

Aspectos destacados
Gemma 3 27B es el último modelo de lenguaje grande de código abierto de Google con 27 mil millones de parámetros, lanzado en marzo de 2025.
Cuenta con una arquitectura avanzada de atención local-global intercalada y una ventana de contexto de hasta 128K tokens.
Multilingüe y multimodal: admite más de 140 idiomas y tareas de imagen a texto.
Es posible realizar inferencia en una sola GPU H100, pero el entrenamiento requiere mucha más VRAM (más de 500 GB).
El acceso mediante API brinda una forma rentable y escalable de usar Gemma 3 27B sin preocuparse por el hardware, como Novita AI.
Gemma 3 27B es un modelo de lenguaje grande de código abierto de última generación desarrollado por Google. Con potentes capacidades multilingües y multimodales, está diseñado para razonamiento avanzado, generación de contenido y uso empresarial amplio.
¿Qué es Gemma 3 27B?
Resumen de Gemma 3 27B
Características clave e innovaciones del último modelo grande de código abierto
📅Información básica
Fecha de lanzamiento: 12 de marzo de 2025
Tamaño del modelo: 27B parámetros
Código abierto: Sí (Google)
🧠Arquitectura y contexto
Arquitectura: Atención local-global intercalada
Ventana de contexto: Hasta 128K tokens (modelo 1B: 32K)
Gestión de memoria optimizada: Mayor proporción de atención local/global y minimización de la explosión de KV-cache reducen significativamente la sobrecarga de memoria.
Contexto más largo y eficiencia de memoria para entrada e inferencia a gran escala.
🌐Multimodal e idiomas
Multilingüe: Compatible con más de 140 idiomas
Capacidad multimodal: Imagen a texto con codificador visual SigLIP permite un procesamiento eficiente de datos visuales.
Multimodal: Imagen a texto y soporte multilingüe para escenarios amplios.
⚡Rendimiento y entrenamiento
Rendimiento mejorado: La versión ajustada por instrucciones de 4B iguala el rendimiento de Gemma 2 27B: más eficiente a menor escala.
Datos de entrenamiento: 14 billones de tokens
Métodos de entrenamiento: Destilación de conocimiento, entrenamiento avanzado consciente de cuantificación (QAT) y RLHF.
La destilación y QAT reducen el uso de VRAM mientras mantienen un alto rendimiento.
Puntos de referencia de Gemma 3 27B
Gemma 3 27B ha logrado una impresionante puntuación Elo de 1339 en el LMSys Chatbot Arena, ubicándose entre los 10 mejores modelos junto a competidores líderes de código cerrado como o3-mini. Cabe destacar que Gemma 3 27B ofrece este rendimiento excepcional funcionando con una sola GPU NVIDIA H100, en marcado contraste con otros modelos de su clase.
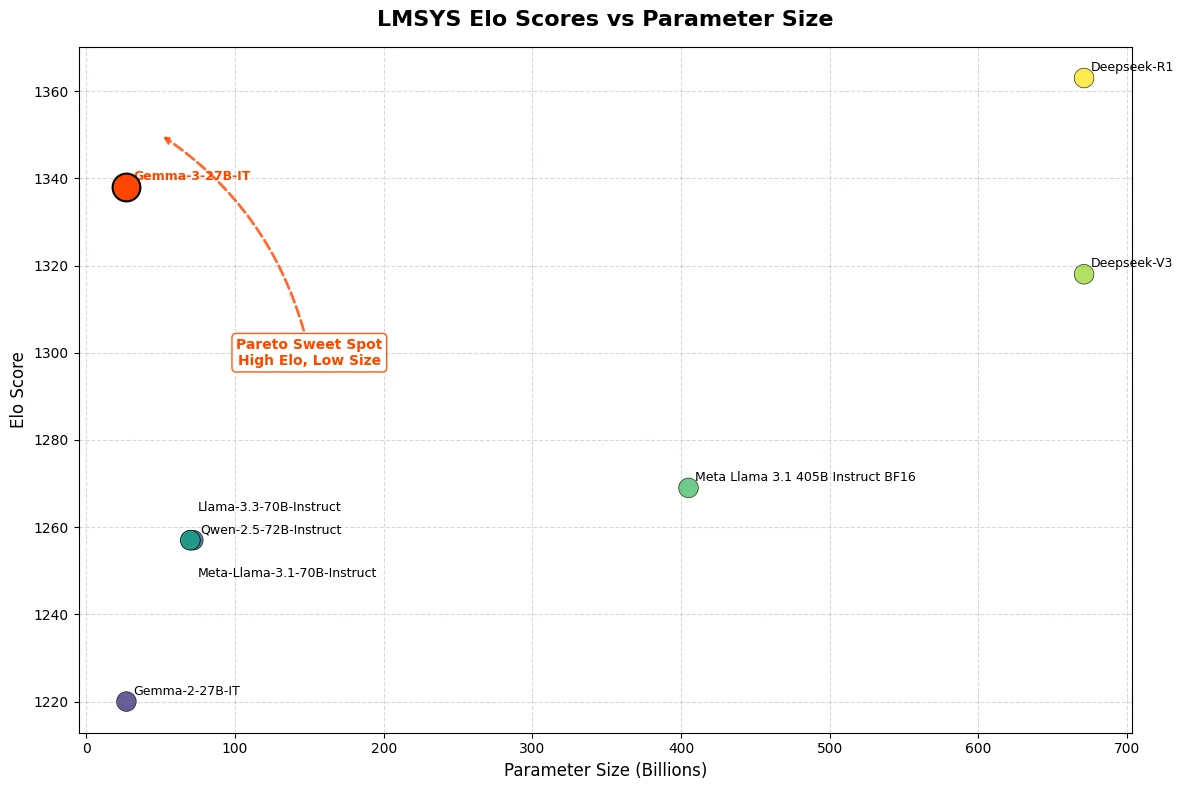
De Hugging Face
¿Es suficiente la VRAM de una sola H100 para Gemma 3 27B?
