploiement (inférence) sur un seul H100
Bien que le NVIDIA H100 (80 Go ou 96 Go de VRAM) soit un GPU haut de gamme, déployer Gemma 3 27B localement sur une seule carte présente des défis importants :
- La VRAM est rapidement saturée :
Les poids du modèle seuls représentent environ 62 Go. Une fois que vous ajoutez les caches d’inférence, les tampons temporaires et des tailles de lots ou des longueurs de séquence plus grandes, vous manquerez rapidement de mémoire – même sur un H100. Des erreurs de mémoire insuffisante (OOM) sont probables si vous essayez de traiter de grandes entrées ou une forte concurrence. - L’évolutivité est limitée :
Un seul GPU limite sévèrement votre capacité à augmenter la taille des lots ou à prendre en charge plusieurs utilisateurs/requêtes. - Pas évolutif pour l’avenir :
À mesure que vos besoins augmentent (par exemple, entrées plus longues, plus d’utilisateurs), un seul H100 ne suffira pas.
Entraînement de Gemma 3 27B : un seul H100 est loin d’être suffisant
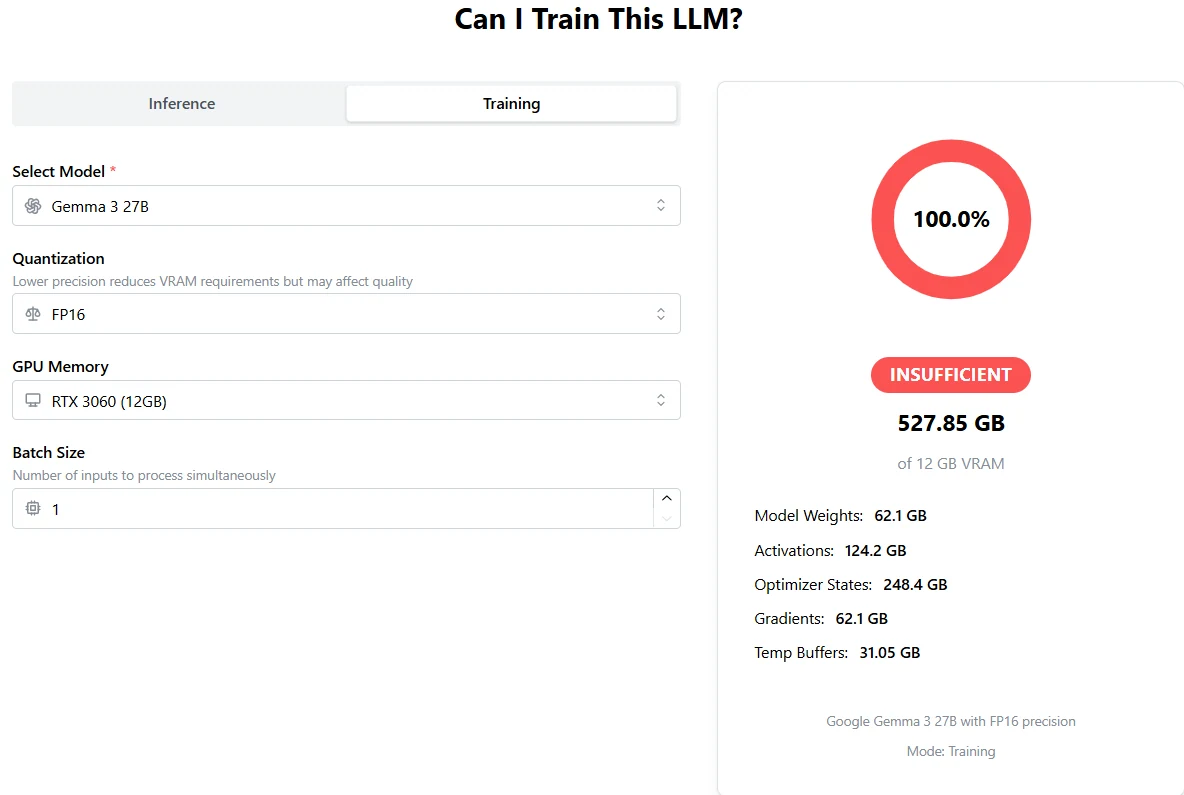
De APX
VRAM totale requise : 527,85 Go
Un seul H100 ne propose que 80 Go (ou 96 Go), ce qui est loin d’être suffisant.
Que se passera-t-il si vous essayez ?
- Impossible de faire tenir toutes les données en mémoire :
L’entraînement ne nécessite pas seulement les poids du modèle, mais aussi les activations, les états de l’optimiseur, les gradients et les tampons temporaires. Leur somme dépasse largement la VRAM d’un seul H100. - Erreurs OOM immédiates :
Le processus d’entraînement ne démarrera pas ou plantera immédiatement en raison d’une mémoire insuffisante. - Nécessité de parallélisation avancée :
Vous seriez obligé d’utiliser des techniques d’entraînement distribué complexes (parallélisme de modèle, parallélisme de pipeline, ZeRO, FSDP, etc.), et même ainsi, une seule carte ne fonctionnera pas – vous aurez besoin d’un cluster de plusieurs GPU haut de gamme. - Goulots d’étranglement de performance :
Même avec des optimisations mémoire, l’entraînement sur une seule carte serait extrêmement lent et peu pratique.
Une méthode d’accès plus économique : l’API
Novita AI est une plateforme cloud IA qui permet aux développeurs de déployer facilement des modèles IA via notre API simple, tout en offrant un cloud GPU abordable et fiable pour construire et faire évoluer vos projets.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez la démo de Gemma 3 27B maintenant !
Étape 2 : Démarrez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 3 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué dans l’image.

Étape 4 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Bien que Gemma 3 27B offre des performances et une flexibilité de pointe, son déploiement ou son entraînement local pose des défis matériels importants. Pour la plupart des utilisateurs, l’utilisation d’une API offre un moyen plus accessible et plus économique d’intégrer ce modèle puissant dans leurs applications.
Foire aux questions
Comment accéder à Gemma 3 27B sans matériel coûteux ?
L’utilisation d’une API cloud (comme Novita AI) est le moyen le plus économique et évolutif de déployer Gemma 3 27B.
Gemma 3 27B est-il multimodal ?
Oui, il prend en charge les entrées d’images et de texte.
Puis-je entraîner Gemma 3 27B sur un seul GPU H100 ?
Non, l’entraînement nécessite plus de 500 Go de VRAM. Un seul H100 (80 Go/96 Go) est loin d’être suffisant.
Novita AI est une plateforme cloud IA qui permet aux développeurs de déployer facilement des modèles IA via notre API simple, tout en offrant un cloud GPU abordable et fiable pour construire et faire évoluer vos projets.



