

Destaques
Gemma 3 27B é o mais recente modelo de linguagem grande de código aberto do Google com 27 bilhões de parâmetros, lançado em março de 2025.
Possui uma arquitetura avançada de atenção local-global intercalada e uma janela de contexto de até 128K tokens.
Multilíngue e multimodal: suporta mais de 140 idiomas e tarefas de imagem para texto.
Inferência possível em uma única GPU H100, mas o treinamento exige muito mais VRAM (mais de 500 GB).
O acesso por API oferece uma maneira econômica e escalável de usar o Gemma 3 27B sem preocupações com hardware, como a Novita AI.
O Gemma 3 27B é um modelo de linguagem grande de código aberto de ponta desenvolvido pelo Google. Com poderosas capacidades multilíngues e multimodais, ele é projetado para raciocínio avançado, geração de conteúdo e uso empresarial amplo.
O que é o Gemma 3 27B?
Visão geral do Gemma 3 27B
Principais recursos e inovações do mais recente modelo grande de código aberto
📅Informações Básicas
Data de lançamento: 12 de março de 2025
Tamanho do modelo: 27B parâmetros
Código aberto: Sim (Google)
🧠Arquitetura e Contexto
Arquitetura: Atenção Local-Global Intercalada
Janela de contexto: Até 128K tokens (modelo 1B: 32K)
Gerenciamento otimizado de memória: Aumento da taxa de atenção local/global e minimização da explosão do KV-cache reduzem significativamente a sobrecarga de memória.
Contexto mais longo e eficiência de memória para entrada e inferência em larga escala.
🌐Multimodal e Idiomas
Multilíngue: Suporta mais de 140 idiomas
Capacidade multimodal: Imagem para texto com codificador de visão SigLIP permite processamento eficiente de dados visuais.
Multimodal: Suporte a imagem para texto e multilíngue para cenários amplos.
⚡Desempenho e Treinamento
Desempenho aprimorado: A versão ajustada por instruções de 4B iguala o desempenho do Gemma 2 27B — mais eficiente em escala menor.
Dados de treinamento: 14 trilhões de tokens
Métodos de treinamento: Destilação de conhecimento, treinamento avançado consciente de quantização (QAT) e RLHF.
Destilação e QAT reduzem o uso de VRAM enquanto mantêm forte desempenho.
Benchmark do Gemma 3 27B
O Gemma 3 27B alcançou uma impressionante pontuação Elo de 1339 no LMSys Chatbot Arena, classificando-se entre os 10 principais modelos ao lado de concorrentes líderes de código fechado como o o3-mini. Notavelmente, o Gemma 3 27B oferece esse desempenho excepcional rodando em apenas uma única GPU NVIDIA H100 — um contraste gritante com outros modelos de sua classe.
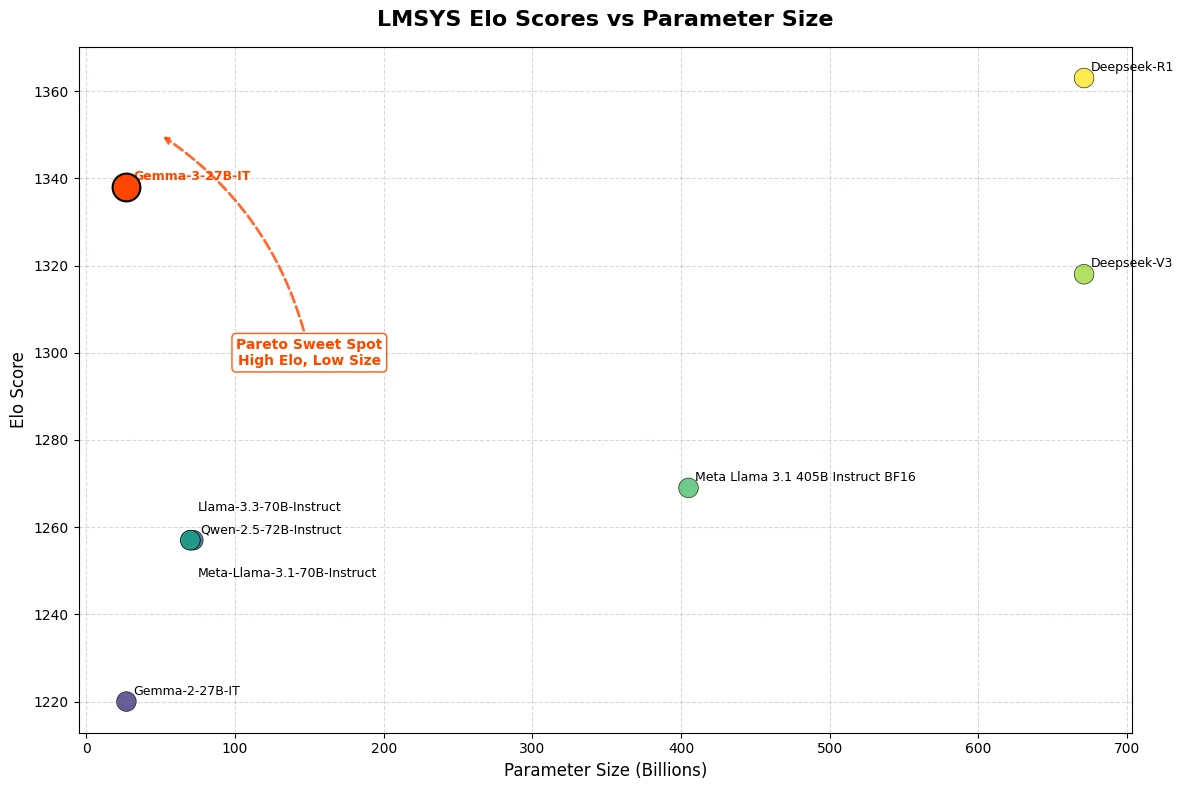
Do Hugging Face
A VRAM de uma Única H100 é Suficiente para o Gemma 3 27B?