Resumen de VRAM
VRAM (memoria de acceso aleatorio de video) es la memoria dedicada en una tarjeta gráfica que se utiliza para almacenar datos de imagen, parámetros del modelo, texturas y otra información necesaria para tareas de alto rendimiento, como aprendizaje profundo, renderizado gráfico y procesamiento de video.
¿Qué significa realmente tener mucha VRAM?
- Soporta modelos más grandes: Permite cargar y ejecutar modelos de redes neuronales más grandes con más parámetros o entradas de mayor resolución.
- Maneja lotes de mayor tamaño: Permite usar tamaños de lote más grandes durante el entrenamiento o la inferencia, mejorando el rendimiento y la eficiencia.
- Habilita tareas más complejas: Posibilita ejecutar escenas complejas, renderizado de alta definición o múltiples tareas paralelas sin problemas de memoria.
- Reduce los cuellos de botella: Evita ralentizaciones causadas por transferencias frecuentes de datos entre la memoria del sistema y la memoria de la GPU, lo que resulta en un mejor rendimiento general.
¿Cuáles son las necesidades de VRAM de Gemma 3 27B?
Requisitos de GPU y VRAM de Gemma 3
Gemma 3 1B
GPU recomendada: Nvidia T4
VRAM necesaria: 16GB+
Gemma 3 4B
GPU recomendada: Nvidia L4
VRAM necesaria: 24GB+
Gemma 3 12B
GPU recomendada: Nvidia L40S
VRAM necesaria: 48GB+
Gemma 3 27B
GPU recomendada: Nvidia A100
Consideraciones de almacenamiento y red
- Almacenamiento: Aunque un SSD de 500 GB es el mínimo, se recomienda un SSD NVMe de 1 TB o más para un rendimiento óptimo y el manejo de grandes conjuntos de datos.
- Red: Para implementaciones en la nube y transferencias de datos grandes, se recomienda una velocidad de red de al menos 100 Mbps para evitar demoras.
Limitaciones de usar una H100 para Gemma 3 27B
1. Implementación (inferencia) en una sola H100
Aunque la NVIDIA H100 (80 GB o 96 GB de VRAM) es una GPU de primer nivel, implementar Gemma 3 27B localmente en una sola tarjeta presenta desafíos significativos:
- La VRAM se agota fácilmente:
Solo los pesos del modelo ocupan alrededor de 62 GB. Una vez que se incluyen cachés de inferencia, búferes temporales y tamaños de lote o longitudes de secuencia mayores, la memoria se agota rápidamente, incluso en una H100. Es probable que se produzcan errores de falta de memoria (OOM) si se procesan entradas grandes o alta concurrencia. - La escalabilidad es limitada:
Una sola GPU limita severamente la capacidad de escalar tamaños de lote o admitir múltiples usuarios/solicitudes. - No es preparado para el futuro:
A medida que crecen las necesidades (por ejemplo, entradas más largas, más usuarios), una sola H100 no será suficiente.
