

主なハイライト
Gemma 3 27B は、2025年3月にリリースされたGoogleの最新オープンソース大規模言語モデルで、270億のパラメータを持ちます。
高度な インターリーブ型ローカル-グローバルアテンションアーキテクチャ と最大128Kトークンのコンテキストウィンドウを備えています。
多言語・マルチモーダル:140以上の言語と画像からテキストへのタスクをサポート。
推論はH100 GPU1基で可能ですが、トレーニングには500GB以上のVRAMが必要です。
APIアクセスは、Novita AIのように、ハードウェアを気にせずGemma 3 27Bを利用するためのコスト効率が高くスケーラブルな方法を提供します。
Gemma 3 27Bは、Googleが開発した最先端のオープンソース大規模言語モデルです。強力な多言語・マルチモーダル機能を備え、高度な推論、コンテンツ生成、幅広いエンタープライズ用途向けに設計されています。
Gemma 3 27Bとは?
Gemma 3 27Bの概要
最新オープンソース大規模モデルの主な機能と革新
📅基本情報
リリース日: 2025年3月12日
モデルサイズ: 270億パラメータ
オープンソース: はい(Google)
🧠アーキテクチャとコンテキスト
アーキテクチャ: インターリーブ型ローカル-グローバルアテンション
コンテキストウィンドウ: 最大128Kトークン(1Bモデル:32K)
最適化されたメモリ管理: ローカル/グローバルアテンション比の向上とKVキャッシュ爆発の最小化により、メモリオーバーヘッドを大幅に削減。
大規模な入力と推論向けの長いコンテキストとメモリ効率。
🌐マルチモーダルと言語
多言語: 140以上の言語をサポート
マルチモーダル機能: SigLIPビジョンエンコーダによる画像からテキストへの変換で、効率的な視覚データ処理を実現。
マルチモーダル:画像からテキストへの変換と多言語サポートにより、幅広いシナリオに対応。
⚡パフォーマンスとトレーニング
パフォーマンス向上: 4B命令チューニング版はGemma 2 27Bの性能に匹敵し、より小規模で効率的。
トレーニングデータ: 14兆トークン
トレーニング手法: 知識蒸留、高度な量子化対応トレーニング(QAT)、RLHF。
蒸留とQATにより、強力なパフォーマンスを維持しながらVRAM使用量を削減。
Gemma 3 27Bベンチマーク
Gemma 3 27Bは、LMSys Chatbot Arenaで印象的なEloスコア1339を達成し、o3-miniなどの主要なクローズドソースモデルと並んでトップ10にランクインしました。特筆すべきは、Gemma 3 27Bがわずか1基のNVIDIA H100 GPU上でこの卓越したパフォーマンスを発揮している点で、同クラスの他のモデルとは対照的です。
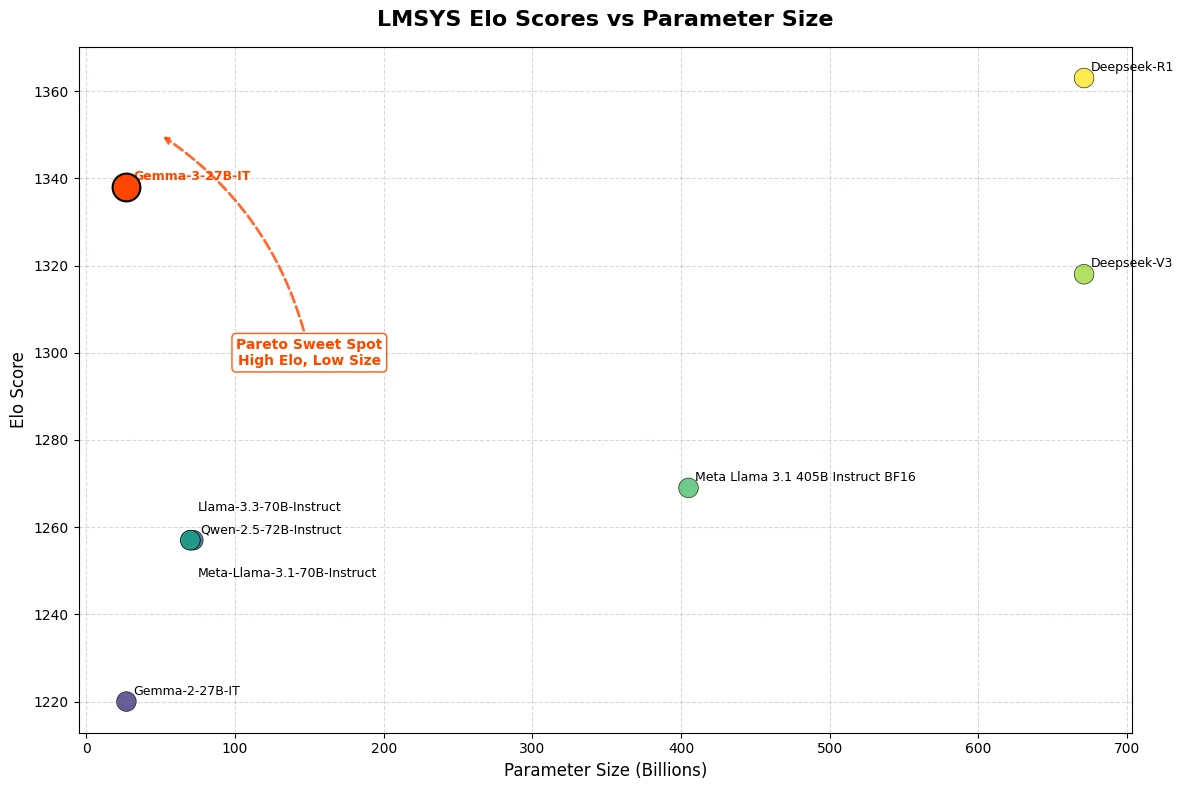
出典:Hugging Face
H100 1基のVRAMはGemma 3 27Bに十分か?