Visão geral da VRAM
VRAM (Video Random Access Memory) é a memória dedicada em uma placa gráfica usada para armazenar dados de imagem, parâmetros de modelo, texturas e outras informações necessárias para tarefas de alto desempenho, como aprendizado profundo, renderização gráfica e processamento de vídeo.
O que realmente significa alta VRAM?
- Suporta modelos maiores: Permite carregar e executar modelos de redes neurais maiores com mais parâmetros ou entradas de resolução mais alta.
- Lida com tamanhos de lote maiores: Permite o uso de tamanhos de lote maiores durante o treinamento ou inferência, melhorando a taxa de transferência e a eficiência.
- Permite tarefas mais complexas: Torna possível executar cenas complexas, renderização de alta definição ou múltiplas tarefas paralelas sem encontrar limitações de memória.
- Reduz gargalos: Evita lentidão causada por transferências frequentes de dados entre a memória do sistema e a memória da GPU, resultando em melhor desempenho geral.
Quais são as necessidades de VRAM do Gemma 3 27B?
Requisitos de GPU e VRAM do Gemma 3
Gemma 3 1B
GPU recomendada: Nvidia T4
VRAM necessária: 16 GB+
Gemma 3 4B
GPU recomendada: Nvidia L4
VRAM necessária: 24 GB+
Gemma 3 12B
GPU recomendada: Nvidia L40S
VRAM necessária: 48 GB+
Gemma 3 27B
GPU recomendada: Nvidia A100
Considerações sobre armazenamento e rede
- Armazenamento: Embora um SSD de 500 GB seja o mínimo, recomenda-se um SSD NVMe de 1 TB ou maior para desempenho ideal e manuseio de grandes conjuntos de dados.
- Rede: Para implantações em nuvem e grandes transferências de dados, é aconselhável uma velocidade de rede de pelo menos 100 Mbps para evitar atrasos.
Limitações de Usar uma H100 para o Gemma 3 27B
1. Implantação (Inferência) em uma Única H100
Embora a NVIDIA H100 (80 GB ou 96 GB de VRAM) seja uma GPU de alto nível, implantar o Gemma 3 27B localmente em uma única placa traz desafios significativos:
- A VRAM é facilmente esgotada:
Apenas os pesos do modelo ocupam cerca de 62 GB. Quando você inclui caches de inferência, buffers temporários e tamanhos de lote ou comprimentos de sequência maiores, a memória acaba rapidamente — mesmo em uma H100. Erros de falta de memória (OOM) são prováveis se você tentar processar grandes entradas ou alta concorrência. - A escalabilidade é limitada:
Uma única GPU limita severamente sua capacidade de aumentar o tamanho dos lotes ou suportar vários usuários/solicitações. - Não é à prova de futuro:
À medida que suas necessidades crescem (por exemplo, entradas mais longas, mais usuários), uma única H100 não será suficiente.