Entrenamiento de Gemma 3 27B: una H100 no es suficiente ni de lejos
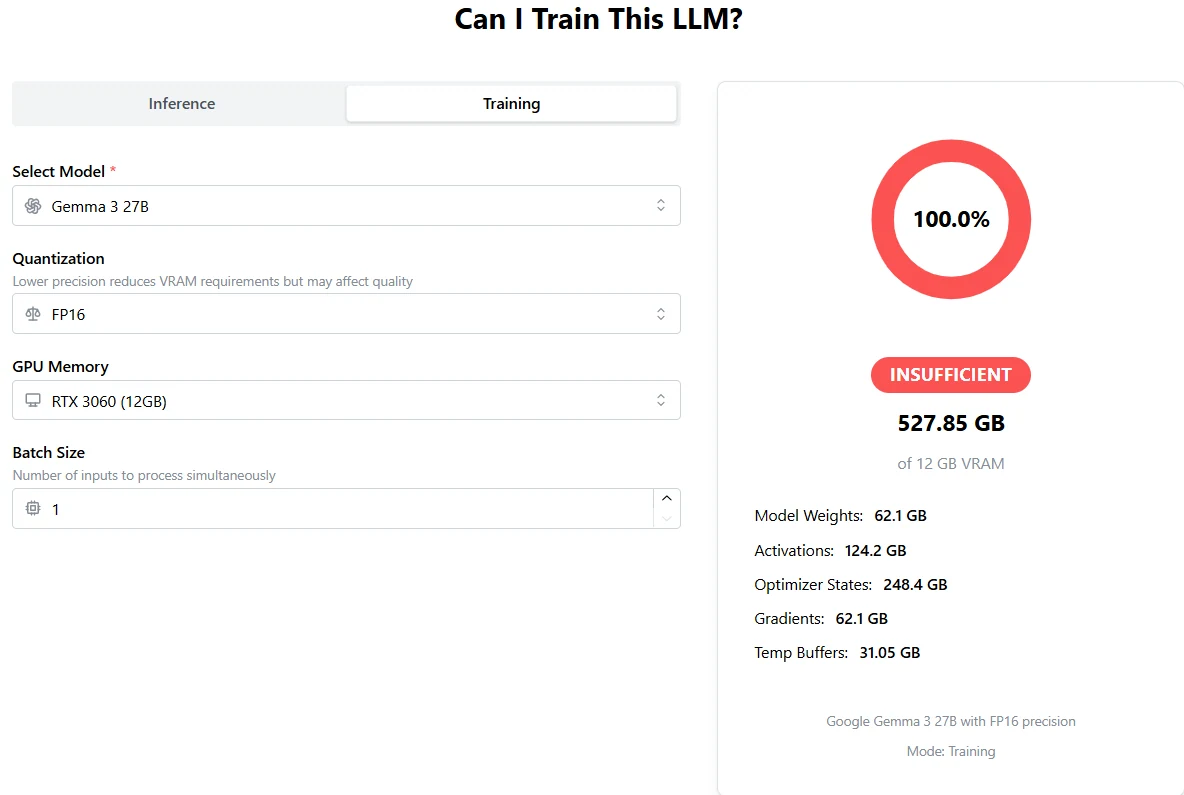
De APX
VRAM total necesaria: 527.85 GB
Una sola H100 ofrece solo 80 GB (o 96 GB), lo que no es suficiente ni de lejos.
¿Qué sucede si se intenta?
- No es posible cargar todos los datos en memoria:
El entrenamiento requiere no solo los pesos del modelo, sino también las activaciones, los estados del optimizador, los gradientes y los búferes temporales. La suma de todos ellos supera con creces la VRAM de una sola H100. - Errores OOM inmediatos:
El proceso de entrenamiento no podrá iniciarse o fallará de inmediato debido a memoria insuficiente. - Necesidad de paralelización avanzada:
Sería necesario utilizar técnicas complejas de entrenamiento distribuido (paralelismo de modelo, paralelismo de pipeline, ZeRO, FSDP, etc.), y aún así, una sola tarjeta no funcionaría; se necesita un clúster con varias GPU de alta gama. - Cuellos de botella de rendimiento:
Incluso con optimizaciones de memoria, el entrenamiento en una sola tarjeta sería extremadamente lento e inviable.