VRAMの概要
VRAM (ビデオランダムアクセスメモリ)は、グラフィックスカード上の専用メモリで、画像データ、モデルパラメータ、テクスチャ、その他ディープラーニング、グラフィックスレンダリング、ビデオ処理などの高性能タスクに必要な情報を保存します。
高いVRAMの本当の意味とは?
- より大きなモデルをサポート: より多くのパラメータや高解像度入力を持つ大規模ニューラルネットワークモデルを読み込んで実行できる。
- より大きなバッチサイズを処理: トレーニングや推論中により大きなバッチサイズを使用可能にし、スループットと効率を向上。
- より複雑なタスクを実現: メモリ制約に陥ることなく、複雑なシーン、高精細レンダリング、複数の並列タスクを実行可能。
- ボトルネックを削減: システムメモリとGPUメモリ間の頻繁なデータ転送による速度低下を防ぎ、全体的なパフォーマンスを向上。
Gemma 3 27BのVRAM要件は?
Gemma 3のGPUとVRAM要件
Gemma 3 1B
推奨GPU: Nvidia T4
必要VRAM: 16GB+
Gemma 3 4B
推奨GPU: Nvidia L4
必要VRAM: 24GB+
Gemma 3 12B
推奨GPU: Nvidia L40S
必要VRAM: 48GB+
Gemma 3 27B
推奨GPU: Nvidia A100
必要VRAM: 80GB+
ストレージとネットワークの考慮事項
- ストレージ: 最低500GB SSDですが、最適なパフォーマンスと大規模データセットの処理には1TB以上のNVMe SSDを推奨します。
- ネットワーク: クラウドデプロイメントや大規模データ転送の場合、遅延を避けるために最低100Mbpsのネットワーク速度が推奨されます。
H100 1基でGemma 3 27Bを使用する際の制限
1. H100 1基でのデプロイ(推論)
NVIDIA H100(80GBまたは96GB VRAM)はトップクラスのGPUですが、1枚のカードでGemma 3 27Bをローカルにデプロイするには重要な課題があります:
- VRAMがすぐに上限に達する: モデルの重みだけでも約62GBあります。推論キャッシュ、一時バッファ、より大きなバッチサイズやシーケンス長を含めると、H100でもすぐにメモリ不足になります。大きな入力や高同時実行を処理しようとすると、メモリ不足(OOM)エラーが発生する可能性が高いです。
- スケーラビリティが制限される: GPU 1基では、バッチサイズの拡大や複数ユーザー/リクエストの処理能力が大幅に制限されます。
- 将来性がない: ニーズが拡大するにつれて(例:より長い入力、より多くのユーザー)、1基のH100では不十分になります。
Gemma 3 27Bのトレーニング:1基のH100では全く不十分
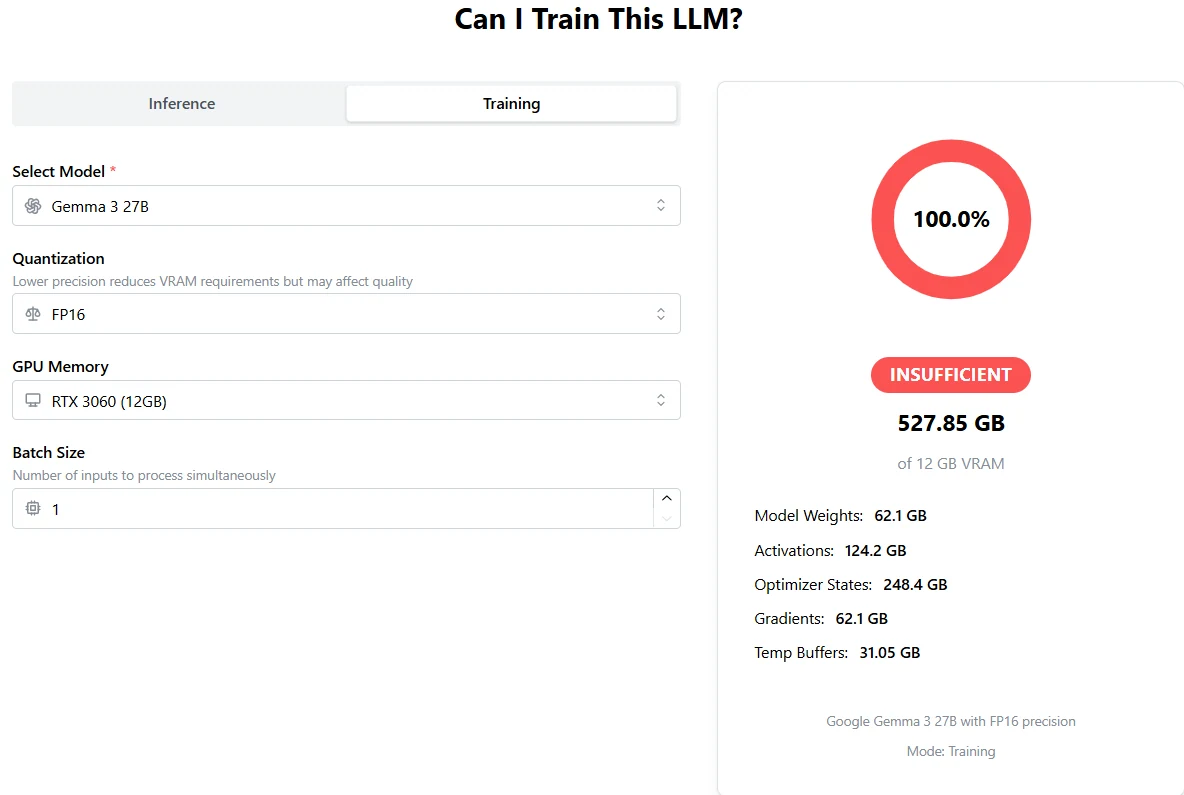
出典:APX
必要な総VRAM:527.85 GB
1基のH100は80GB(または96GB)しか提供せず、全く不十分 です。
試した場合に何が起こるか?