Treinamento do Gemma 3 27B: Uma H100 está Longe de Ser Suficiente
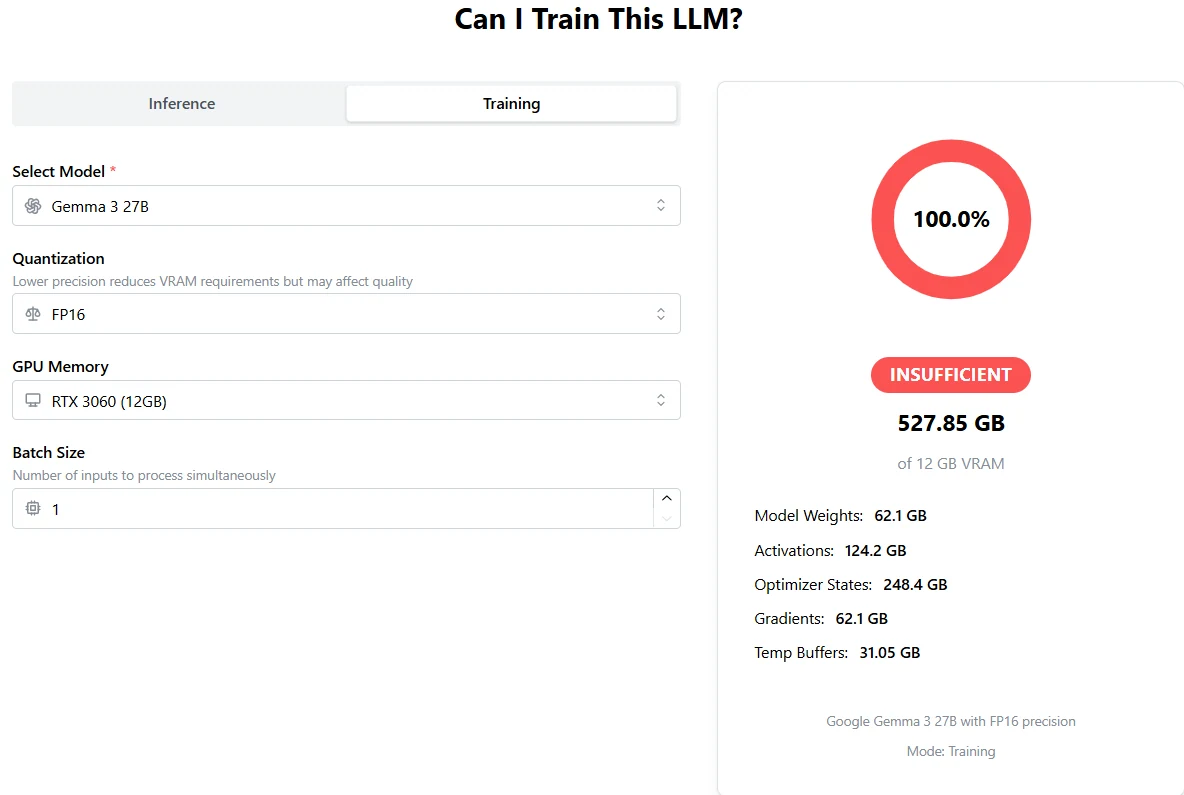
Do APX
VRAM total necessária: 527,85 GB
Uma única H100 oferece apenas 80 GB (ou 96 GB), o que não é nem de perto suficiente.
O que acontecerá se você tentar?
- Não é possível caber todos os dados na memória:
O treinamento exige não apenas os pesos do modelo, mas também ativações, estados do otimizador, gradientes e buffers temporários. A combinação disso excede em muito a VRAM de uma única H100. - Erros OOM imediatos:
O processo de treinamento falhará ao iniciar ou travará imediatamente devido à memória insuficiente. - Necessidade de paralelização avançada:
Você seria forçado a usar técnicas complexas de treinamento distribuído (paralelismo de modelo, paralelismo de pipeline, ZeRO, FSDP, etc.), e ainda assim, uma única placa não funcionará — você precisa de um cluster com várias GPUs de alto desempenho. - Gargalos de desempenho:
Mesmo com otimizações de memória, o treinamento em uma única placa seria extremamente lento e impraticável.
Um Método de Acesso Mais Econômico: API
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Experimente a demonstração do Gemma 3 27B agora!
Passo 2: Inicie Seu Teste Gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 3: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos a você uma nova chave de API. Entrando na página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 4: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Embora o Gemma 3 27B ofereça desempenho e flexibilidade de ponta, implantá-lo ou treiná-lo localmente apresenta desafios significativos de hardware. Para a maioria dos usuários, usar uma API oferece uma maneira mais acessível e econômica de integrar este poderoso modelo em aplicações.
Perguntas Frequentes
Como posso acessar o Gemma 3 27B sem hardware caro?
Usar uma API na nuvem (como a Novita AI) é a maneira mais econômica e escalável de implantar o Gemma 3 27B.
O Gemma 3 27B é multimodal?
Sim, ele suporta entradas de imagem e texto.
Posso treinar o Gemma 3 27B em uma única GPU H100?
Não, o treinamento exige mais de 500 GB de VRAM. Uma H100 (80 GB/96 GB) está longe de ser suficiente.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