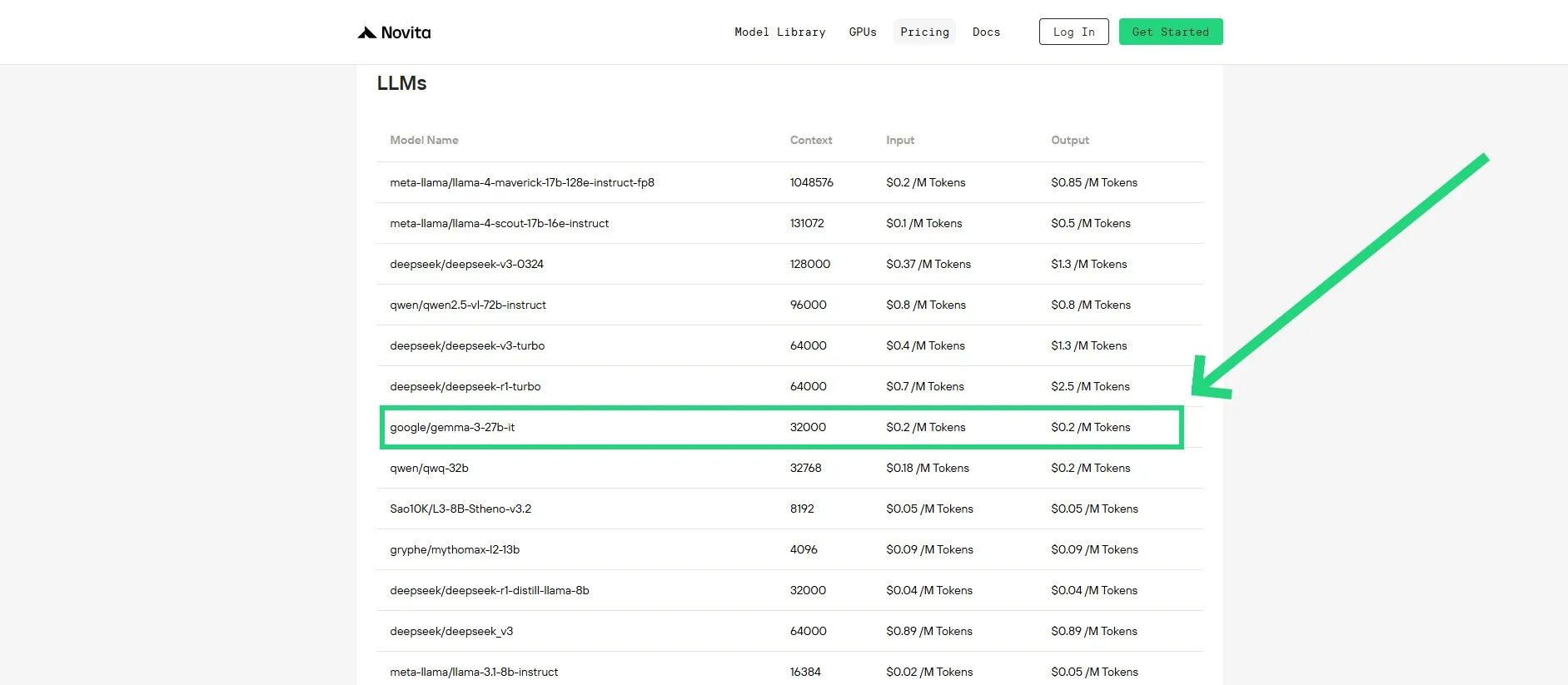
Un método de acceso más rentable: API
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una manera sencilla de implementar modelos de IA mediante nuestra API simple, al tiempo que proporciona una nube de GPU asequible y confiable para construir y escalar.
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

¡Prueba la demo de Gemma 3 27B ahora!
Paso 2: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 3: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Ingresa a la página de “Configuración” y copia la clave de API como se indica en la imagen.

Paso 4: Instala la API
Instala la API utilizando el administrador de paquetes específico de tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de finalización de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<TU CLAVE DE API DE Novita AI>",
)
model = "google/gemma-3-27b-it"
stream = True # o False
max_tokens = 2048
system_content = """Sé un asistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Si bien Gemma 3 27B ofrece un rendimiento y una flexibilidad de vanguardia, implementarlo o entrenarlo localmente conlleva desafíos de hardware significativos. Para la mayoría de los usuarios, usar una API ofrece una forma más accesible y rentable de integrar este potente modelo en sus aplicaciones.
Preguntas frecuentes
¿Cómo puedo acceder a Gemma 3 27B sin hardware costoso?
Usar una API en la nube (como Novita AI) es la forma más rentable y escalable de implementar Gemma 3 27B.
¿Es Gemma 3 27B multimodal?
Sí, admite entradas tanto de imagen como de texto.
¿Puedo entrenar Gemma 3 27B en una sola GPU H100?
No, el entrenamiento requiere más de 500 GB de VRAM. Una H100 (80 GB/96 GB) no es suficiente ni de lejos.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una manera sencilla de implementar modelos de IA mediante nuestra API simple, al tiempo que proporciona una nube de GPU asequible y confiable para construir y escalar.