- すべてのデータをメモリに収められない: トレーニングにはモデルの重みだけでなく、活性化、オプティマイザ状態、勾配、一時バッファも必要です。これらを合わせると、1基のH100のVRAMをはるかに超えます。
- 即座にOOMエラー: メモリ不足のため、トレーニングプロセスは開始に失敗するか、すぐにクラッシュします。
- 高度な並列化が必要: 複雑な分散トレーニング手法(モデル並列、パイプライン並列、ZeRO、FSDPなど)を強制され、それでも1枚のカードでは動作しません。複数の高性能GPUを搭載したクラスタが必要です。
- パフォーマンスのボトルネック: メモリ最適化を行っても、1枚のカードでのトレーニングは非常に遅く、非現実的です。
よりコスト効率の高いアクセス方法:API
Novita AIは、開発者がシンプルなAPIを使ってAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドを構築とスケーリングに提供しています。
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2:無料トライアルを開始
選択したモデルの性能を試すために、無料トライアルを開始します。
ステップ3:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「Settings」ページに移動し、画像の指示に従ってAPIキーをコピーできます。

ステップ4:APIをインストール
使用するプログラミング言語に応じたパッケージマネージャを使用してAPIをインストールします。

インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してクライアントを初期化し、Novita AI LLMとの対話を開始します。以下はPythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Gemma 3 27Bは最先端のパフォーマンスと柔軟性を提供しますが、ローカルでのデプロイやトレーニングには重大なハードウェア上の課題が伴います。ほとんどのユーザーにとって、APIを活用することは、この強力なモデルをアプリケーションに統合するための、よりアクセスしやすくコスト効率の高い方法となります。
よくある質問
高価なハードウェアなしでGemma 3 27Bにアクセスするには?
クラウドAPI(Novita AIなど)を使用することが、Gemma 3 27Bをデプロイする最もコスト効率が高くスケーラブルな方法です。
Gemma 3 27Bはマルチモーダルですか?
はい、画像とテキストの両方の入力をサポートしています。
1基のH100 GPUでGemma 3 27Bをトレーニングできますか?
いいえ、トレーニングには500GB以上のVRAMが必要です。1基のH100(80GB/96GB)では全く不十分です。
Novita AIは、開発者がシンプルなAPIを使ってAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドを構築とスケーリングに提供しています。



